python 企业微信 文档操作
现在想将桌面Excel文件的数据,写入到企业微信的文档中,在企业微信的文档中也有一个Excel表格的文档,怎么使用python代码实现,每次桌面的Excel文件数据更新,就随着更新到企业微信中
- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/7623002
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:使用Python解决对比出两个Excel文件中的不同项并将结果重新写入一个新的Excel文件
- 除此之外, 这篇博客: 用python绘制蒙特卡洛模拟数据折线图中的 研究蒙特卡洛模拟算法,在excel中模拟出了数据变量,需要绘图的时候,excel会卡死,借助python绘图。 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
参考如下教程:
python使用matplotlib绘制折线图教程
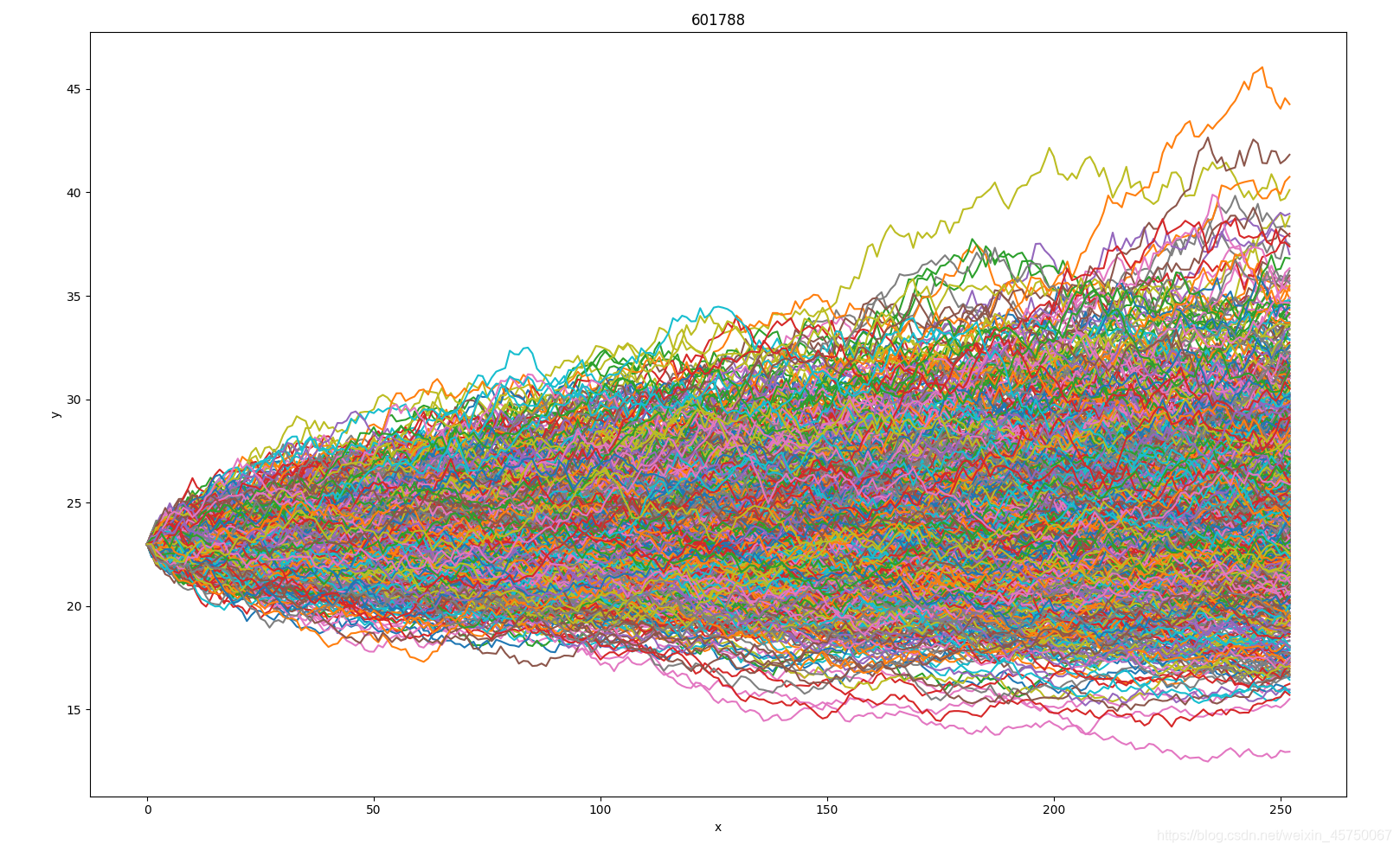
https://www.cnblogs.com/onemorepoint/p/7482644.html没找到上传excel附件的位置,把图片贴出来对数据做一个说明:
第1行为X周,是时间单位,由于是相对时间,所以直接用数字代替
第1列是模拟的次数,总共1000次,每个单元格中的数值为X所对应的y值。
根据以上教程修改后的代码如下:
import matplotlib.pyplot as plt import xlrd y=[[] for i in range(0,999)] workbook=xlrd.open_workbook(r'.\file\price.xlsx') sheet=workbook.sheets()[0] #取每一行数据为y值 for i in (range(0,999)): y[i] = sheet.row_values(i+1) #取第一行数据作为x坐标轴 x = sheet.row_values(0) for i in (range(0,999)): plt.plot(x[1:],y[i][1:]) plt.title('line chart') plt.xlabel('x') plt.ylabel('y') plt.show()运行结果如下:
- 您还可以看一下 裴帅帅老师的Python操作Excel实战办公自动化课程中的 Python给学生随机分配考号小节, 巩固相关知识点
- 以下回答由chatgpt基于相关博客总结生成:
对于问题中的需求,可以使用以下步骤来实现:
- 导入所需的库:
import pandas as pd import os from openpyxl import load_workbook, Workbook- 检查Excel文件是否存在,并加载文件:
filename = 'path/to/excel/file.xlsx' # 替换为实际的Excel文件路径 if os.path.exists(filename): workbook = load_workbook(filename) else: workbook = Workbook()- 读取Excel文件中的数据并进行必要的处理:
# 获取需要的表格 sheet = workbook['Sheet1'] # 进行数据的筛选和部分内容的修改 df = pd.read_excel(filename, usecols=['city', 'data', 'info']) df = df[~df['info'].str.contains('河北|河南')] # 将‘info’列中包含有河北或者河南的行去掉 # 修改列名和重新排序索引 df.rename(columns={'city': 'contrary'}, inplace=True) # 将city列名改为contrary df.reset_index(drop=True, inplace=True) # 重新进行索引值排序 # 去除指定列中重复行 df.drop_duplicates(subset='contrary', keep='first', inplace=True) # 将contrary列中有重复的整行去除- 创建新的Excel文件,并将处理后的数据保存到新文件中:
new_filename = 'path/to/new/excel/file.xlsx' # 替换为保存新Excel文件的路径 with pd.ExcelWriter(new_filename) as writer: df.to_excel(writer, index=False, sheet_name='Sheet1')- 将新文件上传到企业微信的文档中: 这一步需要参考企业微信的文档接口和使用相应的Python库来实现,具体的步骤会根据企业微信的接口要求有所不同。你可以参考企业微信的相关文档和使用相应的Python库进行开发。
请注意,上述代码只提供了将Excel文件的数据处理并保存为新文件的示例,具体上传到企业微信的文档中需要根据企业微信的接口要求和Python库来进行实现。