Java语言读取字典之后,为什么文件读取的区别和重复不同呢
Java语言读取字典之后,再次打开的时候,为什么文件读取的区别和重复不同呢
能详细描述下吗? 我真的看了好半天没看明白你要问的是啥.....
不知道你这个问题是否已经解决, 如果还没有解决的话:- 你可以看下这个问题的回答https://ask.csdn.net/questions/1079933
- 这篇博客也不错, 你可以看下【Java】客户端读取指定文件夹下的文件,客户端传输多个文件给服务器端,服务器端接收文件并存储
- 你还可以看下java参考手册中的 java-学习Java语言 - 描述Java编程语言的基本概念和特点的课程。-类和对象》描述了如何编写创建对象的类,以及如何创建和使用对象。-课堂
- 除此之外, 这篇博客: Java多线程,线程安全与不安全的理解,程序的多线程并发编程的基础概念,进程与线程的区别是什么中的 Java线程与不安全 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
以上描述一个进程可以理解为一个资源容器,当一个进程中的内存资源,可以被多个线程修改时则为不安全的。CPU的速度是远超内存的,并且CPU会碎片化执行处理,让所以线程都可以争抢CPU使用资源;
1、多个线程使用内存中同一个值进行计算,因为线程是异步执行的,也就会出现这个值在某个阶段被多次使用,导致最终计算数据不准确;
2、多个服务中根据同一个值进行计算,由于服务之间也是异步执行的,也会导致这个值在某个阶段被多次使用,导致最终计算数据不准确;案例代码如下,下方代码就会出现多个线程拿到相同值进行计算
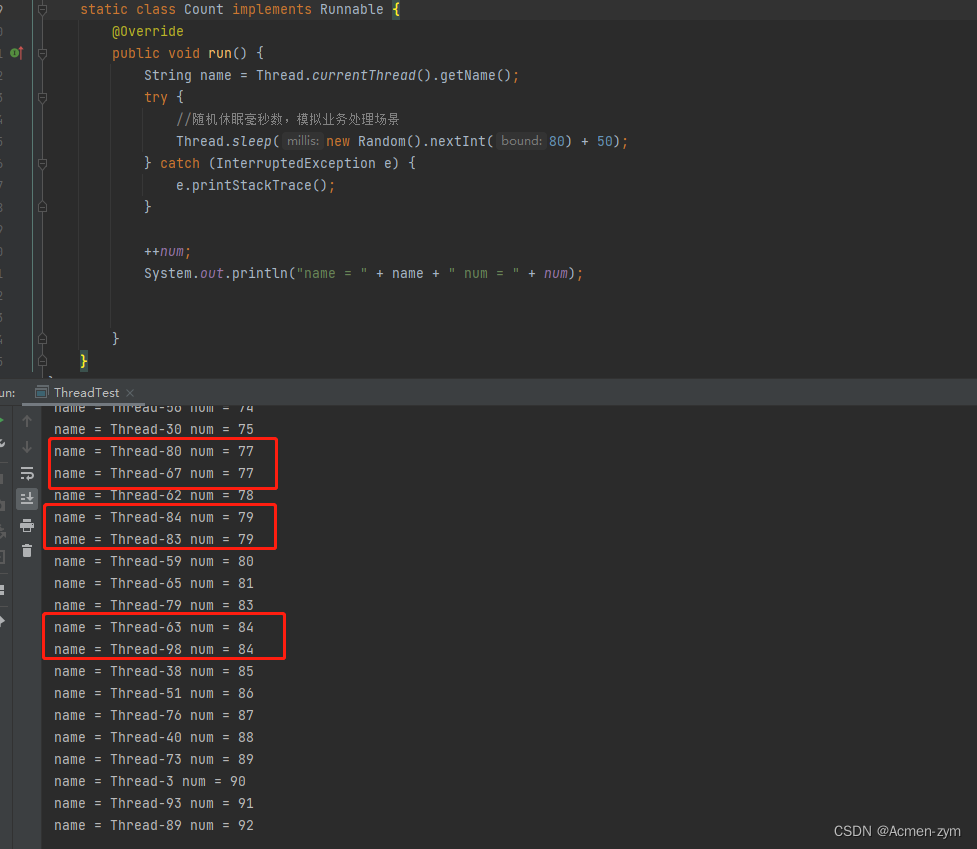
private static int num = 0; public static void main(String[] args) throws InterruptedException { for (int i = 0; i <= 100; i++) { new Thread(new Count()).start(); } //因为是线程异步执行所以需要休眠等待执行完毕 Thread.sleep(8000); } static class Count implements Runnable { @Override public void run() { String name = Thread.currentThread().getName(); try { //随机休眠毫秒数,模拟业务处理场景 Thread.sleep(new Random().nextInt(80) + 50); } catch (InterruptedException e) { e.printStackTrace(); } ++num; System.out.println("name = " + name + " num = " + num); } }此代码打印结果是无法保证最终num值为100的,每次执行都可能会是不同的效果
- 您还可以看一下 黄菊华老师的Java微信小程序化妆品购物商城 大学生毕业设计教学视频课程中的 java小程序化妆品商城 毕业设计课程说明小节, 巩固相关知识点
- 以下回答来自chatgpt:
问题分析: 根据问题描述,每次读取完字典文件后再次打开文件进行读取时,内容都会有所区别并且出现重复的情况。这个问题可能是由于每次读取文件时使用的方式或者是文件本身的特点导致的。为了解决这个问题,可以从以下几个方面进行分析和操作:
查看文件读取方式:如果使用的是文件输入流(FileInputStream)和文件输出流(FileOutputStream),可能每次读取文件时都从头开始读取,导致内容的不一致和重复。可以尝试使用缓冲流(BufferedReader)进行读取。
