python y刻度文字前怎么标注颜色
水平柱状图y轴刻度标签为文字,是否可以在刻度标签前显示bar的颜色

- 文章:python绘制横向水平柱状条形图Bar 中也许有你想要的答案,请看下吧
- 除此之外, 这篇博客: Python爬虫:短视频平台无水印下载(上)中的 西瓜视频 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
对于西瓜视频来说,既有安卓端的APP,也有网页版的主站。
但是呢,经过我的观察与验证发现,无论是哪个平台,请求资源的链接都是一样的,举个例子:
https://v.ixigua.com/J4wB5ek/ 】在安卓端拿到的分享链接:【
与在浏览器端拿到的链接:【https://www.ixigua.com/6873787245292159495/】
其实是定向到了同一个链接下:https://www.ixigua.com/6873787245292159495/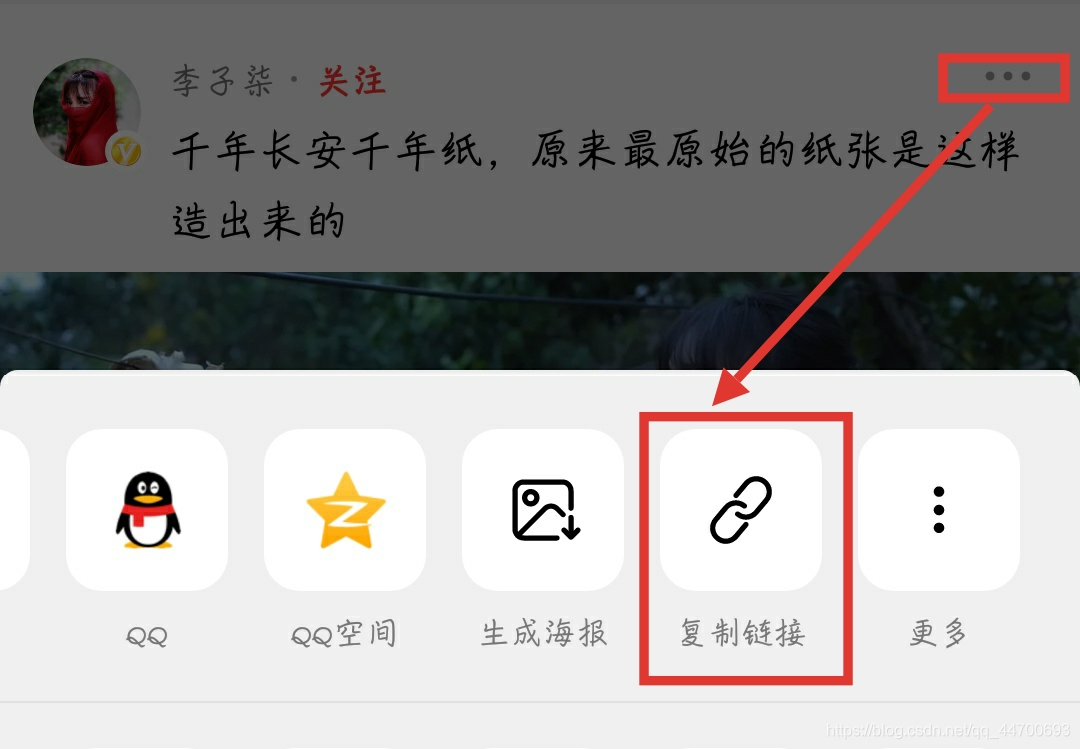
其实说白了就是,在安卓端拿到的分享链接是一个短的映射链接,而在浏览器地址栏显示的才是映射到的真正的地址链接,(不知道我说明白没有哈哈~~)在我明白了以上的对应关系之后,我又发现了一个有用的信息,那就是:
APP端和电脑网页端在线播放时,视频本身就是加载的无水印的链接,而当我们用手机浏览器打开时会发现,即使是在线观看,也是有水印的视频。
知道了这些,那我们就可以确定,我们的请求头中 user-agent 字符,不能是手机的了。
既然APP端和电脑浏览器端都是一样的请求链接,那我们就不用再用APP端来获取链接了,直接再浏览器网页端点击岂不是更香~~
我们先随便点击一个视频打开调试工具:
