python 网页爬虫
我有个信息系统(网页版),
我想写个PY程序,读取出当前页面(10个人员)的所有相关信息; 写入excel文件中; 然后读取下一个页面,继续读取页面中10人的所有信息,存入excel文件中.
由于我刚刚接触Py ,很多不懂, 请各位牛人多多指点, 最好能附上PY代码.
想什么的呀,政府信息是不能随便爬取的,这不是你个人的网站,想搞诈骗的嘛
爬虫是个好东西,爬政府信息的,踩缝纫机都溜得飞起.
解决办法:建议手动复制网站上的信息下来,爬虫容易留下爬取的证据.
为何不直接在网页里写个导出excel的功能呢,非得用py
兄弟~如果你是问问题免费都有人回答,你让别人给写个完整代码的,这价格实属感人,大家又不傻。建议上淘宝找人做吧
【相关推荐】
- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/7787325
- 这篇博客你也可以参考下:初识机器学习前导内容_你需要知道的基本概念罗列_以PY为工具 【Python机器学习系列(一)】
- 您还可以看一下 王进老师的跟着王进老师学开发之Python篇第一季:基础入门篇课程中的 时间日期案例演示01小节, 巩固相关知识点
- 除此之外, 这篇博客: python基础——模块小知识、包、软件开发目录规范中的 2.判断py文件是执行文件还是被导入文件 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
#执行文件c.py import d print("我是执行文件") print(__name__)#被导入文件d.py print("我是被导入文件") print(__name__)
借用__name__可以将代码分割为导入与执行是可用以及仅执行可用。import d print("c.py在执行")print("我是d.py被导入或执行可运行的代码") if __name__ == '__main__': print("d.py在执行") print("我是仅被执行时触发的代码")执行c.py时,无法触发使用 name == ‘main’ 限制的代码

执行d.py时,可以触发使用 name == ‘main’ 限制的代码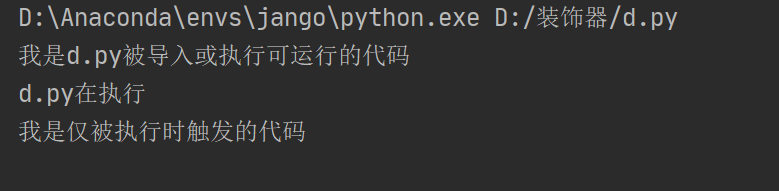
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^
我看你的网站是gov.cn结尾的,政府网站也敢爬吗,爬的还是真实信息
可以找到分页列表的数据接口,然后按照下面的方式将数据导出到excel中:https://blog.csdn.net/Haywardwang/article/details/112566259。
好像前几年有个新闻,有个哥们爬政府网站结果被抓了
建议别搞
纯技术上看,可以分析页面的td,tr等标签进行数据提取,然后写入execl,py都有现成的包可以用
太6了
老老实实的复制粘贴吧,或者偷偷的学习一下Python
不复杂
啥网站
这个是属于违法行为呀!
可以使用python的selenium或者request库实现。解析网页就行,网上找个教程自己就能学会。因为爬虫这种东西存在风险问题,如果出了事,写爬虫的人跑不了。