训练VGGface2时报错 C:\cb\pytorch_1000000000000\work\aten\src\ATen\native\cuda\Loss.cu:242: block: [0,0,0]
使用
https://github.com/cydonia999/VGGFace2-pytorch
这个项目训练时一直报错,用的时从csdn能下载到的数据集,原网已经不提供数据了。
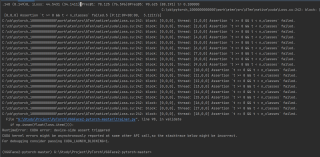
目前做出的努力:
1、由于源码老旧,能使用的pytorch需要更新一些函数的调用方式,才能避免运行前期报错。
类似:
loss.data[0]换成loss.item()
view(-1)换成reshape(-1)
直到修改到运行时期不会报错为止。
2、从csdn下载到的vggface2数据集,其中的identity_meta.csv文件中,有19条数据的格式与其他不一致,我改成一致后,仍旧不能阻止上面的报错(不改也一样,但是不改的话遍历文件的时候不会显示label)
3、训练过程监督gpu使用率,一直处于50~60%,不高于5G的样子。所以修改batch_也没用。
做出这些修改后,训练了10小时仍旧报如上错。
谁能告诉我怎么修改?
**答案参考ChatGPT ,如果有参考价值麻烦采纳一下,谢谢啦!!_**
这个错误通常是由于使用了不兼容的CUDA版本或显卡驱动程序引起的。以下是一些可能有用的解决方案:
确保你使用的CUDA版本与你的显卡驱动程序兼容。你可以在CUDA官方网站上查看CUDA版本与驱动程序的兼容性列表。
确保你已经正确安装和配置了CUDA,包括环境变量和路径等设置。
确保你已经正确安装和配置了PyTorch和相关的库文件,包括torchvision、numpy等。
尝试使用更低版本的PyTorch或torchvision,或者升级到最新版本,以确保与你的CUDA版本和显卡驱动程序兼容。
尝试重新安装CUDA和显卡驱动程序,并确保你遵循了正确的安装步骤和配置。
检查你的显卡是否支持CUDA和CUDA版本,以确保你的显卡可以用于加速深度学习计算。