如何从键盘输入一个字符串(字符串不一定都是字母),将小写字母全部转换成大写字母,然后输出到一个磁盘文件”test”中保存?
从键盘输入一个字符串(字符串不一定都是字母),将小写字母全部转换成大写字母,然后输出到一个磁盘文件”test”中保存
哥们,你没说哪种语言,我就用java语言 了
import java.io.FileWriter;
import java.io.IOException;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.print("请输入字符串:");
String input = scanner.nextLine();
String upperCaseString = input.toUpperCase();
try {
FileWriter fileWriter = new FileWriter("test.txt");
fileWriter.write(upperCaseString);
fileWriter.close();
System.out.println("字符串已成功保存到文件test.txt");
} catch (IOException e) {
System.out.println("保存文件时出错:" + e.getMessage());
}
}
}
- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/7796148
- 除此之外, 这篇博客: 机器学习算法几种常见步骤(附项目案例)中的 创建test集 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
在创建test set的过程中, 能够进一步让我们了解数据,这对选择机器学习算法很有帮助。最简单的就是随机收取大约20%的数据作为test set。
使用随机函数的缺点是,每次运行程序得到的结果都不一样,因此,为处理这个问题,我们需要给每一行一个唯一的identifier,然后对identifier进行hash化,取它的最后一个字节值小于或等于51(20%)就可以了。
在原有的数据中,并不存在这样的identifier,因此需要调用**reset_index()函数,**为每行添加索引,作为identifier。
import hashlib import numpy as np def test_set_check(identifier, test_ratio, hash): return hash(np.int64(identifier)).digest()[-1] < 256 * test_ratio def split_train_test_by_id(data, test_ratio, id_column, hash=hashlib.md5): ids = data[id_column] in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio, hash)) return data.loc[~in_test_set], data.loc[in_test_set]# 给housing添加index housing_with_id = housing.reset_index() train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "index") print(len(train_set), 'train +', len(test_set), "test") # 也可以使用这种方式来创建id # housing_with_id["id"] = housing["longitude"] * 1000 + housing["latitude"] # train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "id")在上边的代码中,使用index作为identifier有一个缺点,需要把新的数据拼接到数据整体的最后边,同时不能删除中间的数据,解决的方法是,使用其他属性的组合来计算identifier。
