r语言线性混合模型协变量
请问如何在r语言线性混合模型中添加协变量?直接加在固定因子的后面可以吗?协变量要加在对比矩阵中吗?
在R语言中的线性混合模型中,可以通过在模型公式中添加协变量来将其作为固定效应加入到模型中。一般情况下,协变量可以直接加在固定因子的后面,例如:
r
Copy
lmer(response ~ fixed_factor + covariate + (1|random_factor), data = my_data)
其中,fixed_factor和random_factor分别代表固定效应和随机效应。covariate代表协变量,可以直接加在固定因子的后面。需要注意的是,协变量与固定因子应该是独立的,即协变量不应该与固定因子存在高度相关性。
对于比较矩阵(contrasts),协变量不需要加入其中。比较矩阵主要用于比较不同水平之间的差异,而协变量通常是用来调节或控制其他因素的影响。因此,在比较矩阵中不需要考虑协变量的影响。
需要说明的是,在使用协变量时,需要注意其与其他变量的共线性和多重共线性等问题,以避免模型出现过拟合和不稳定等情况。同时,还需要根据实际研究问题选择合适的协变量,并进行适当的数据清洗和处理,以提高模型的准确性和可靠性。
- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/7653438
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:【R语言 可视化】R语言画图增加次要刻度线
- 除此之外, 这篇博客: R语言 线性混合效应模型实战案例中的 随机效应有什么意义? 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
如何解释我们的随机效应的实质性影响?在使用多层次结构的观察工作中,这往往是至关重要的,了解分组对个体观察的影响。为了做到这一点,我们选择了12个随机案例,然后模拟他们的预测值,如果他们被安排在6所学校中的每一所,他们的extro预测值。请注意,这是一个非常简单的模拟,只是使用了固定效应的平均值和随机效应的条件模式,并没有进行复制或抽样。
qplot(school, yhat, data = simDat) + facet_wrap(~case) + theme_dpi()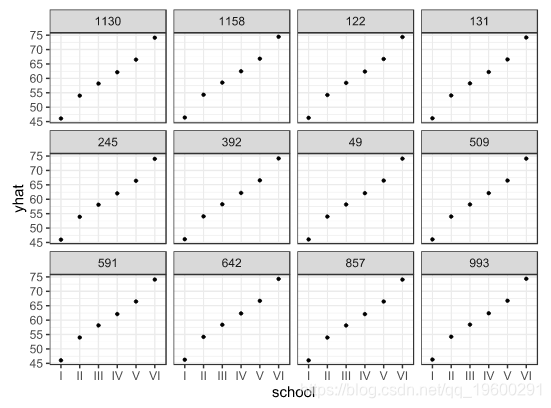
这张图告诉我们,在每个图中,代表一个案例,不同的学校有很大的变化。因此,把每个学生移到不同的学校,对外向性得分有很大的影响。但是,每个案例在每个学校都有差异吗?
+ facet_wrap(~school) + theme_dpi() + theme(axis.text.x = element_blank())
在这里,我们可以清楚地看到,在每所学校内,案例相对相同,表明群体效应大于个体效应。
这些图在以实质性的方式展示群体和个体效应的相对重要性方面很有用。甚至还可以做更多的事情来使图表更有信息量,比如提到结果的总变异性,也可以看一下移动群体使每个观察值离其真实值的距离。- 您还可以看一下 陈堰平老师的R语言数据分析入门课程中的 数据可视化小节, 巩固相关知识点