java实现省市区转换成树形结构
有一条sql记录。
INSERT INTO `school_info` ( `schoolCode`, `name`, `schoolAlias`, `enName`, `address`, `provinceCode`, `cityCode`, `areaCode`, `cityName`) VALUES (10086, '测试学校', NULL, NULL, NULL, 330000, 330100, 330101, 'wz');
需求:提取出相关的省,市,区,学校的信息,并组成树状的数据结构。
类似于:

该回答引用chatgpt:
先把所有查出来,然后组装成树
参考一下
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
class Location {
int code;
String name;
List<Location> children;
Location(int code, String name) {
this.code = code;
this.name = name;
this.children = new ArrayList<>();
}
}
public class LocationTree {
public static void main(String[] args) {
List<Map<String, Object>> records = new ArrayList<>();
// 假设从数据库中获取到了相关的省市区数据,存储在records列表中
// 将记录转换为Location对象
List<Location> locations = buildLocations(records);
// 构建树状结构
List<Location> tree = buildTree(locations);
// 打印树形结构
printTree(tree, 0);
}
private static List<Location> buildLocations(List<Map<String, Object>> records) {
List<Location> locations = new ArrayList<>();
for (Map<String, Object> record : records) {
int code = (int) record.get("code");
String name = (String) record.get("name");
Location location = new Location(code, name);
locations.add(location);
}
return locations;
}
private static List<Location> buildTree(List<Location> locations) {
Map<Integer, Location> locationMap = new HashMap<>();
// 将每个Location对象存储到map中,以code为键
for (Location location : locations) {
locationMap.put(location.code, location);
}
// 构建树状结构
List<Location> tree = new ArrayList<>();
for (Location location : locations) {
int parentCode = location.code / 10000 * 10000;
Location parent = locationMap.get(parentCode);
if (parent != null) {
parent.children.add(location);
} else {
tree.add(location); // 如果没有父节点,将其视为根节点
}
}
return tree;
}
private static void printTree(List<Location> tree, int level) {
for (Location location : tree) {
for (int i = 0; i < level; i++) {
System.out.print(" "); // 根据层级缩进
}
System.out.println(location.name);
printTree(location.children, level + 1); // 递归打印子节点
}
}
}
写个递归方法根据父子关联查询一下就行了
- 帮你找了个相似的问题, 你可以看下: https://ask.csdn.net/questions/7418766
- 这篇博客也不错, 你可以看下Java中sql语句操作数据库及将数据库信息显示在表格中
- 除此之外, 这篇博客: 面试必备:Sql优化,Sql调优中的 这里我写一写数据库表的命名规则吧,都是我最近在看的阿里巴巴Java开发手册中的一些规范。 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
1、表名、字段名必须统一使用小写字母或数字,禁止出现数字开头以及两个下划线中间就一个数字_8_。
因为MySQL在windows系统下默认是不区分大小写的,而在Linux系统下默认是区分大小写的。
正例:stundent_name,baidu_yunpan反例
StudentName,BaiduYunPan2、在表达是否概念的字段,必须使用is_xxx的方式,而在实体类pojo中,所有boolean类型的变量,前面都不要加is前缀,因为boolean变量生成的set与get方法使用is开头。
举个栗子: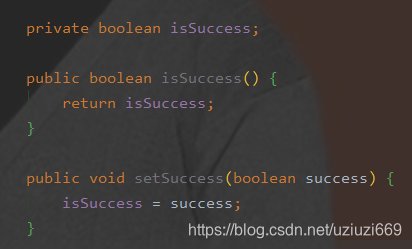
当RPC框架反向解析的时候,以为对应的属性就是Success,导致属性找不到,会引起RPC框架反序列化异常。3、表中索引的命名规则:
- 主键索引名:pk_xxx。
- 唯一索引名:uk_xxx。
- 普通索引名:idx_xx。
说明:pk_即primary key;uk_即unique key;idx_即index的简称
3、存储小数类型时,不要使用double与float。这哥俩儿存在精度损失问题,说白了就是存在出现误差的情况,在比较值的时候可能拿不到正确的结果。建议使用decimal,如果超出decimal的范围,将整数与小数分开存储。
如果使用double与float类型,要在数据库中设置小数的位数,要求小数位相同。4、字符类型,如果字段数据几乎相等,建议使用char定义长字符串类型。比如手机号,位数都在11位;这里就可以使用char类型。
5、varchar是可变长度字符串,不预先分配存储空间,长度不要超过5000,如果超过这个值,建议独立一张表,定义该字段为text,用主键来对应。这样在查询其他字段时,全表扫描等,不会影响其他字段的索引效率。
6、这个我觉得很关键奥,小伙伴留意一下,一个表必备的三个段:id,create_time,update_time。
说明:其中id必须为主键,单表自增、步长为1、数据类型为unsigned bigint。 create_time 与 update_time均为date_time类型。一个是数据创建时间,一个是修改时间。大家都懂哈哈。**为什么表的主键的数据类型一定要使用 bigint unsigned呢?**unsigned表示无符号。
说明:
简单了解一下就好哈~ ~ ~
原文链接:https://blog.csdn.net/nrsc272420199/article/details/102877399 7、当单表行数超过500w行或者单表容量超过2GB时,才建议分库分表。如果预计三年后的数据量仍然无法达到这个级别,请不要在创建表时就分库分表。
7、当单表行数超过500w行或者单表容量超过2GB时,才建议分库分表。如果预计三年后的数据量仍然无法达到这个级别,请不要在创建表时就分库分表。8、每个字段设置合适的存储长度,不但可以节约数据库表空间和索引存储,更重要的是能够提升查询速度。
- 您还可以看一下 马克老师的Java大数据培训学校全套教材--12)数据库课程中的 什么是SQL?小节, 巩固相关知识点