python程序无反应
用python爬取网页里的文献,通过关键字筛选,然后下载到指定文件夹里
运行后无反应,要怎么修改才行
import requests
from bs4 import BeautifulSoup
import os
# 定义要爬取的页面URL
url = 'https://sc.panda321.com/scholar?start=10&q=insulin+resistance&hl=zh-CN&as_sdt=0,5' # 替换为实际网页的URL
keyword = 'insulin' # 替换为实际的关键字
save_folder = 'E:\生物11' # 替换为实际的文件夹路径
# 创建保存文件夹(如果不存在)
if not os.path.exists(save_folder):
os.makedirs(save_folder)
# 发起GET请求获取页面内容
response = requests.get(url)
html = response.text
# 使用BeautifulSoup解析页面
soup = BeautifulSoup(html, 'html.parser')
# 定位到文献列表的HTML元素
doc_list = soup.find_all('a', class_='doc-link')
# 遍历文献列表
for doc in doc_list:
# 提取文献链接和标题
doc_url = doc['href']
doc_title = doc.text.strip()
# 判断关键字是否在文献标题中
if keyword in doc_title:
# 下载文献并保存到指定文件夹
print('正在下载文献:', doc_title)
try:
response = requests.get(doc_url)
with open(os.path.join(save_folder, doc_title + '.pdf'), 'wb') as file:
file.write(response.content)
print('下载完成')
except Exception as e:
print('下载失败:', str(e))
根据你描述的问题,主要的原因可能有以下几点:
- 爬取网页时被网站检测并阻止了请求。可以添加一些头信息来模拟浏览器请求,避免被检测出是爬虫。
- 爬取的数据量太大,导致代码卡在网络请求或文件保存的时候。可以适当减少爬取的数据量,或者使用多线程来加速。
- 存在无限循环或递归调用,导致代码无法正常退出。检查代码逻辑,确保没有无限循环。
- 文件保存路径错误,导致无法成功保存文件。检查保存文件夹是否存在,是否有写权限。
- 部分网页需要JavaScript渲染,BeautifulSoup无法解析。可以尝试使用Selenium来获取渲染后的页面源码。
- 代码逻辑错误导致中间出现异常,但是没有捕获和处理。可以加上try-except来捕获并处理异常。
- 其他第三方模块问题,例如requests、BeautifulSoup等安装不正确或版本不兼容。检查环境依赖并更新到最新版本。
建议先打印爬取过程的关键节点信息,定位问题出现的阶段;添加日志记录,在发生异常时打印错误信息;逐步测试并隔离问题代码,最后能找出具体的原因。
没反应是啥意思。错误信息有吗
- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/7782206
- 这篇博客你也可以参考下:python遍历某目录的下级目录,并查找指定类型文件,复制到指定文件夹
- 你还可以看下python参考手册中的 python- 位置或关键字参数
- 除此之外, 这篇博客: python实现链表的反转中的 python里面是没有链表这个概念的,所以我们需要自己构造一个链表,然后再实现链表的反转; 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
这是老师上课讲的图解,仅供参考,应该是看不懂的
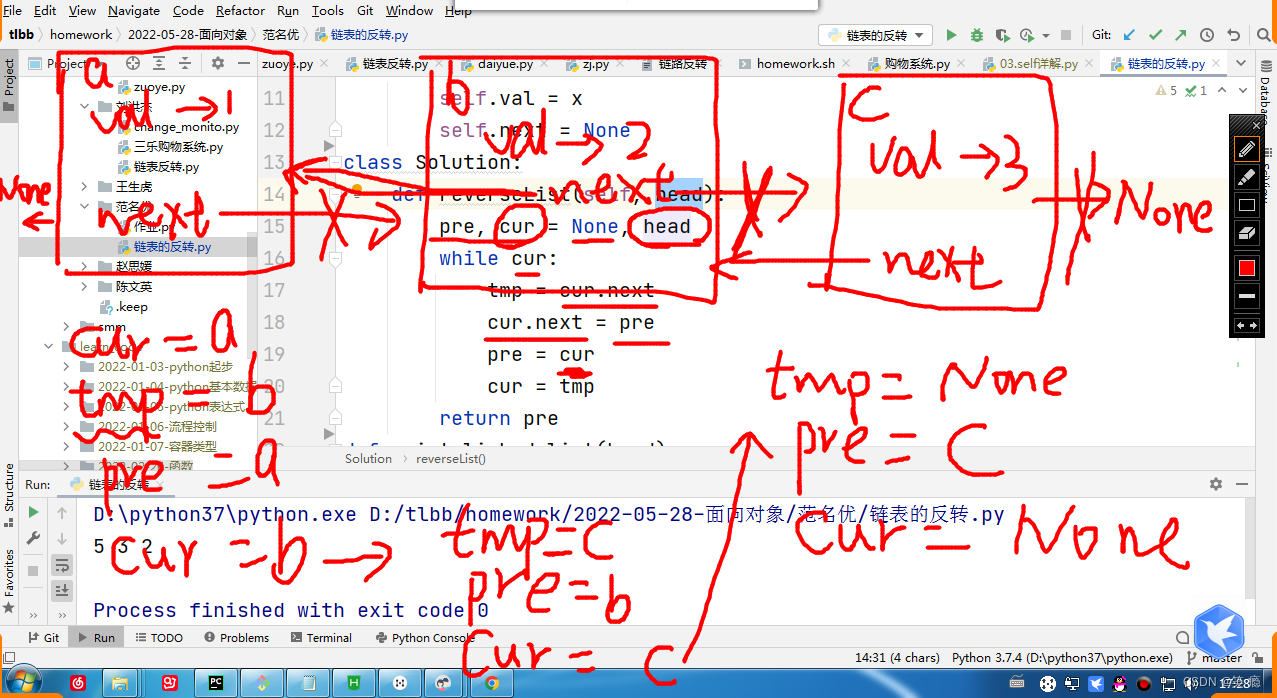
具体代码实现
""" @version: @filename : 链表反转 @author : liuhongjie @projectname: day02 @time: 2022/05/30 """ #定义一个节点类,用来等一下实现链表的创建 class ListNode: def __init__(self, x): self.val = x self.next = None class Solution: #实现链表的反转 def reverseList(self, head): pre, cur = None, head while cur: tmp = cur.next cur.next = pre pre = cur cur = tmp return pre #把反转以后的链表打印出来 def print_linked_list(head): if not head or not head.next: return [] result = [] while head: result.append(head.val) head = head.next return result # 调用节点类,创建一个链表: a->b->c,分别对应的就是:1,2,3 a = ListNode(1) b = ListNode(2) c = ListNode(3) a.next = b b.next = c #创建一个实例化对象 demo = Solution() print(print_linked_list(demo.reverseList(a)))- 您还可以看一下 jeevan老师的Python量化交易,大操手量化投资系列课程之内功修炼篇课程中的 编程语言之Python环境安装小节, 巩固相关知识点