想学习一下模型训练,有没有能跑的例子
请问有么有实战项目,就是安装了python环境后立即能跑的,谢谢~
- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/7524254
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:自然语言处理爬过的坑:使用python结巴对中文分词并且进行过滤,建立停用词。常见的中文停用词表大全
- 同时,你还可以查看手册:python- 预定义的清理操作 中的内容
- 除此之外, 这篇博客: 【笔试】python刷题笔记(基础)!中的 输出字符串排序的不同方法,每个方法一个组合,集合成一个非常规对象,有重复的 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
import itertools class Solution: def Permutation(self, ss): # write code here if not ss: return [] return sorted(list(set(map(''.join, itertools.permutations(ss))))) #map(''.join,A) 转化为字符串组成的对象 #set() 返回无重复元素集,降重;可以看作不能重复的集合,也可看做set()对象。 #list() 转化为列表 #sorted() 排序d={} numbers=[1,1,2,2,2,3,3,3] for i in numbers: try: dict[i]+=1 except: dict[i]=1a={1:2,3:4,5:1} b=dict(sorted(a.items(),key=lambda b:b[1])) print(b)try: fun() do something1 expect: do something2while True: try: a=sys.stdin.readline().strip() if not a: break fun() except: break#sort()改变了a,且不能赋值给b。 a=[1,4,3,2] a.sort() print(a) #sorted()未改变a,改变后的对象赋值给b。 a=[1,4,3,2] b=sorted(a) print(a,b)s.find('a'):返回s中a的最小索引
s.rfind('a'):返回s中a的最大索引
list.index(a):返回list中a的最小索引
import collections d = collections.OrderedDict() #有序字典(输出顺序与添加顺序有关//无序字典无关) a = collections.Counter(b) #计数器,Counter类型,加dict变成计数字典在对问题求解时,总是作出在当前看来是最好的选择。(一件事情分为很多步,每步都做最好的选择)(局部最优>>全局最优,必须无后效性)
每次决策依赖于当前状态,又随即引起 ‘状态的转移’。一个‘决策序列’就是在变化的状态中产生出来的,所以,这种多阶段最优化决策解决问题的过程就称为动态规划。(经分解后得到的子问题往往不是互相独立的,即下一个子阶段的求解是建立在上一个子阶段的解的基础上,进行进一步的求解)
分治法的设计思想是:将一个难以直接解决的大问题,分割成一些规模较小的相同问题,以便各个击破,分而治之。
(回溯法=DFS+剪枝)
在包含问题的所有解的解空间树中,按照深度优先搜索的策略,从根结点出发深度探索解空间树。当探索到某一结点时,要先判断该结点是否包含问题的解,如果包含,就从该结点出发继续探索下去,如果该结点不包含问题的解,则逐层向其祖先结点回溯。(其实回溯法就是对隐式图的深度优先搜索算法)。
类似于回溯法,也是一种在问题的解空间树T上搜索问题解的算法。但在一般情况下,分支限界法与回溯法的求解目标不同。回溯法的求解目标是找出T中满足约束条件的所有解,而分支限界法的求解目标则是找出满足约束条件的一个解,或是在满足约束条件的解中找出使某一目标函数值达到极大或极小的解,即在某种意义下的最优解。
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表或哈希表。具体表现为: 存储位置 = f(key)


一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
#遍历每个结点,借助一个获取树深度的递归函数,根据该结点的左右子树高度差判断是否平衡,然后递归地对左右子树进行判断。 class Solution: def IsBalanced_Solution(self, pRoot): # write code here if pRoot == None: return True if abs(self.TreeDepth(pRoot.left)-self.TreeDepth(pRoot.right)) > 1: return False return self.IsBalanced_Solution(pRoot.left) and self.IsBalanced_Solution(pRoot.right) def TreeDepth(self, pRoot): #计算树的深度 # write code here if pRoot == None: return 0 nLeft = self.TreeDepth(pRoot.left) #左子树的深度 nRight = self.TreeDepth(pRoot.right) return max(nLeft+1,nRight+1)
str.join(sequence)open()函数打开txt文件,返回 ‘file’ 类型;
file.readline( )方法 按照每一行划分,返回字符串组成的列表。
file = open('validation.txt','r') number_list=file.readlines() for i in range(len(number_list)): number_list[i]=number_list[i].strip() print(number_list)a=os.listdir('velodyne/') #参数为路径,后面要有‘/’ print(a)shutil.move(src_path+number+'.bin',target_path+number+'.bin') #文件名
最大堆:每个节点的值都大于等于它的孩子节点。
最小堆:每个节点的值都小于等于它的孩子节点。 对于下标为i的节点,它的子树的左节点的下标为2i,右节点为2i+1,父亲的节点下标为i/2(向下取整)。



看快慢指针是否相遇。
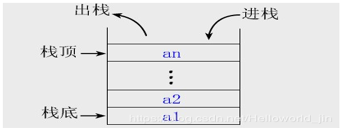
栈可以实现;递归需要保存正在计算的上下文, 等待当前计算完成后弹出,再继续计算, 只有栈先进后出的特性才能实现。
情况A: 路径经过左子树的最深节点,通过根节点,再到右子树的最深节点。
情况B: 路径不穿过根节点,而是左子树或右子树的最大距离路径,取其大者。 只需要计算这两个情况的路径距离,并取其大者,就是该二叉树的最大距离。




- 您还可以看一下 Toby老师的python机器学习-乳腺癌细胞挖掘课程中的 如何创建python虚拟编程环境-避免项目包版本冲突(选修)小节, 巩固相关知识点