关于#elk#的问题,请各位专家解答!(操作系统-linux)
n bind'", "/usr/share/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-input-udp-3.1.3/lib/logstash/inputs/udp.rb:82:inudp_listener'", "/usr/share/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-input-udp-3.1.3/lib/logstash/inputs/udp.rb:56:in run'", "/usr/share/logstash/logstash-core/lib/logstash/pipeline.rb:524:ininputworker'", "/usr/share/logstash/logstash-core/lib/logstash/pipeline.rb:517:in `bloc
- 这篇博客: 【Linux运维架构】------ 搭建 ELK 日志分析系统中的 第四步:创建索引 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
可以直接新建索引:
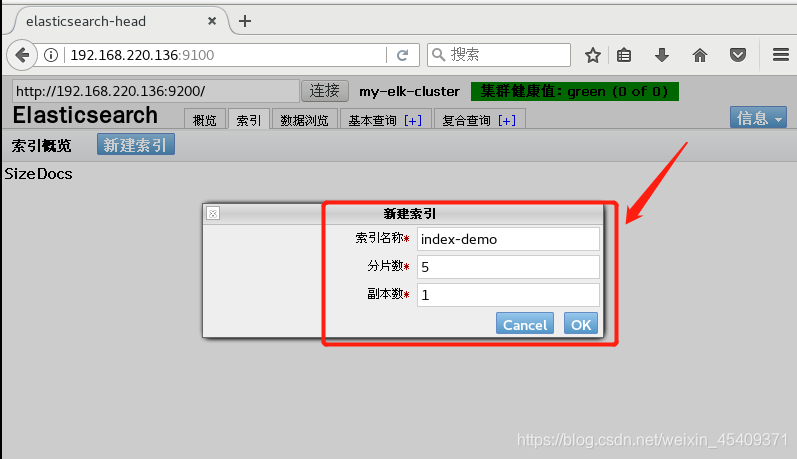
也可以输入以下命令创建索引:curl -XPUT '192.168.220.136:9200/index-demo/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}' //索引名为 index-demo,类型为test
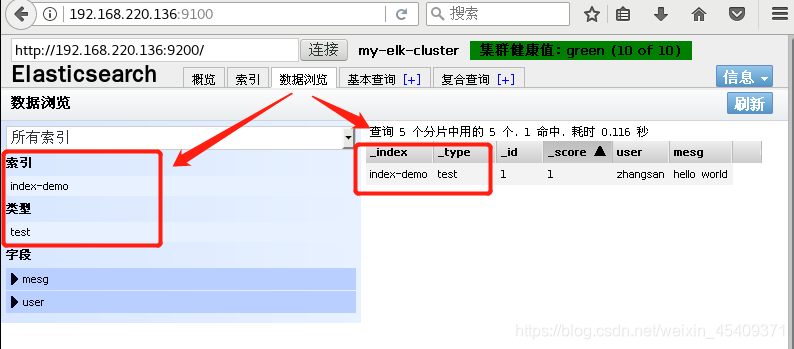
浏览器刷新一下,就会看到刚刚创建的索引信息,可以看出索引默认被分片5个,并且有一个副本。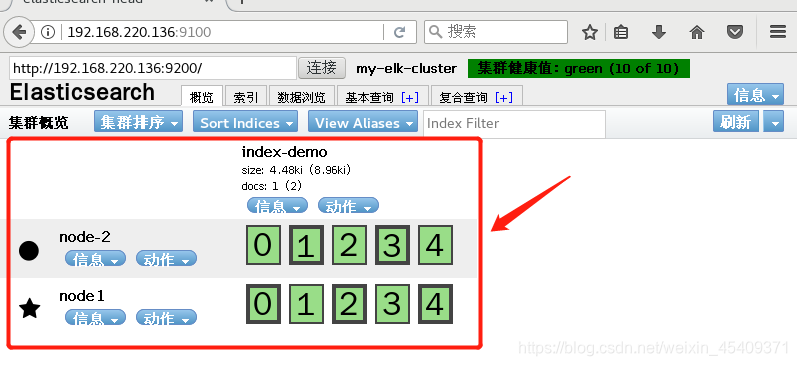
- 以下回答由chatgpt基于相关博客总结生成:
ELK是一个流行的日志管理工具,它由Elasticsearch、Logstash和Kibana三个不同但密切相关的组件组成。在Linux操作系统中,可以通过以下步骤使用ELK:
1.安装Elasticsearch、Logstash和Kibana组件,可以按照官方网站提供的安装教程进行操作。
2.在Logstash中配置input和output插件来读取和写入日志数据。例如,可以使用file input插件来读取一个日志文件,使用elasticsearch output插件将数据写入Elasticsearch集群中。
3.在Kibana中配置index pattern来指定要搜索的索引。这可以是一个通配符模式,例如“logstash-*”来匹配所有以logstash-开头的索引。
4.使用Kibana的搜索和过滤功能来查找特定的日志信息。可以通过在搜索栏中输入关键词或查询语句来进行搜索,并使用过滤器来限制搜索结果的范围。
以下是一个简单的Logstash配置文件示例,用于读取一个日志文件并将数据写入Elasticsearch集群中:
```input { file { path => "/var/log/messages" } }
output { elasticsearch { hosts => ["localhost:9200"] index => "logstash-%{+YYYY.MM.dd}" } }```
这个配置文件中,file input插件会读取/var/log/messages文件中的日志数据,并将其发送到output中。elasticsearch output插件将数据写入Elasticsearch集群中,使用logstash-yyyy.mm.dd的格式作为索引名称,其中yyyy.mm.dd表示当前日期。
关于如何搜索和过滤特定的日志信息,可以在Kibana中使用Query DSL语言编写查询表达式。例如,下面这个查询表达式可以查找包含关键词“error”的日志条目:
message:"error"如果要根据特定字段或范围来过滤搜索结果,可以使用filter子句。例如,下面这个查询表达式可以查找时间戳在特定日期之后的日志条目:
@timestamp: [2019-07-01T00:00:00Z TO *]更多关于查询语句和过滤器的信息可以参考Kibana官方文档。
没看懂。。。你的报错信息不齐全吧。。。