大数据、数据统计mysql字段统计
需求:做个列表把数据库10张表的字段名都查出来,并查出所有字段为空的占有率是多少,Java开发的 数据库mysql ,一张表10个字段算,10张表100个字段,这个写sql感觉效率很低,也没有什么思路,帮忙出个思路
字段名 数据类型 占有率
name 文本 10%
import java.sql.*;
public class DatabaseAnalyzer {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/database_name";
String username = "username";
String password = "password";
try (Connection connection = DriverManager.getConnection(url, username, password)) {
DatabaseMetaData metaData = connection.getMetaData();
ResultSet tablesResultSet = metaData.getTables(null, null, null, new String[]{"TABLE"});
while (tablesResultSet.next()) {
String tableName = tablesResultSet.getString("TABLE_NAME");
System.out.println("Table: " + tableName);
ResultSet columnsResultSet = metaData.getColumns(null, null, tableName, null);
while (columnsResultSet.next()) {
String columnName = columnsResultSet.getString("COLUMN_NAME");
String dataType = columnsResultSet.getString("TYPE_NAME");
int totalRecords = 0;
int emptyRecords = 0;
try (Statement statement = connection.createStatement()) {
String countQuery = "SELECT COUNT(*) AS total, COUNT(" + columnName + ") AS empty FROM " + tableName + " WHERE " + columnName + " IS NULL";
ResultSet countResultSet = statement.executeQuery(countQuery);
if (countResultSet.next()) {
totalRecords = countResultSet.getInt("total");
emptyRecords = countResultSet.getInt("empty");
}
}
double occupancyRate = (double) emptyRecords / totalRecords * 100;
System.out.println("Column: " + columnName + ", Data Type: " + dataType + ", Occupancy Rate: " + occupancyRate + "%");
}
System.out.println();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
pyspark 了解一下啊
不知道你这个问题是否已经解决, 如果还没有解决的话:- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/232477
- 这篇博客也不错, 你可以看下java往mysql中插入10万条数据或者100万条数据
- 除此之外, 这篇博客: 你如何理解mysql读写分离和分库分表?,java实用教程第五版课后答案中的 如何实现读写分离? 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
不论是使用哪一种读写分离具体的实现方案,想要实现读写分离一般包含如下几步:
部署多台数据库,选择一种的一台作为主数据库,其他的一台或者多台作为从数据库。
保证主数据库和从数据库之间的数据是实时同步的,这个过程也就是我们常说的主从复制。
系统将写请求交给主数据库处理,读请求交给从数据库处理。
落实到项目本身的话,常用的方式有两种:
1.代理方式
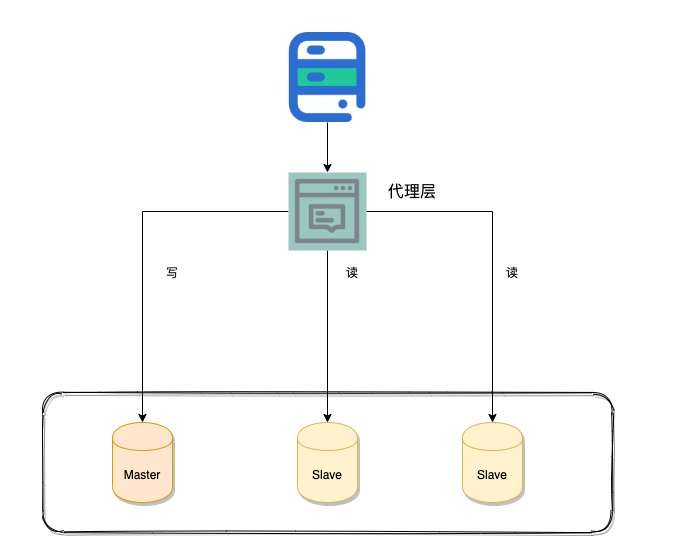
我们可以在应用和数据中间加了一个代理层。应用程序所有的数据请求都交给代理层处理,代理层负责分离读写请求,将它们路由到对应的数据库中。
提供类似功能的中间件有 MySQL Router(官方)、Atlas(基于 MySQL Proxy)、Maxscale、MyCat。
2.组件方式
在这种方式中,我们可以通过引入第三方组件来帮助我们读写请求。
这也是我比较推荐的一种方式。这种方式目前在各种互联网公司中用的最多的,相关的实际的案例也非常多。如果你要采用这种方式的话,推荐使用
sharding-jdbc,直接引入 jar 包即可使用,非常方便。同时,也节省了很多运维的成本。你可以在 shardingsphere 官方找到
sharding-jdbc 关于读写分离的操作。 - 您还可以看一下 孙老师老师的数据分析师必备Mysql实践应用课程中的 10修改表插入数据2小节, 巩固相关知识点
- 以下回答来自chatgpt:
解决方案
为了查询MySQL数据库中多张表字段为空的占有率,我们可以使用Java编写代码来执行SQL语句并处理查询结果。下面是解决问题的大致步骤:
- 配置数据库连接:首先,需要在Java项目中配置数据库连接,包括数据库的URL、用户名和密码等信息。一种常用的方式是使用JDBC连接数据库,可以通过引入合适的JDBC驱动程序来实现。
```java import java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLException;
public class DatabaseConnection { private static final String URL = "jdbc:mysql://localhost:3306/database_name"; private static final String USERNAME = "username"; private static final String PASSWORD = "password";
public static Connection getConnection() throws SQLException { return DriverManager.getConnection(URL, USERNAME, PASSWORD); }} ```
- 编写SQL查询语句:根据问题描述中的需求,我们需要查询10张表的字段名,并计算出字段为空的占有率。我们可以使用
SELECT语句联结所有这些表并使用COUNT()和SUM()函数来计算占有率。
java SELECT table_name, column_name, SUM(CASE WHEN column_name IS NULL THEN 1 ELSE 0 END) / COUNT(*) AS rate FROM information_schema.columns WHERE table_schema = 'database_name' GROUP BY table_name, column_name;请将
database_name替换为你实际的数据库名称。- 执行SQL查询:利用前面步骤中的数据库连接,我们可以在Java代码中执行SQL查询语句。
```java import java.sql.Connection; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.SQLException;
public class Main { public static void main(String[] args) { String sql = "SELECT table_name, column_name, " + "SUM(CASE WHEN column_name IS NULL THEN 1 ELSE 0 END) / COUNT(*) AS rate " + "FROM information_schema.columns " + "WHERE table_schema = 'database_name' " + "GROUP BY table_name, column_name";
try (Connection connection = DatabaseConnection.getConnection(); PreparedStatement statement = connection.prepareStatement(sql); ResultSet resultSet = statement.executeQuery()) { while (resultSet.next()) { String tableName = resultSet.getString("table_name"); String columnName = resultSet.getString("column_name"); double nullRate = resultSet.getDouble("rate"); System.out.println("TableName: " + tableName + ", ColumnName: " + columnName + ", NullRate: " + nullRate); } } catch (SQLException e) { e.printStackTrace(); } }} ```
请将
database_name替换为你实际的数据库名称。- 执行代码并获取查询结果:运行代码,将会执行SQL查询并输出每个表字段为空的占有率。
这是一个大致的解决方案,可以帮助你实现查询MySQL数据库中多张表字段为空的占有率。请根据实际情况对代码进行相应的修改,并确保数据库连接的正确性。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^