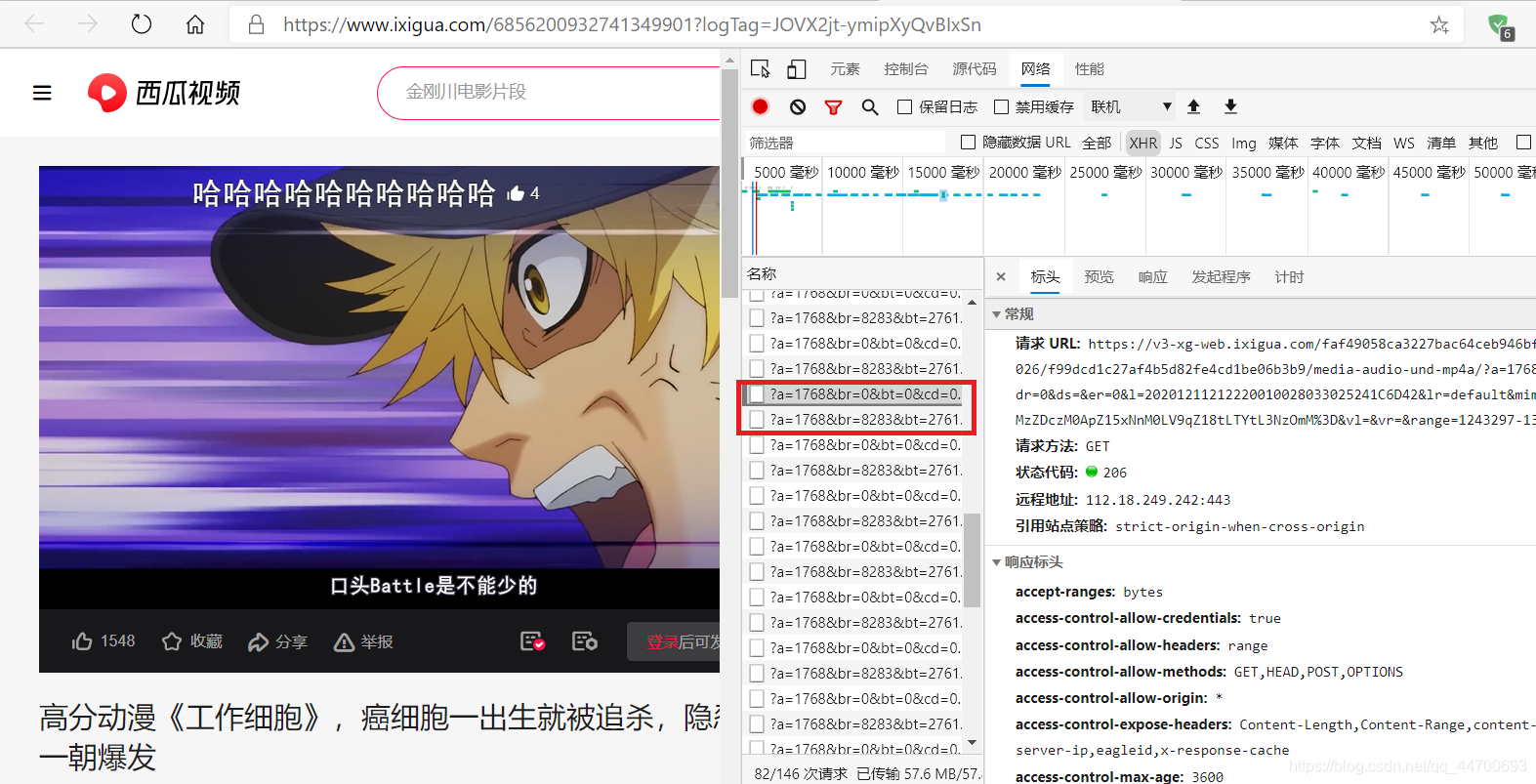
让视频播放几秒钟后发现,网站一直在反复请求两个相识的链接,这是怎么回事呢?有种似曾相识的感觉…没错~~就是和B站的加载机制相同:分别加载音频和视频。
我们先来查看网页源码:找到渲染完成的视频标签的位置后发现:

每个视频都是以 blob:https://… 的形式出现的。那么这条路就是行不通的。
接下来再来看看有没有什么可供使用的接口或者JSON数据,答案是:全都没有。这可就难办了,看着那些请求链接,有很多的参数,不过我发现:链接中的 ? 之后所有字段都不影响我们去请求资源,真正有用的就只有 ? 前面的字段。举个例子:
链接一:https://v3-xg-web.ixigua.com/599d2dfe9869f497674442f1eb94a612/5fd385d0/video/tos/cn/tos-cn-vd-0026/f99dcd1c27af4b5d82fe4cd1be06b3b9/media-video-avc1/?a=1768&br=8283&bt=2761&cd=0%7C0%7C0&cr=0&cs=0&cv=1&dr=0&ds=4&er=0&l=202012112139480100220282230D1D20F6&lr=default&mime_type=video_mp4&qs=0&rc=ajhlc2kzc280djMzZDczM0ApZTg8NTg2Mzw4Nzc1ZTM0ZWdecTZzNC1famdfLS02LS9zcy1hXmMxMGAuY2NfYzQwLjM6Yw%3D%3D&vl=&vr=&range=0-1826
