python数据挖掘Apriori
from numpy import *
def loadDataSet():
return [['a', 'c', 'e'], ['b', 'd'], ['b', 'c'], ['a', 'b', 'c', 'd'], ['a', 'b'], ['b', 'c'], ['a', 'b'],
['a', 'b', 'c', 'e'], ['a', 'b', 'c'], ['a', 'c', 'e']]
def createC1(dataSet):
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item])
C1.sort()
# 映射为frozenset唯一性的,可使用其构造字典
return list(map(frozenset, C1))
# 从候选K项集到频繁K项集(支持度计算)
def scanD(D, Ck, minSupport):
ssCnt = {}
for tid in D: # 遍历数据集
for can in Ck: # 遍历候选项
if can.issubset(tid): # 判断候选项中是否含数据集的各项
if not can in ssCnt:
ssCnt[can] = 1 # 不含设为1
else:
ssCnt[can] += 1 # 有则计数加1
numItems = float(len(D)) # 数据集大小
retList = [] # L1初始化
supportData = {} # 记录候选项中各个数据的支持度
for key in ssCnt:
support = ssCnt[key] / numItems # 计算支持度
if support >= minSupport:
retList.insert(0, key) # 满足条件加入L1中
supportData[key] = support
return retList, supportData
def calSupport(D, Ck, min_support):
dict_sup = {}
for i in D:
for j in Ck:
if j.issubset(i):
if not j in dict_sup:
dict_sup[j] = 1
else:
dict_sup[j] += 1
sumCount = float(len(D))
supportData = {}
relist = []
for i in dict_sup:
temp_sup = dict_sup[i] / sumCount
if temp_sup >= min_support:
relist.append(i)
# 此处可设置返回全部的支持度数据(或者频繁项集的支持度数据)
supportData[i] = temp_sup
return relist, supportData
# 改进剪枝算法
def aprioriGen(Lk, k):
retList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i + 1, lenLk): # 两两组合遍历
L1 = list(Lk[i])[:k - 2]
L2 = list(Lk[j])[:k - 2]
L1.sort()
L2.sort()
if L1 == L2: # 前k-1项相等,则可相乘,这样可防止重复项出现
# 进行剪枝(a1为k项集中的一个元素,b为它的所有k-1项子集)
a = Lk[i] | Lk[j] # a为frozenset()集合
a1 = list(a)
b = []
# 遍历取出每一个元素,转换为set,依次从a1中剔除该元素,并加入到b中
for q in range(len(a1)):
t = [a1[q]]
tt = frozenset(set(a1) - set(t))
b.append(tt)
t = 0
for w in b:
# 当b(即所有k-1项子集)都是Lk(频繁的)的子集,则保留,否则删除。
if w in Lk:
t += 1
if t == len(b):
retList.append(b[0] | b[1])
return retList
def apriori(dataSet, minSupport=0.2):
# 前3条语句是对计算查找单个元素中的频繁项集
C1 = createC1(dataSet)
D = list(map(set, dataSet)) # 使用list()转换为列表
L1, supportData = calSupport(D, C1, minSupport)
L = [L1] # 加列表框,使得1项集为一个单独元素
k = 2
while (len(L[k - 2]) > 0): # 是否还有候选集
Ck = aprioriGen(L[k - 2], k)
Lk, supK = scanD(D, Ck, minSupport) # scan DB to get Lk
supportData.update(supK) # 把supk的键值对添加到supportData里
L.append(Lk) # L最后一个值为空集
k += 1
del L[-1] # 删除最后一个空集
return L, supportData # L为频繁项集,为一个列表,1,2,3项集分别为一个元素
# 生成集合的所有子集
def getSubset(fromList, toList):
for i in range(len(fromList)):
t = [fromList[i]]
tt = frozenset(set(fromList) - set(t))
if not tt in toList:
toList.append(tt)
tt = list(tt)
if len(tt) > 1:
getSubset(tt, toList)
def calcConf(freqSet, H, supportData, ruleList, minConf=0.7):
for conseq in H: # 遍历H中的所有项集并计算它们的可信度值
conf = supportData[freqSet] / supportData[freqSet - conseq] # 可信度计算,结合支持度数据
# 提升度lift计算lift = p(a & b) / p(a)*p(b)
lift = supportData[freqSet] / (supportData[conseq] * supportData[freqSet - conseq])
if conf >= minConf and lift > 1:
print(freqSet - conseq, '-->', conseq, '支持度', round(supportData[freqSet], 6), '置信度:', round(conf, 6),
'lift值为:', round(lift, 6))
ruleList.append((freqSet - conseq, conseq, conf))
# 生成规则
def gen_rule(L, supportData, minConf=0.7):
bigRuleList = []
for i in range(1, len(L)): # 从二项集开始计算
for freqSet in L[i]: # freqSet为所有的k项集
# 求该三项集的所有非空子集,1项集,2项集,直到k-1项集,用H1表示,为list类型,里面为frozenset类型,
H1 = list(freqSet)
all_subset = []
getSubset(H1, all_subset) # 生成所有的子集
calcConf(freqSet, all_subset, supportData, bigRuleList, minConf)
return bigRuleList
if __name__ == '__main__':
dataSet =data_translation
L, supportData = apriori(dataSet, minSupport=0.02)
rule = gen_rule(L, supportData, minConf=0.35)
出现代码异常:这是什么原因?