检查字典文件是否已经被修改:如果每次读取字典文件前都会对文件进行修改,可能会导致读取到不同的结果。在读取文件之前可以先检查文件的修改时间,如果文件被修改过,则重新读取文件。
考虑文件编码:如果字典文件使用的是不同的编码方式,可能会导致读取到不同的结果。可以尝试使用相同的编码方式来读取文件。
解决方案: 1. 使用缓冲流(BufferedReader)进行读取文件:BufferedReader可以按行读取文件内容,并且可以使用readLine()方法读取文件的每一行。这种方式可以提高读取效率,并且可以避免每次读取都从头开始的问题。
- 检查文件是否已被修改:可以使用File类的lastModified()方法获取文件的修改时间,记录下每次读取文件的时间戳,在下一次读取文件时先比较时间戳是否有变化,如果有变化则重新读取文件。示例代码如下:
import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.IOException; public class FileReadExample { private static long lastModified = 0; public static void main(String[] args) { File file = new File("dictionary.txt"); try { BufferedReader reader = new BufferedReader(new FileReader(file)); // 检查文件是否已被修改 if (file.lastModified() != lastModified) { lastModified = file.lastModified(); String line; while ((line = reader.readLine()) != null) { // 处理每一行的内容 // ... } } reader.close(); } catch (IOException e) { e.printStackTrace(); } } }- 指定文件的编码方式:可以使用InputStreamReader来指定文件的编码方式,确保每次读取文件都使用相同的编码方式。示例代码如下:
import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java.io.IOException; import java.io.InputStreamReader; public class FileReadExample { public static void main(String[] args) { File file = new File("dictionary.txt"); try { BufferedReader reader = new BufferedReader(new InputStreamReader( new FileInputStream(file), "UTF-8")); String line; while ((line = reader.readLine()) != null) { // 处理每一行的内容 // ... } reader.close(); } catch (IOException e) { e.printStackTrace(); } } }通过以上的解决方案,可以避免每次读取字典文件后内容的变化和重复的问题。但需要注意的是,如果字典文件本身是动态变化的(例如在读取期间有其他程序在修改文件),还是无法避免内容的变化。如果这种情况无法满足需求,可能需要考虑其他的解决方案或者使用其他的技术手段来实现。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^