结合给定的25个蒙古语文本语料文件,采用TF-IDF方法提取指定文件“关键词提取-蒙古文文本.txt”中的蒙古文、英文关键词。
结合给定的25个蒙古语文本语料文件,采用TF-IDF方法提取指定文件“关键词提取-蒙古文文本.txt”中的蒙古文、英文关键词。
要实现 TF-IDF 方法提取关键词,可以使用 Python 中的 nltk 和 sklearn 库。下面是具体的实现步骤:
- 导入相关库
import os
import string
import nltk
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import TfidfVectorizer
- 定义文本读取函数
def read_file(filepath):
"""
读取文件内容
:param filepath: 文件路径
:return: 文件内容
"""
with open(filepath, 'r', encoding='utf-8') as f:
content = f.read().replace('\n', '')
return content
- 定义停用词列表
# 定义蒙古文和英文的停用词表
mongolian_stopwords = stopwords.words('mongolian')
english_stopwords = stopwords.words('english')
# 将标点符号加入停用词列表中
stopwords_list = mongolian_stopwords + english_stopwords + list(string.punctuation)
- 遍历指定文件夹中的文件,读取文本内容
# 指定文件夹路径
folder = r'C:\corpus'
# 存放所有文件文本内容的列表
file_contents = []
# 遍历文件夹中的所有文件
for filename in os.listdir(folder):
file_path = os.path.join(folder, filename)
# 如果是txt文本文件,则读取文本内容
if os.path.isfile(file_path) and filename.endswith('.txt'):
file_content = read_file(file_path)
file_contents.append(file_content)
- 将文本内容进行 TF-IDF 计算
# 定义 TfidfVectorizer 对象,并指定停用词表
tfidf_vectorizer = TfidfVectorizer(stop_words=stopwords_list)
# 对所有文本内容进行 TF-IDF 计算
tfidf_matrix = tfidf_vectorizer.fit_transform(file_contents)
# 获取指定文件的索引
target_index = file_contents.index(read_file('关键词提取-蒙古文文本.txt'))
# 获取该文件的 TF-IDF 值,按从大到小排序
doc_scores = list(zip(tfidf_vectorizer.get_feature_names(), tfidf_matrix.toarray()[target_index]))
sorted_scores = sorted(doc_scores, key=lambda x: x[1], reverse=True)
在上述代码中,首先使用 TfidfVectorizer 类来计算 TF-IDF 值,并传入停用词列表。然后使用 fit_transform() 方法将所有文本转换为 TF-IDF 矩阵。接着获取指定文件的索引,并使用 toarray() 方法将该文件的 TF-IDF 矩阵转换成数组形式。然后将所有的关键词和对应的 TF-IDF 值组合成一个元组列表,并按照元组中的第二个元素(即 TF-IDF 值)从大到小排序。