E:\python\sjwj\venv\Scripts\python.exe E:/python/sjwj/3.py
Traceback (most recent call last):
File "E:\python\sjwj\3.py", line 147, in <module>
dataSet =data_translation
NameError: name 'data_translation' is not defined
修改 dataSet = loadDataSet()
- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/7567377
- 这篇博客也不错, 你可以看下【项目实战】Python基于Apriori关联规则算法实现商品零售购物篮分析
- 除此之外, 这篇博客: Python算法总结(十一)Apriori算法(附手写python实现代码)中的 二、算法原理 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
(1)算法流程
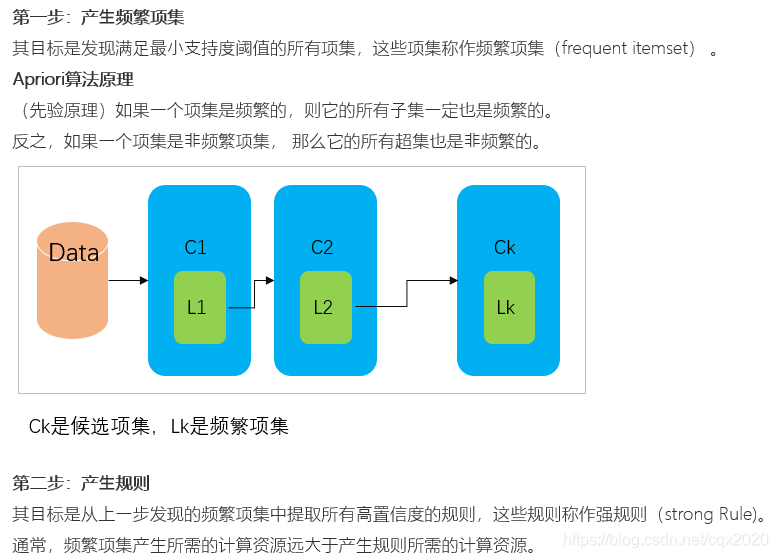
(2)指标
- 您还可以看一下 程序员学院老师的Python数据分析与挖掘从零开始到实战课程中的 Python基础之文件读写(下)小节, 巩固相关知识点
- 以下回答由chatgpt基于相关博客总结生成:
我可以看到问题是在Python数据挖掘中使用Apriori算法时出现了代码异常,但是缺乏具体的细节和错误提示信息。由于Apriori算法是一种关联规则挖掘算法,可以用于在有大量交易记录的数据集中寻找物品之间的关联关系,因此在使用过程中可能会出现许多不同的异常情况。以下是一些常见的问题和解决方案,希望能帮助您快速解决问题:
- 数据格式错误:Apriori算法需要的输入数据格式为一个列表或一个DataFrame,其中每一行代表一次交易,每一列代表一个物品,单元格的值表示物品是否存在于当前交易中。如果数据格式不正确,可能会导致代码异常。
解决方案:请确保您的数据符合上述格式,并按照正确的方式将其输入到Apriori算法中。您可以使用pandas库中的read_csv()函数来将CSV文件读入DataFrame中,并使用sklearn库中的TransactionEncoder将其转换为Apriori算法所需的格式。
- 参数设置不当:Apriori算法有许多参数可以调整,例如最小支持度、最小置信度、最大项集大小等。如果参数设置不当,可能会导致算法无法收敛或结果不准确。
解决方案:请参考Apriori算法的文档或示例代码,仔细调整参数并测试不同的设置,以找到最优的参数组合。通常需要基于实际业务场景和数据集大小等因素灵活调整参数。
- 内存错误:由于Apriori算法需要对数据集进行多次扫描和处理,如果数据集过大,可能会导致内存不足或程序崩溃。
解决方案:请使用内存管理工具、增加服务器内存或使用分布式计算等方法,以确保算法运行所需的内存足够。同时,也可以考虑使用其他更为高效的关联规则挖掘算法,例如FP-Growth算法。
- 数据量过小:如果数据集太小,可能会导致无法找到足够的频繁项集和关联规则,从而影响算法的效果。
解决方案:请确保数据集具有足够的大小和多样性,以满足Apriori算法的要求。如果数据集确实过小,可以考虑使用其他更为适合小数据集的算法,例如基于规则的分类算法。
如果您需要更具体的帮助,请提供更多的背景信息和错误提示信息,以便能够更好地帮助您解决问题。