关于#ORACLE#的问题,如何解决?
ORACLE 同一个sql偶尔运行很慢,请问一般有哪些原因,有哪些方法可以应对

不知道楼上两个gpt在胡说什么,执行慢跟你sql的执行计划有关,你把执行计划贴图就看得出来语句走的啥方向的,是否用过了索引?
Oracle运行相同的SQL语句时,偶尔运行时间很长的情况通常有如下几种可能性和解决办法:
- 系统资源受限
如果在运行SQL语句的时候遇到系统资源受限的情况,例如内存、CPU使用率过高等,就会导致SQL语句的执行时间变长。解决此问题的方法是增加系统资源,例如增加内存、优化CPU配置,并对其进行合理分配和配置。
- 数据库锁定
如果数据库在执行SQL语句的时候遇到锁定的情况,例如其他用户正在对所需的数据进行修改,就会导致SQL语句的执行时间变长。为了解决此问题,可以让其他用户先提交或回滚当前的事务,或者增加更多的锁定来防止其他用户尝试修改同一块数据。
- 数据量过大
如果在运行SQL语句时遇到大量数据的情况,例如表中包含大量数据,或者查询结果集过大,就会导致SQL语句的执行时间变长。为解决此问题,可以通过调整SQL语句的优化方案和分批处理数据等方式来减少数据量。
- SQL语句本身优化不足
如果SQL语句本身存在优化不足或者语法错误等问题,就会导致SQL语句的执行时间变长。为解决此问题,需要深入了解SQL语句的优化方式,并对语句本身进行调整和优化。
- 数据库统计信息有误
如果数据库优化器使用的统计信息不准确或不全面,就会导致SQL语句的执行计划错误,从而导致执行时间变长。为了解决此问题,可以使用Oracle提供的统计信息更新工具,重新计算统计信息。
总之,在对Oracle运行相同SQL语句出现运行时间过长的问题进行解决时,需要全面分析各种原因,并针对性地进行相应的优化措施。同时,需要注意对SQL语句的优化必须仔细谨慎,否则可能会导致数据库性能下降。
为保证 Oracle 运行 SQL 语句的耗时最小,需要考虑以下几个方面:
- 优化 SQL 语句本身的性能
优化 SQL 语句本身的性能是最基本的措施,可以从以下方面考虑:
- 使用正确的 SQL 语法和查询方式。
- 避免全表扫描或索引扫描等低效操作。
- 优先使用合适的索引,确保 SQL 语句的查询条件能够充分利用索引。
- 避免过多的关联操作或子查询操作。
- 合理设置 Oracle 实例和数据库参数
合理设置 Oracle 实例和数据库参数,可以提高 SQL 语句的执行效率,例如:
- 按需分配内存和 CPU 资源。
- 控制 PGA 表空间和 SGA 缓存的大小和扩展方式,避免资源浪费。
- 启用合适的内存管理模式,避免频繁的内存切换或释放。
- 配置适当的硬件环境
适当配置硬件环境,可以提高系统的整体性能。例如:
- 使用高效的硬件设备和存储设备,提高读写速度。
- 使用高速网络,优化数据的传输效率。
- 安排和优化任务调度和限流
合理安排任务调度和限流,可以避免系统因过多的并发操作而降低性能,例如:
- 合理分配并发连接数。
- 定期清理不必要的连接,释放资源。
- 避免短时间内大量任务同时对数据库进行操作。
需要注意的是,在优化 Oracle 运行 SQL 语句的性能时,不应只关注单个 SQL 语句的性能,而是要以系统整体性能为目标,综合考虑系统各方面的因素。
原因可能有:
1、数据库性能问题:数据库可能存在性能问题,例如内存不足、CPU负载过高、I/O瓶颈等,导致SQL执行时响应时间变慢。
2、数据库锁问题:在高并发的情况下,如果SQL涉及到表的读写操作,可能会出现锁等待的情况,导致SQL执行变慢。
3、网络问题:如果SQL执行过程中出现网络延迟或者网络抖动等问题,也会导致SQL执行变慢。
4、SQL优化问题:SQL语句本身可能存在优化问题,例如没有正确使用索引、没有合理地使用连接查询、存在大量的子查询等,导致SQL执行效率低下。
采取方法:
1、对数据库进行性能调优,例如增加内存、优化磁盘I/O、调整数据库参数等。
2、对SQL进行优化,例如使用索引、避免全表扫描、减少子查询等。
3、对数据库进行分析,查看是否存在锁等待的情况,可以使用Oracle自带的锁等待分析工具(如v$lock、dbms_lock)来进行分析。
4、对网络进行优化,例如检查网络连接是否稳定、优化网络带宽等。
5、对SQL执行计划进行分析,可以使用Oracle自带的SQL执行计划分析工具(如explain plan、autotrace)来进行分析,查看SQL的执行计划,找到SQL执行效率低下的原因。
6、对SQL进行重构,例如将复杂的子查询拆分成多个简单的查询、避免使用OR条件、减少使用通配符等
总之的话针对SQL偶尔运行很慢的问题,需要综合考虑多个方面,从数据库性能、SQL优化、锁等待、网络等多个方面入手,采取相应的优化措施来提高SQL的执行效率。
如有帮助望采纳!