最终的代码如下:
import os
import string
import nltk
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import TfidfVectorizer
def read_file(filepath):
"""
读取文件内容
:param filepath: 文件路径
:return: 文件内容
"""
with open(filepath, 'r', encoding='utf-8') as f:
content = f.read().replace('\n', '')
return content
# 定义蒙古文和英文的停用词表
mongolian_stopwords = stopwords.words('mongolian')
english_stopwords = stopwords.words('english')
# 将标点符号加入停用词列表中
stopwords_list = mongolian_stopwords + english_stopwords + list(string.punctuation)
# 指定文件夹路径
folder = r'C:\corpus'
# 存放所有文件文本内容的列表
file_contents = []
# 遍历文件夹中的所有文件
for filename in os.listdir(folder):
file_path = os.path.join(folder, filename)
# 如果是txt文本文件,则读取文本内容
if os.path.isfile(file_path) and filename.endswith('.txt'):
file_content = read_file(file_path)
file_contents.append(file_content)
# 定义 TfidfVectorizer 对象,并指定停用词表
tfidf_vectorizer = TfidfVectorizer(stop_words=stopwords_list)
# 对所有文本内容进行 TF-IDF 计算
tfidf_matrix = tfidf_vectorizer.fit_transform(file_contents)
# 获取指定文件的索引
target_index = file_contents.index(read_file('关键词提取-蒙古文文本.txt'))
# 获取该文件的 TF-IDF 值,按从大到小排序
doc_scores = list(zip(tfidf_vectorizer.get_feature_names(), tfidf_matrix.toarray()[target_index]))
sorted_scores = sorted(doc_scores, key=lambda x: x[1], reverse=True)
# 输出前10个关键词
for i in range(10):
print(sorted_scores[i][0])
在代码中,需要将文件夹路径和指定文件名修改为实际路径和文件名。
不知道你这个问题是否已经解决, 如果还没有解决的话:- 这篇博客: 【笔记】基于TF-IDF 算法的文本相似度以衡量技术革新中的 07 衡量创新与生产率的关系 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
1、综合生产力
