python抓取弹幕出现乱码怎么解决
python抓取弹幕时全部繁体字乱码,抓取时还不是乱码,抓取之后显示乱码

这个问题可能是由于编码问题导致的。在抓取弹幕时,你需要确保将抓取到的文本以正确的编码方式保存下来,以避免乱码问题。
在 Python 中,你可以使用 encode() 方法将文本编码为指定的编码方式,然后使用 decode() 方法将编码后的文本解码为字符串。
设置编码形式
response.encoding = "utf-8" # 设置编码方式为 UTF-8
这种情况一般都是由于编码问题导致的,建议你检查以下几点问题
1、抓取的弹幕内容的编码格式与存储内容的编码格式不一致。
2、存储内容时未指定编码格式,Python 默认使用 ASCII 编码。
3、读取存储内容时未指定正确的编码格式。
4、系统默认编码与存储内容编码不一致。
一般是编码问题。不过弹幕 有的弹幕功能强大可以带表情 ,可能也是 乱码。不过你这个都是乱码,应该就是编码问题
response_text = response.content.decode('utf-8')
请求头 也设置一下
import requests
headers = {
'Content-Type': 'text/html; charset=utf-8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=headers)
- 帮你找了个相似的问题, 你可以看下: https://ask.csdn.net/questions/7685201
- 这篇博客也不错, 你可以看下python爬虫爬取异步加载网页信息(python抓取网页中无法通过网页标签属性抓取的内容)
- 你还可以看下python参考手册中的 python- 位置或关键字参数
- 除此之外, 这篇博客: Python数据分析实战【二】:用Python对不同的商品销售数据进行预测分析【文末源码地址】中的 非线性数据预测 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
shopid为2的商品,在近5个月有升有降的,用模型预测会耗费很大的精力,所以采用加权平均值代替预测值的方法
shop_2_sql = "select * from predictSalesSummary where shopid=2" shop_2_df = link_sqlite(shop_2_sql) shop_2_df
from pyecharts import options as opts from pyecharts.charts import Bar x_names = shop_2_df["month"].tolist() tao_bao = shop_2_df["amount"].tolist() c = ( Bar() .add_xaxis(x_names) .add_yaxis("销售额", tao_bao) .set_global_opts( xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=20)), title_opts=opts.TitleOpts(title="商品每个月销售额"), ) ) c.render_notebook()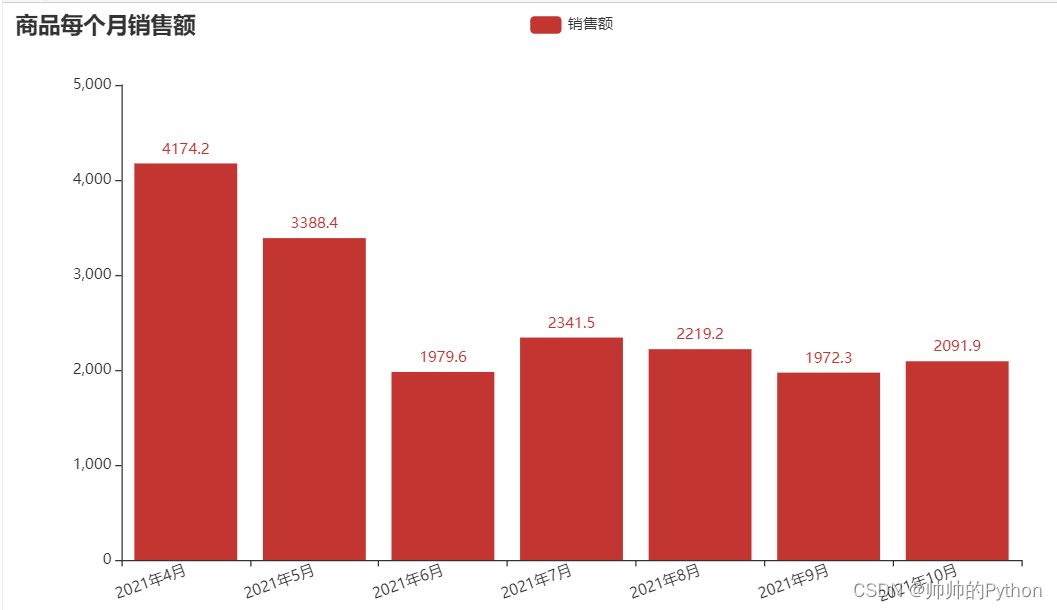
8月份、9月份、10月份的权重为0.2,0.2,0.6,计算得出11月份的销售额为2093万元,结合10月份的销售数据来看,11月份的销售额在 [2091,2094] 之间
np.sum(shop_2_df.iloc[4:,1]*np.array([0.2,0.2,0.6])) # 2093.44shop_2_df.iloc[4:,1].mean() # 2094.47- 您还可以看一下 jeevan老师的Python量化交易,大操手量化投资系列课程之内功修炼篇课程中的 编程语言之Python环境安装小节, 巩固相关知识点
- 以下回答由chatgpt基于相关博客总结生成:
要解决Python抓取弹幕时出现的乱码问题,你可以尝试以下步骤:
- 确定乱码的原因:乱码问题一般是由于编码不一致导致的。在Python中,字符串的默认编码为UTF-8,而抓取到的弹幕可能使用其他编码(例如GBK)。因此,需要确认抓取到的数据的编码格式。 可以尝试打印出抓取到的数据,查看其编码格式。修改以上代码,在抓取数据后添加以下代码:
python print(response.encoding)运行代码后,查看控制台输出的编码格式,看是否与预期一致。
- 解决乱码问题:如果发现抓取到的数据编码格式与预期不一致,可以尝试对数据进行编码转换。使用Python的decode()函数将抓取到的数据从原始编码转换为UTF-8编码。在获取弹幕文本之后,添加以下代码:
python text = res.text.encode(response.encoding).decode('utf-8') html = etree.HTML(text)这里使用
encode(response.encoding)将字符串编码转换为原始编码,然后使用decode('utf-8')将其再次解码为UTF-8编码。最终的代码应为:
python def get_data(url): response = requests.get(url, headers=headers) text = response.text.encode(response.encoding).decode('utf-8') data = etree.HTML(text) # 其他代码...运行修改后的代码,查看抓取到的弹幕文本是否已经正常显示。
如果乱码问题仍然存在,可能是因为弹幕文本的编码格式与UTF-8不兼容。此时,可以尝试其他常见的编码格式,例如GBK等。
- 调整输出的编码格式:在保存弹幕数据的word文档时,可以调整输出的编码格式,以确保保存的文档能正确显示中文字符。修改保存文档的部分代码如下:
python document.save('demo.docx', encoding='utf-8')添加
encoding='utf-8'参数,将文档保存为UTF-8编码。这样可以防止保存文档时出现乱码。尝试以上步骤后,应该能够解决Python抓取弹幕时出现的乱码问题。如果问题仍然存在,可能是由于特殊字符导致的编码问题,可能需要更详细的调查和分析才能找到解决方案。