- 你可以看下这个问题的回答https://ask.csdn.net/questions/763614
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:oracle数据库查询,sql没问题,数据库也有数据,方法没错,项目运行就是查不出数据
- 除此之外, 这篇博客: Oracle数仓中判断时间连续性的几种SQL写法中的 三、通过构造树形结构,确定根节点和叶子节点来获取状态连续的开始和结束时间 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
先按照数据的连续性构造显示每层关系的树状结构:
with t as (select a.policyno, a.state, a.snapdate, lag(a.snapdate) over(partition by a.policyno, a.state order by a.snapdate) as lag_tim from zyd.temp_0430 a --where policyno='sm1' order by a.policyno, a.snapdate), t1 as (select t.*, case when t.snapdate = t.lag_tim + 1 then 0 else 1 end as lxzt from t order by policyno, snapdate), t2 as (select t1.*, lpad('->', (level - 1) * 2, '->') || snapdate as 树状结构, level as 树中层次, decode(level, 1, 1) 是否根节点, decode(connect_by_isleaf, 1, 1) 是否叶子节点, case when (connect_by_isleaf = 0 and level > 1) then 1 end 是否树杈, (prior snapdate) as 根值, connect_by_root snapdate 主根值 from t1 start with (lxzt = 1) connect by (prior snapdate = snapdate - 1 and prior state = state and prior policyno = policyno) order by policyno, snapdate) select * from t2;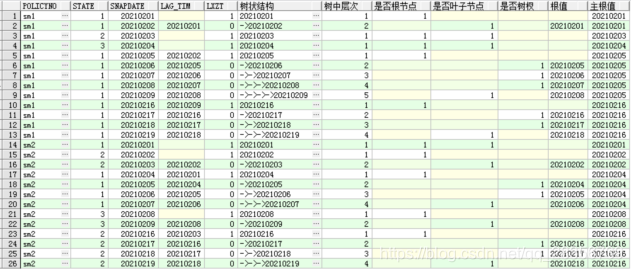
从上面能清晰的看出来,每一次连续状态的开始日期作为每个树的根,分支节点即树杈和叶子节点的关系一步步拓展开来,分析上面数据我们能够知道,如果我们想要获取
每个保单状态连续时间范围,以上面的数据现有分布方式,现在就可以:通过policyno,state,主根值进行group by 取snapdate的最大最小值,类似前面两个写法的最终步骤;
接下来,我们这个第三种写法就是按照这个方式写:with t as (select a.policyno, a.state, a.snapdate, lag(a.snapdate) over(partition by a.policyno, a.state order by a.snapdate) as lag_tim from zyd.temp_0430 a --where policyno='sm1' order by a.policyno, a.snapdate), t1 as (select t.*, case when t.snapdate = t.lag_tim + 1 then 0 else 1 end as lxzt from t order by policyno, snapdate), t2 as (select t1.*, lpad('->', (level - 1) * 2, '->') || snapdate as 树状结构, level as 树中层次, decode(level, 1, 1) 是否根节点, decode(connect_by_isleaf, 1, 1) 是否叶子节点, case when (connect_by_isleaf = 0 and level > 1) then 1 end 是否树杈, (prior snapdate) as 根值, connect_by_root snapdate 主根值 from t1 start with (lxzt = 1) connect by (prior snapdate = snapdate - 1 and prior state = state and prior policyno = policyno) order by policyno, snapdate) select policyno, state, min(snapdate) as start_date, max(snapdate) as end_date from t2 group by policyno, state, 主根值 order by policyno, state;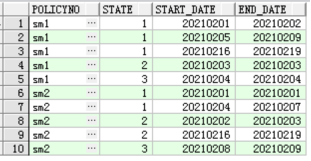
- 您还可以看一下 贾岩老师的Oracle 入门学习视频课程中的 Oracle数据库的创建小节, 巩固相关知识点
- 以下回答由chatgpt基于相关博客总结生成:
针对ORACLE同一个SQL偶尔运行很慢的问题,可能的原因有以下几个方面:
1.数据库锁定:当SQL语句需要访问被锁定的数据时,会导致SQL语句运行缓慢。可以通过查询v$lock和DBMS_LOCK视图来检查锁定情况,并且可以使用对应的锁定方法来解除锁定。
2.索引问题:如果表没有合适的索引,SQL语句的执行会导致全表扫描,从而影响性能。通过使用EXPLAIN PLAN来分析SQL语句的执行计划,并根据计划结果来创建或更改表的索引。
3.统计信息不准确:如果统计信息不准确,数据库就无法正确估计数据的大小和位置,从而影响SQL语句的执行计划和性能。可以通过使用DBMS_STATS包来统计表和索引的信息,并且可以使用ANALYZE命令来生成统计信息。
4.数据库设计问题:如果数据库的设计不合理,会导致SQL语句运行缓慢。可以通过优化数据库的范式、表设计和数据分区等方面来改善性能。
对于优化方法,可以采取以下措施:
1.使用合适的索引:创建索引可以加速SQL语句的执行,但是创建索引也会增加数据库的空间占用,对于大型数据库来说尤其如此。需要对表进行分析后,创建合适的索引。
2.缓存数据:缓存可以减少SQL语句的执行时间,由于数据库读写的速度差异很大,所以尽量避免直接从磁盘读取数据,而是将数据缓存到内存中。
3.优化SQL语句:可以通过重构SQL语句来提高性能,采用EF Core中的查询优化方式,使用内联查询,以及只查询需要的字段等方式。
4.使用分区表:如果表数据较大,可以将表按照日期等条件进行分区,从而减少查询时扫描的数据范围,提高查询速度。
总之,对于优化SQL语句的问题,需要综合考虑表结构、数据大小、索引、统计信息和数据库的设计等多方面因素,才能找到最优的解决方案。