Elasticsearch中文分词+拼音分词无法生成一些相关的词汇拼音全拼
Elasticsearch中文分词+拼音分词无法生成一些相关的词汇拼音全拼
es版本:7.6.2 语言:php
这是自定义分词:
"analysis"=>[
"analyzer"=>[
"my_analyzer"=>[
"type"=>"custom",
"tokenizer"=>"ik_max_word",
"filter"=>"my_filter"
]
],
"filter"=>[
"my_filter"=>[
"type"=>"pinyin",
"first_letter" => "prefix",
"padding_char" => "",
"keep_separate_first_letter"=>false,
"keep_full_pinyin"=>true,
"keep_original"=>true,
"limit_first_letter_length"=>16,
"lowercase"=>true,
'keep_first_letter'=>true,
"remove_duplicated_term"=>true,
"keep_joined_full_pinyin"=>true #这里设置为true
]
]
],
搜索词为”腾讯“它会返回:
{
"tokens": [
{
"token": "teng",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "xun",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 1
},
{
"token": "腾讯",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 1
},
{
"token": "tengxun",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 1
},
{
"token": "tx",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 1
}
]
}
搜索”微信“会返回:
{
"tokens": [
{
"token": "wei",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "微",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "w",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "xin",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "信",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "x",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
}
]
}
就是不生成微信的全拼,导致输入”weixin“搜索不到,中间加个空格就可以了”wei xin“,不止微信还有钉钉,微博等词。
我尝试修改pinyin的源码但未生效
不知道哪里的问题导致一些词无法生成全拼
添加自定义词典,加入“微信”等词
调整分词器和拼音过滤器的顺序,让拼音过滤器先执行
这两种方法试下
基于new bing部分指引作答:
首先,请确保您的Elasticsearch版本和所使用的插件版本是兼容的,并且没有其他配置或插件冲突导致该问题。然后,我将提供一些可能的解决方案和建议,希望能帮助您解决这个问题:
1、更新插件版本:确保您正在使用的中文分词和拼音分词插件是最新版本,以确保已修复任何已知问题。
2、修改分词器配置:尝试调整分词器的配置参数,例如更改"tokenizer"为"ik_smart"或"ik_smart_pinyin",并检查是否能够生成更准确的拼音。
3、自定义分词规则:如果内置的分词规则无法满足您的需求,您可以尝试自定义分词规则。可以通过添加自定义词典或调整分词器的参数来实现。对于您的例子,可以尝试添加词典项"微信"来确保正确的分词和拼音生成。
4、使用其他拼音分词插件:除了默认的拼音分词插件,还有其他第三方插件可供选择。您可以尝试使用其他插件,如"elasticsearch-analysis-pinyin"或"elasticsearch-analysis-smartcn",看是否能够更好地满足您的需求。
5、查看日志和错误信息:检查Elasticsearch的日志文件,查看是否有任何与分词和拼音生成相关的错误或警告信息。这可能有助于确定问题所在。
来自GPT:
可能是因为某些词汇的拼音无法被正确生成。可以尝试以下方法解决这个问题:
- 确认使用的中文分词器能够正确地将词汇切分成单个汉字,避免出现一些特殊的词组无法被正确拆分的情况。
- 调整pinyin分词器的配置,尝试启用更多的选项,例如增加keep_separate_first_letter、keep_full_pinyin、keep_original等选项,这样可以保证生成更多的拼音。
- 如果以上方法都无法解决问题,可以尝试使用其他的中文分词器和拼音分词器,看看是否能够解决问题。
- 如果还是无法解决问题,建议找到Elasticsearch的专业人员进行咨询,他们可能会有更好的解决方案。
- 这篇博客: ElasticSearch核心语法及集群高可用搭建中的 1.ES中映射可以分为动态映射和静态映射 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
(1)动态映射:
在关系数据库中,需要事先创建数据库,然后在该数据库下创建数据表,并创建表字段、类型、长度、主键等,最后才能基于表插入数据。而Elasticsearch中不需要定义Mapping映射(即关系型数据库的表、字段等),在文档写入Elasticsearch时,会根据文档字段自动识别类型,这种机制称之为动态映射。
动态映射规则如下:
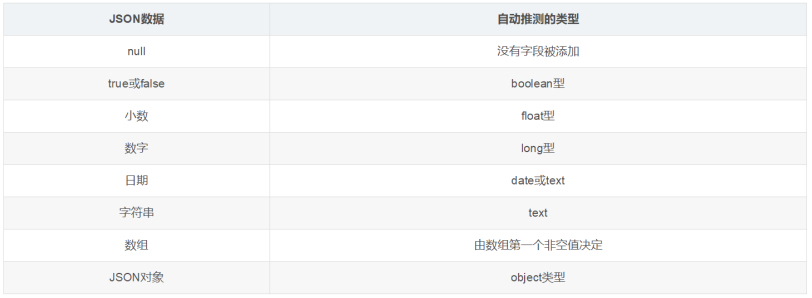
(2)静态映射:
静态映射是在Elasticsearch中也可以事先定义好映射,包含文档的各字段类型、分词器等,这种方式称之为静态映射。
拼音字典的问题应该,上次我遇到类似的问题。你可以考虑更新拼音字典,或者自定义拼音字典以包含这些缺失的词汇。以下是一些可能有用的解决方法:
更新拼音字典。 Elasticsearch内置使用 OpenCC 的拼音字典进行中文分词和拼音分词,你可以尝试更新字典或使用其他的拼音字典。在中文环境下,常用的拼音字典有小鹤双拼和微软拼音等。你可以在 Elasticsearch 的配置文件中配置拼音字典。
自定义拼音字典。 如果你有一些特定的词汇需要生成拼音索引,你可以自定义拼音字典以包含这些词汇。具体的实现方法可以参考 Elasticsearch 的官方文档中的介绍。
采用 N-gram 等分词器。 如果你的数据集中有很多杂音或难以处理的词汇,可以考虑采用 N-gram 或 Edge NGram 等分词器,以解决一些无法生成拼音的情况。
Elasticsearch1.x 拼音分词实现全拼首字母中文混合搜索
可以参考下
https://blog.csdn.net/chennanymy/article/details/52336368