链接二:https://v3-xg-web.ixigua.com/8487c167d9680b36f5b19e039114f30d/5fd385d0/video/tos/cn/tos-cn-vd-0026/f99dcd1c27af4b5d82fe4cd1be06b3b9/media-audio-und-mp4a/?a=1768&br=0&bt=0&cd=0%7C0%7C0&cr=0&cs=0&cv=1&dr=0&ds=&er=0&l=202012112139480100220282230D1D20F6&lr=default&mime_type=video_mp4&qs=0&rc=ajhlc2kzc280djMzZDczM0ApZ15xNnM0LV9qZ18tLTYtL3NzOmM%3D&vl=&vr=&range=0-1743那么中间的那些字段到底是怎么来的呢?我对每个字段进行搜索,结果连一条消息都没有找到,说明这个链接的参数没有在别的地方先生成或者加载。而是直接请求的该链接…
并且后来我发现,同一个视频,浏览器刷新后,参数是会改变的,并非像之前那样是固定生成的链接,所以,我们还得另辟途径~~
在这里,我就不提我遇到的那些坑了,(怕你们笑话,哈哈哈~)
我直接开始解释链接的加载位置。我们打开某个视频的网页源码:
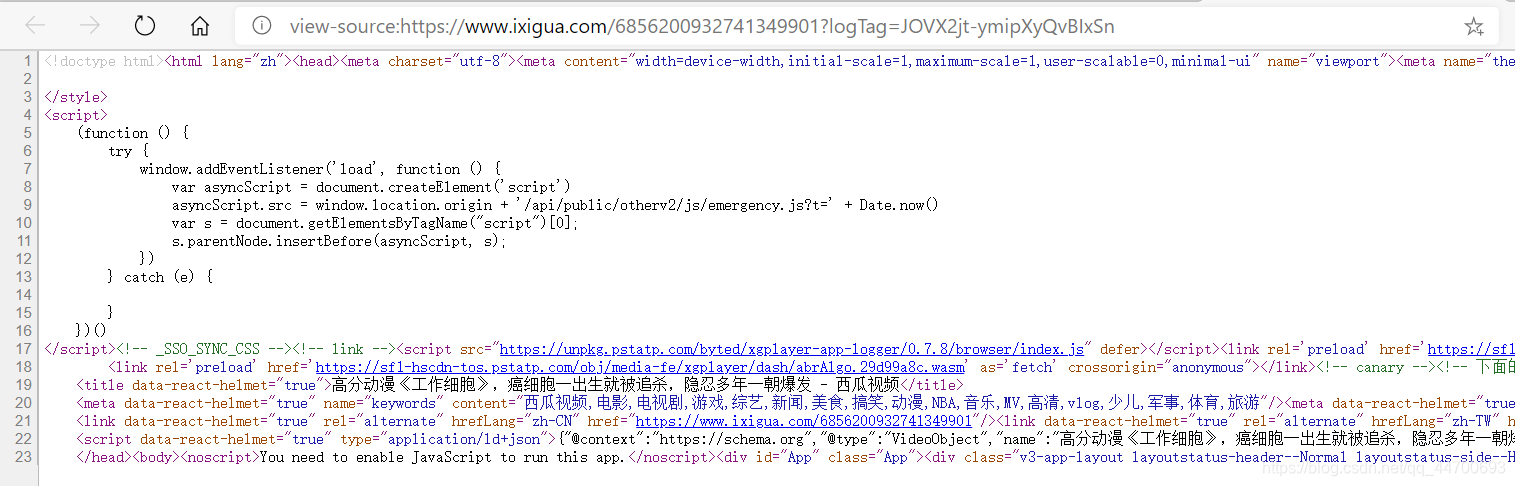
咦~~~~ 只有 23 行数据。不过我们都被骗了~~因为我发现在我浏览器的右下角有个这个东西:
原来有很多数据都被写在了一行… 把滚动条往右一拉,才发现有好多的JSON数据啊,话不多说,我们将之前的视频播放时加载的链接拿来一搜索,结果:
我去,这是怎么回事,我又将全部的网页源码拷贝出来,放在了我的前端编译器上进行格式化:
呵,数据藏得还不少!!!