首先关注总生产力的增长。对于战后的样本,使用Basu等人(2006)构建的TFP衡量方法,该方法可用于1948-2018年期间。对于早期的样本,使用Kendrick(1961)收集的数据,用每小时产出来衡量生产率,该数据可用于1889年至1957年期间。根据Jorda(2005),本文估计了以下回归:

其中Xt表示全要素生产率(TFP)的对数值,BreakthroughIndex表示行业创新指数(突破专利的数量,按产业划分),并考虑τ=1,...,10年的时间范围,还研究了创新和过去生产率增长之间的关系,即为τ负值的情况。
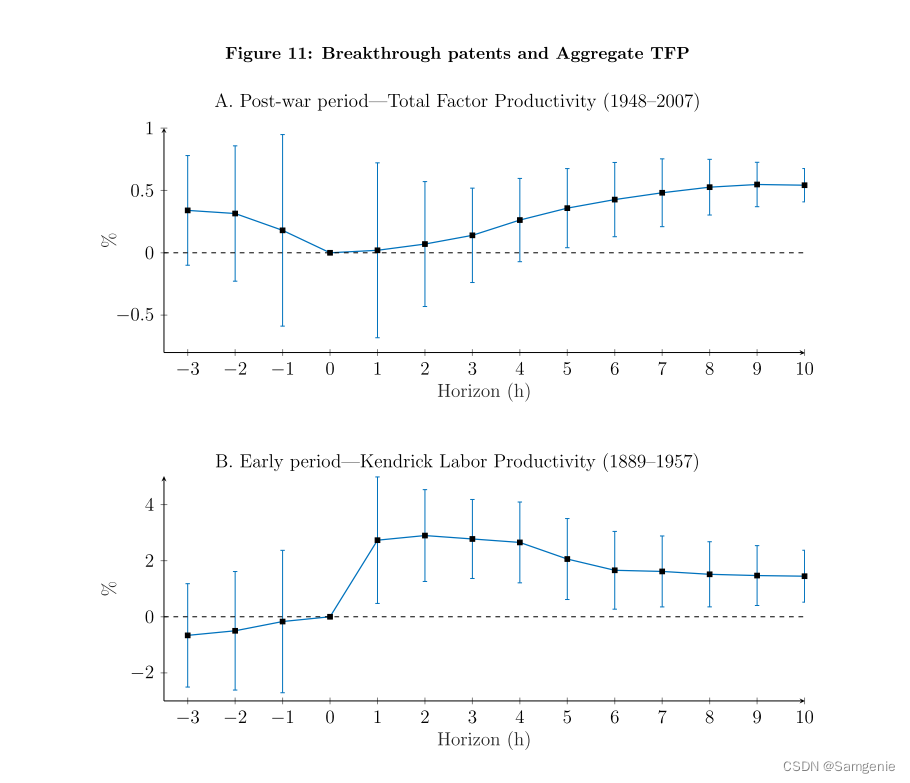
图A给出了估计的结果 (14)为战后样本。将重点放在5到10年的视野上,本文的技术指数的标准差增长与每年0.5%的TFP增长相关联--考虑到这一时期衡量的TFP增长的标准差是1.8%,这是很可观的。重要的是,过去生产力的变化与创新指数之间没有统计学上的显著相关性。图B显示了早期样本的结果。同样关注5至10年的视野,本文的创新指数的一个标准差与劳动生产率每年约1.5-2%的增长相关--相比之下,劳动生产率增长的年标准差为5.2%。
2、行业层面的分析
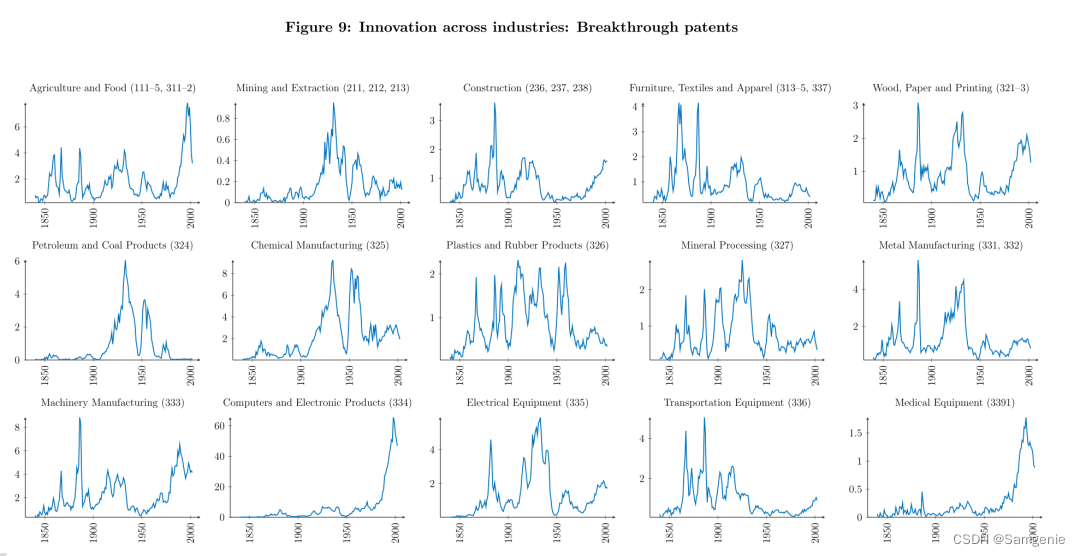
图中显示了各行业的突破性专利数量。行业是根据NAICS代码定义的。突破性专利是指扣除年份固定效应后,在基线质量衡量指标(定义为10年前向与5年后向相似度之比)中排名前10%的专利。本文使用Goldschlag等人(2016)构建的CPC4到NAICS交叉通道构建行业指数。

其中,xi,t表示(对数)多因素生产率;BreakthroughIndexi,t是行业创新指数(突破性专利的计数,按人口比例缩放);Zi,t是包括时间和行业固定效应、专利总数对数、按人口比例和生产率水平的控制向量。
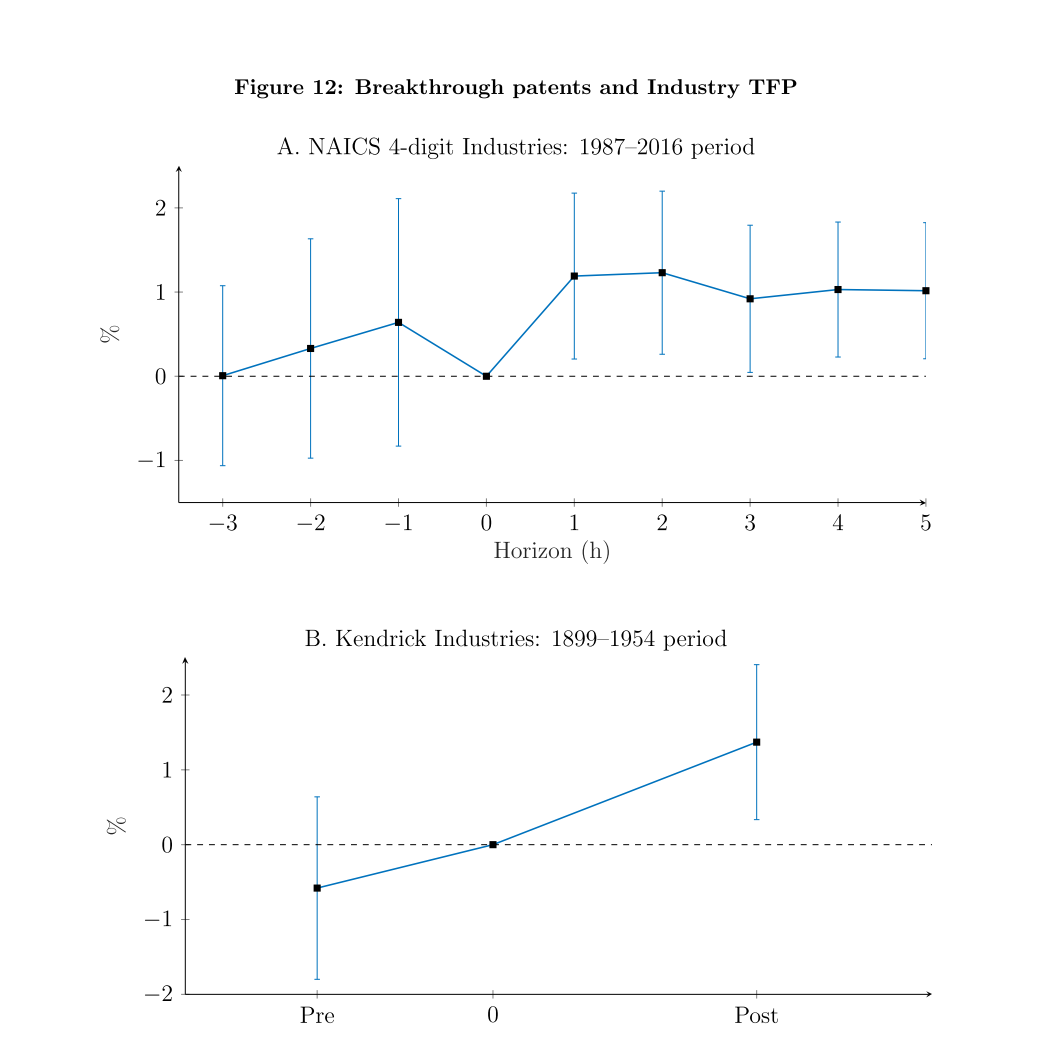
图中绘制了行业全要素生产率对本文技术创新指数的单位标准差冲击的反应。图A显示了86个制造业行业在NAICS 4位数水平上的结果,使用的是劳工统计局的数据。图B(Kendrick数据)的数据来自Kendrick(1961)中的表D-V,包括62个制造业行业1899年、1909年、1919年、1937年、1947年和1954年的劳动生产率水平(每工时产出)的信息。对于每个时期(t,s),本文将对数劳动生产率的年化差异回归到t±2年的累计创新水平(突破性专利数量)的对数上--控制了时期、行业假想值、同期专利数量的对数以及t时生产率的对数水平。得出行业创新指数和测算生产率:美国创新指数提高一个标准差,下期测算生产率增长率就会提高1.4%。
- 以下回答来自chatgpt:
由于文本提取涉及到多个步骤,包括数据清洗、分词、去停用词、TF-IDF方法等,需要多种技术的支持。以下是一个可能的步骤和提示:
- 对于蒙古文文本文件,首先需要进行数据清洗和去除噪声,以便后续处理。可以使用Python的re模块和BeautifulSoup库等工具来完成。具体代码如下:
```python import re from bs4 import BeautifulSoup
def clean_text(text): # 去除HTML标签和注释等噪声 soup = BeautifulSoup(text, 'html.parser') text = soup.get_text().strip() # 去除非蒙古文和英文字符 text = re.sub(r'[^\u1800-\u18AF\u0400-\u04FFA-Za-z]+', ' ', text) return text ```
- 进行中文分词处理。可以使用Python的第三方库jieba来完成分词,并结合停用词表进行去停用词。具体代码如下:
```python import jieba import os
