关于爬虫xpath路径问题的请教
学习xpath实战 爬取网页部分标题信息 代码哪里有问题呢?谢谢!
图1是代码 图2是网页的element



这样就行了
import requests
from lxml import etree
url="https://jn.58.com/ershoufang/?PGTID=0d200001-0010-932d-eebf-37025ff5e65c&ClickID=1"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
res=requests.get(url,headers=headers)
html=etree.HTML(res.text)
title=html.xpath("//div[@class='property-content-title']//text()")
print(title)
- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/7476477
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:爬虫中xpath的返回空列表,xpath的长短和匹配问题
- 除此之外, 这篇博客: 关于爬虫中xpath返回为空的问题中的 关于爬虫中xpath返回为空的问题 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
测试环境:py3+win10,不同环境可能会有些许差异。
也是做个笔记吧,在爬取信息过程中,使用谷歌的xpath插件,是可以正常看到xpath返回的,网页内容返回也没有乱码,但在代码中使用xpath返回为空,这里的主要问题是tbody标签的问题,网页返回本身是没有这个标签(还是得仔细看),是浏览器规范html元素中加上的,所以xpath路径中使用tbody标签就返回空了。
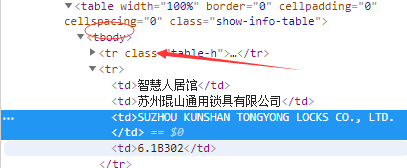
感谢博客园“沙漠的雨滴”关于这个问题的分享:
爬取网页
网页没啥反扒机制,直接上手就可以了。
http://shfair-cbd.no4e.com/portal/list/index/id/208.html?page=1代码如下:
import requests from lxml import etree import numpy as np import csv import time class BuildSpider(): def __init__(self,csv_name): self.csv_headers = ['类型','企业中文名','companyname','展位'] self.start_url = 'http://shfair-cbd.no4e.com/portal/list/index/id/208.html?page={}' self.headers = [{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"}, {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"}, {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.7 Safari/537.36'} ] self.csv_name = csv_name def get_table_content(self,table_info): table_list = [] for each_sample in table_info: sample_info = each_sample.xpath("./td") temp_list = [] for each in sample_info: every_range = each.xpath("./text()") if len(every_range) == 0: every_range = '' else: every_range = every_range[0] temp_list.append(every_range) table_list.append(temp_list) return table_list def run(self): page = 1 with open(self.csv_name,'w',encoding='utf_8_sig',newline='') as f: writer = csv.writer(f) writer.writerow(self.csv_headers) while True: url = self.start_url.format(page) response = requests.get(url,headers=self.headers[np.random.randint(len(self.headers))]) content = response.content.decode() tree = etree.HTML(content) table_info = tree.xpath("//tr[position()<last() and position()>1]") table_values = self.get_table_content(table_info) writer.writerows(table_values) print('正在写入第{}页,当前访问url为:{}'.format(page,url)) print('当前写入内容为:{}'.format(table_values)) time.sleep(1+np.random.random()) if len(tree.xpath("//div/li[last()]/a/@href")) == 0: print('所有内容已经抓取完毕~~') break page += 1 if __name__ == '__main__': m = BuildSpider('d:/Desktop/test.csv') m.run()注意事项:
- xpath是从网页返回内容里边去提取的,网页返回的content和浏览器的element可能会有差异,当xpath无法正常提取内容时,我们首先可以将网页请求返回内容保存到本地在顺着xpath路径查看原因。
- 您还可以看一下 CSDN就业班老师的第一章:数据提取与清洗策略课程中的 百度针对xpath爬虫的反爬策略与解决方式小节, 巩固相关知识点
- 以下回答由chatgpt基于相关博客总结生成:
问题:在编写的代码中存在哪些问题?
回答:根据问题描述,提供的参考资料和代码,可以看出以下问题和建议:
缺少必要的导入语句:代码中没有导入必要的模块和库,例如requests和parsel。
引用的xpath路径不正确:代码中使用的xpath路径可能不正确,导致无法获取到目标数据。
页面结构变化:根据参考资料段落2的描述,网页在爬虫过程中解析不到数据可能是因为页面结构变化,特别是添加了tbody子结构,导致xpath无法准确匹配到目标数据。
没有定义函数和类:代码缺少定义函数和类的结构,可能导致功能无法完整实现和复用。
没有异常处理:代码中没有对网络请求和解析数据的过程进行异常处理,可能导致程序崩溃或无法正常运行。
综合以上问题和建议,下面给出具体解决方案和修改后的代码:
import requests import parsel from lxml import etree def get_titles(): url = 'http://epaper.qjrb.cn/html/2021-06/09/node_2.htm' try: r = requests.get(url) r.encoding = 'utf-8' html_data = r.text selector = parsel.Selector(html_data) # 抓取标题,在类class="default1"中的<a标签里面。 titles = selector.xpath('//tr[@class="default1"]//td[2]/a/text()').getall() return titles except requests.exceptions.RequestException as e: print("Error: ", e) return [] titles = get_titles() for title in titles: print(title)根据以上解决方案修改了代码,主要包括以下改动:
添加了必要的导入语句:引入了requests、parsel和lxml.etree模块。
修正了xpath路径:在xpath路径中去掉了不必要的".",并将获取多个标题的语句修改为
titles = selector.xpath('//tr[@class="default1"]//td[2]/a/text()').getall()。添加了异常处理:在网络请求和解析数据的过程中加入了异常处理,当出现异常时打印错误信息并返回一个空列表。
通过以上改动,代码将可以正确获取指定网页中类为"class=default1"的tr元素下的td子元素中的a标签的文本内容,并将其打印输出。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^