我从上到下的继续翻看源码,发现,视频的一些信息确实是在这里:
就比如视频的名字:
紧接着我又发现了与视频清晰度相关的一些信息:
那么在这里是不是隐藏这一些视频的请求信息呢?
于是我又继续查找,知道我发现了一些重要的信息:
这…名字取得应该够明白了吧,确实是验证了我们之前所说的,该网站是将视频和音频分开请求的。然后我开始分析每一个参数到底是什么,不过我一眼 就看上了一个参数: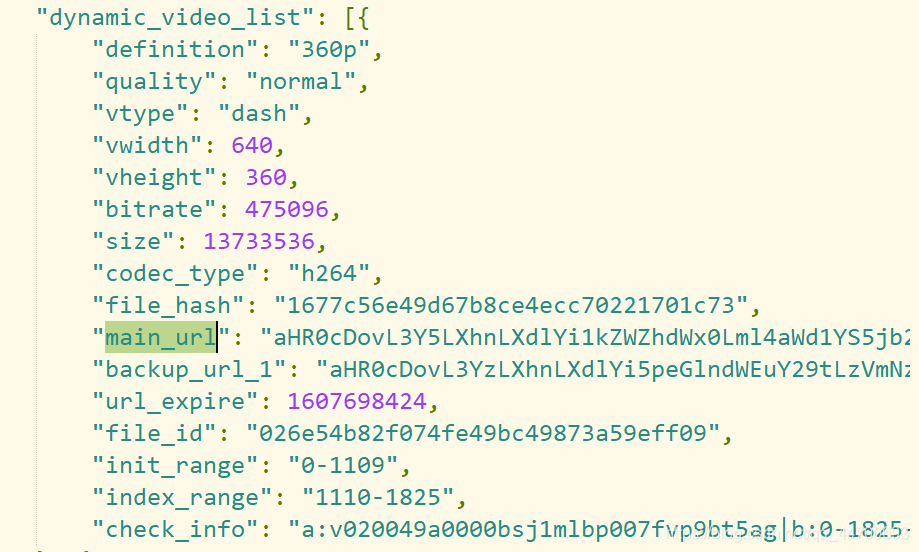
main_url :看到这个 main 我就觉得它不简单,于是我就先拿他下手:"main_url":“aHR0cD…ZyPQ==” (太长了,我就用…代替了)
先拿出一个来看一看,后面的两个等号很熟悉吧,一串字符后面跟着等号,这让我以下就想到了 BASE64 加密,不管怎么说,我们先拿出来验证一下:
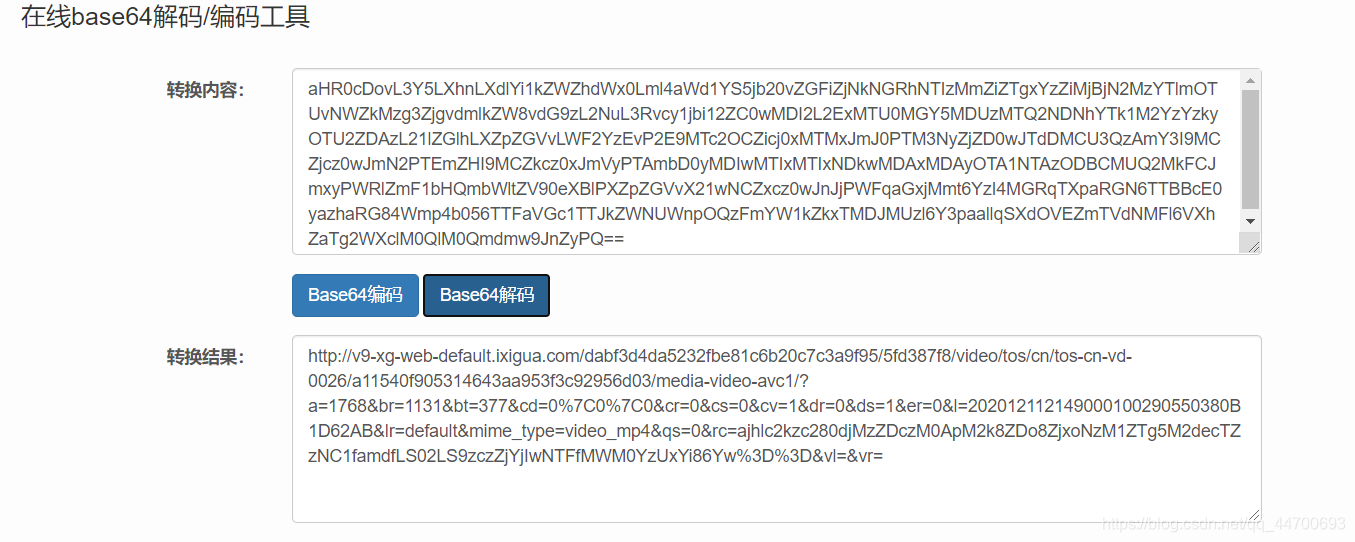
将链接拿到浏览器打开发现,结果还真是我们所要寻找的链接,那么按照这个规矩,音频的链接也是这么提取的,所以我们开始编写代码:class XGSP: main_headers = { 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'cache-control': 'max-age=0', 'sec-fetch-dest': 'document', 'sec-fetch-mode': 'navigate', 'sec-fetch-site': 'none', 'sec-fetch-user': '?1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.55' } def __init__(self, s_url): self.url = s_url def XGSP_download(self): """ CSDN :高智商白痴 CSDN个人主页:https://blog.csdn.net/qq_44700693 """ r = requests.get(self.url, headers=self.main_headers) r.encoding = 'utf-8' video_info = (re.findall('"packerData":{"video":(.*?)}}}},"', r.text)[0] + "}}}}").replace("undefined", '"undefined"') video_json = json.loads(video_info) video_name = video_json["title"].replace("|", "-").replace(" ", "") print("视频名:" + video_name) video_url = base64.b64decode( video_json['videoResource']['dash']['dynamic_video']['dynamic_video_list'][-1]['main_url']).decode("utf-8") print("视频链接:" + video_url) audio_url = base64.b64decode( video_json['videoResource']['dash']['dynamic_video']['dynamic_audio_list'][-1]['main_url']).decode("utf-8") print("音频链接:" + audio_url)注解:
- 细心的朋友应该会发现,按照这个流程写下来的代码,获取到的网页源码全是乱码。那是在浏览器端复制过来的请求头中会有这样的字段:accept-encoding: gzip, deflate, br,但是我并没有写上去,反而在请求分享链接时进行了如下的设置:r.encoding = 'utf-8’,这样才能使网页源码正常爬取。
- video_info = (re.findall(’“packerData”:{“video”: (.*?)}}}},"’, r.text)[0] + “}}}}”).replace(“undefined”, ‘“undefined”’) :为了减少需要再次清晰数据,我们直接用正则表达式提取出视频和音频的链接部分。因为视频不同, video 字段后的一个字段会有所不同,所以我直接拿比较明显的 4 个 **” } “**来截取,然后拼接上。