# 加载停用词表 stopwords = [] with open('<路径>/stopwords.txt', 'r', encoding='utf-8') as f: stopwords = [line.strip() for line in f.readlines()]
# 分词函数 def seg_chinese(text): words = [] seg_list = jieba.cut(text) for word in seg_list: if word not in stopwords: words.append(word) return words ```
- 对于英文文本,可以使用NLTK库进行分词,结合停用词表进行去停用词处理。具体代码如下:
```python import nltk from nltk.corpus import stopwords
# 下载停用词表 nltk.download('stopwords')
# 加载停用词表 stop_words = set(stopwords.words('english'))
# 分词函数 def seg_english(text): words = [] tokens = nltk.word_tokenize(text) for token in tokens: if token not in stop_words and token.isalpha(): words.append(token) return words ```
- 对于整个文本语料库,可以利用Python的glob库来读取文件,结合前面的分词函数,将文本数据处理成分词后的格式,以便后续运算。具体代码如下:
```python import glob
# 遍历整个文本语料库,将每个文件的文本分词处理 corpus = [] for file in glob.glob('<语料库路径>/*.txt'): with open(file, 'r', encoding='utf-8') as f: text = f.read().strip() # 进行不同语言的分词处理 if '蒙古' in file: words = seg_chinese(clean_text(text)) elif '英语' in file: words = seg_english(clean_text(text)) else: continue # 其他语言暂不处理 # 将分词结果存入文本语料库 corpus.append(' '.join(words)) ```
- 进行TF-IDF计算。可以使用Scikit-learn库中的TfidfVectorizer类来完成计算。具体代码如下:
```python from sklearn.feature_extraction.text import TfidfVectorizer
# 初始化TF-IDF计算器 vectorizer = TfidfVectorizer() # 计算TF-IDF矩阵 tfidf_matrix = vectorizer.fit_transform(corpus) # 获取关键词 feature_names = vectorizer.get_feature_names() for i in range(len(corpus)): doc = tfidf_matrix[i] # 获取该文档中TF-IDF值最高的前N个关键词 idx = doc.toarray().argsort()[0][-N:][::-1] keywords = [feature_names[j] for j in idx] # 输出结果 print(f'文档{i+1}的关键词为: {" | ".join(keywords)}') ```
其中N是需要提取的关键词数量。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^