当然sklearn也提供了生成test set的方法
from sklearn.model_selection import train_test_split train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)随机抽样比较适用于数据量大的样本,如果样本不够大,就会引入很大的抽样偏差。对于当前的数据,我们采取分层抽样。当你询问专家那个属性最重要的时候,他回答说median_income最重要,我们就要考虑基于median_income进行分层抽样。
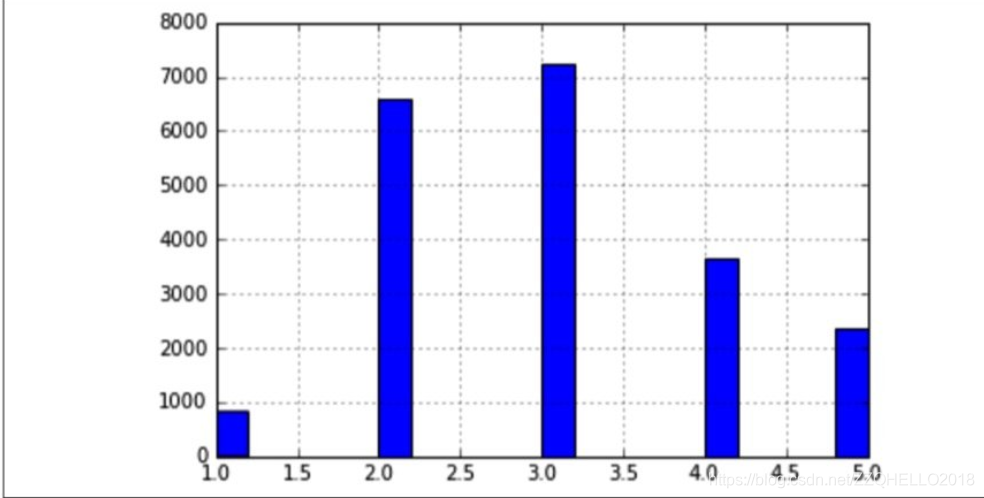
观察上图,可以发现,median_income的值主要集中在几个层次上,由于层次不够多,这也侧面说明了不太适合使用随机抽样。我们为数据新增一个属性,用于标记每行数据属于哪个层次。对于大于5.0的,都归到5.0中。
# 随机抽样会在某些情况下存在偏差,这时候可以考虑分层抽样,每层的实例个数不能太少,分层不能太多 housing["income_cat"] = np.ceil(housing["median_income"] / 1.5) housing["income_cat"].where(housing["income_cat"] < 5, 5.0, inplace=True) print(housing.head(10))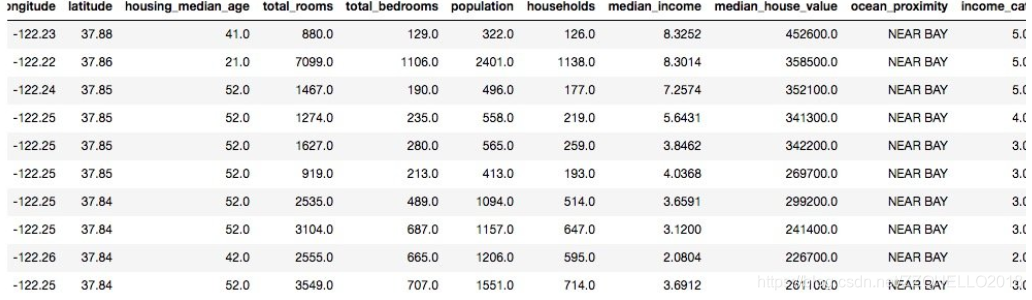
接下来就需要根据income_cat,使用sklearn对数据进行分层抽样。# 使用sklearn的tratifiedShuffleSplit类进行分层抽样 from sklearn.model_selection import StratifiedShuffleSplit split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42) for train_index, test_index in split.split(housing, housing["income_cat"]): strat_train_set = housing.loc[train_index] strat_test_set = housing.loc[test_index] print(housing["income_cat"].value_counts() / len(housing)) # 得到训练集和测试集后删除income_cat for s in (strat_train_set, strat_test_set): s.drop(["income_cat"], axis=1, inplace=True) print(strat_train_set.head(10))上边的代码在抽样成功后,删除了income_cat属性,结果如下:

如果我们计算test set和原数据的误差,能够得到下边这张表格,可以看出,分层抽样的错误明显小于随机抽样。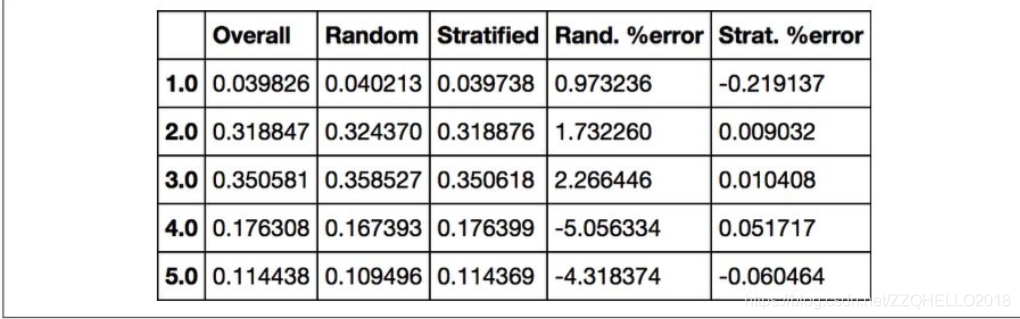
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^