- base64.b64decode(video_json[‘videoResource’][‘dash’][‘dynamic_video’][‘dynamic_video_list’][-1][‘main_url’]).decode(“utf-8”) :则是base64解码。
现在我们就可以拿到每一次的视频和音频的链接了(我这里以最高的清晰度来作为演示)。
class XGSP: main_headers = { # # 不变 # } video_headers = { 'accept': '*/*', 'accept-encoding': 'gzip, deflate, br', 'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'origin': 'https://www.ixigua.com', 'referer': 'https://www.ixigua.com/', 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-site', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.57' } def __init__(self, s_url): self.url = s_url def XGSP_download(self): """ CSDN :高智商白痴 CSDN个人主页:https://blog.csdn.net/qq_44700693 """ # # 不变 # with open(path + video_name + ".flv", "wb") as f: f.write(requests.get(video_url, headers=self.video_headers).content) print("视频文件下载完成...") with open(path + video_name + "-1.flv", "wb") as f: f.write(requests.get(audio_url, headers=self.video_headers).content) print("音视频均下载完成,即将开始拼接...")现在我们已经下载好了视频和音频,接下来就需要将它们合并为一个视频,既然加载方式和B站很相似,那么下载方式也应该差不多:
Python爬虫:哔哩哔哩(bilibili)视频下载或者直接参考我的代码:
class XGSP: main_headers = { 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'cache-control': 'max-age=0', 'sec-fetch-dest': 'document', 'sec-fetch-mode': 'navigate', 'sec-fetch-site': 'none', 'sec-fetch-user': '?1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.55' } video_headers = { 'accept': '*/*', 'accept-encoding': 'gzip, deflate, br', 'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6', 'origin': 'https://www.ixigua.com', 'referer': 'https://www.ixigua.com/', 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-site', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.57' } def __init__(self, s_url): """ CSDN :高智商白痴 CSDN个人主页:https://blog.csdn.net/qq_44700693 :param s_url: 视频分享链接 """ self.url = s_url def XGSP_download(self): r = requests.get(self.url, headers=self.main_headers) r.encoding = 'utf-8' video_info = (re.findall('"packerData":{"video":(.*?)}}}},"', r.text)[0] + "}}}}").replace("undefined", '"undefined"') video_json = json.loads(video_info) video_name = video_json["title"].replace("|", "-").replace(" ", "") print("视频名:" + video_name) video_url = base64.b64decode( video_json['videoResource']['dash']['dynamic_video']['dynamic_video_list'][-1]['main_url']).decode("utf-8") print("视频链接:" + video_url) audio_url = base64.b64decode( video_json['videoResource']['dash']['dynamic_video']['dynamic_audio_list'][-1]['main_url']).decode("utf-8") print("音频链接:" + audio_url) with open(path + video_name + ".flv", "wb") as f: f.write(requests.get(video_url, headers=self.video_headers).content) print("视频文件下载完成...") with open(path + video_name + "-1.flv", "wb") as f: f.write(requests.get(audio_url, headers=self.video_headers).content) print("音视频均下载完成,即将开始拼接...") video_add_mp3("D:/ffmpeg-2020-09-30-essentials_build/bin/", path, path + video_name + ".flv", path + video_name + "-1.flv") def video_add_mp3(ffmpeg_path, save_path, file1_path, file2_path): """ CSDN :高智商白痴 CSDN个人主页:https://blog.csdn.net/qq_44700693 ffmpeg -i video.mp4 -i audio.m4a -c:v copy -c:a copy output.mp4 视频添加音频 :param ffmpeg_path: ffmpeg的安装 bin 路径 :param save_path: 文件保存路径 :param file1_path: 传入视频频文件的路径 :param file2_path: 传入音频文件的路径 :return: """ mp4_name = file1_path.split('/')[-1].split('.')[0] + '-temp.mp4' mp3_name = file1_path.split('/')[-1].split('.')[0] + '-temp.mp3' outfile_name = file1_path.split('.')[0] + '.mp4' os.system(r'%sffmpeg -i %s %s' % (ffmpeg_path, file1_path, save_path + mp4_name)) os.system(r'%sffmpeg -i %s %s' % (ffmpeg_path, file2_path, save_path + mp3_name)) os.system(r'%sffmpeg -i %s -i %s -c:v copy -c:a copy %s' % ( ffmpeg_path, save_path + mp4_name, save_path + mp3_name, outfile_name)) os.remove(save_path + mp4_name) os.remove(save_path + mp3_name) os.remove(file1_path) os.remove(file2_path)因为不知道原视频的真实格式,所以将视频和音频的格式都手动改为 flv 格式,在合并前进行格式转换。

如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^