Selector问题
使用Python爬取
https://www.dm5.com/manhua-daojianxiao/
Selector
#detail-list-select-1 > li:nth-child(1) > a
得到文本内容是 第8回 (34P)
但是运行Python, 却多了很多东西. 请指点
'
'第8回 (34P)\n第7回 (34P)\n第6回 (34P)\n第5回 (33P)\n第4回 (40P)\n第3回 (38P)\n第2回 (41P)\n第1回 (43P)\n展开全部章节 setMoreBtn();\n看过《刀剑笑》的人还看过\n刀剑笑狂沙\n刀剑笑狂沙漫画 ,横小弟之子横祸,见先祖几乎代代是大侠,...\n完结第120回\n刀剑笑狂沙\n作者:冯志明\n完结第120回\n刀剑笑狂沙漫画 ,横小弟之子横祸,见先祖几乎代代是大侠,...\n开始阅读\n少年刀剑笑\n少年刀剑笑漫画 ,刀.剑.笑创作至今,已十多年的历史了,而...\n完结第64回\n少年刀剑笑\n作者:冯志明\n完结第64回\n少年刀剑笑漫画 ,刀.剑.笑创作至今,已十多年的历史了,而...\n开始阅读\n刀与剑\n话说从前有个村子,村子里有条好汉叫吴刚,吴刚有点三脚猫...\n最新第2话\n刀与剑\n作者:天狱汉化\n最新第2话\n话说从前有个村子,村子里有条好汉叫吴刚,吴刚有点三脚猫...\n开始阅读\n刀剑神域\n「这虽然是游戏,但可不是闹着玩的。」 \u3000\u3000——「SAO刀剑...\n完结第11话 最终话\n刀剑神域\n作者:川原砾とーか\n完结第11话 最终话\n「这虽然是游戏,但可不是闹着玩的。」 \u3000\u3000——「SAO刀剑...\n开始阅读\n刀剑乱舞\n刀剑乱舞漫画 ,刀剑乱舞的同人合集\n最新第38话\n刀剑乱舞\n作者:多人\n最新第38话\n刀剑乱舞漫画 ,刀剑乱舞的同人合集\n开始阅读\n全部评论 (共有-1条评论) 最热评论\n请您文明上网,理性发言,注意文明用语发表评论\ngetjscallback(\'/wx20190904.js?cid=4932&v=20230609001518&a=17&p=0\',null,\'bb99\',\'0\',\'308\');var h = $("#bb99").width()*1;$("#bb99").css("height",h + "px");addtogroup(308,0, 5965, \'bb99\');\n$(window).scroll(function(){ if($(window).scrollTop() + $(window).height() > $(\'.view-comment\').offset().top + $(\'.view-comment-sub\').height() + 20){ $(\'.view-comment-sub\').css({\'position\': \'fixed\',\'left\': \'50%\',\'margin-left\': \'325px\',\'bottom\': \'20px\'}); if($(window).scrollTop() + $(window).height() > $(document).height() - $(\'footer\').height() - 105){ $(\'.view-comment-sub\').css(\'position\',\'absolute\'); $(\'.view-comment\').css(\'min-height\',$(\'.view-comment-sub\').height() + \'px\'); } }else{ $(\'.view-comment-sub\').css({\'position\': \'relative\',\'left\': \'0\',\'margin-left\': \'0\',\'bottom\': \'0\'}); } });\n报告错误close\nEmail:*\n错误信息描述:\n扫码下载APP\n领取7天VIP(限时)\n上传\n漫画\n登录\n请点击下方图片,旋转至正确方向 换一组\n登录即代表您同意用户协议和隐私政策\n立即登录\n自动登录 忘记密码? 去注册\n其他账号登录\n关于我们 建议与投诉 版权声明\nCopyright (C) 2005-2022 www.dm5.com 动漫屋 All rights reserved\n手机APP\n新浪微博\n (function () { var ga = document.createElement(\'script\'); ga.type = \'text/javascript\'; ga.async = true; ga.src = "//hm.baidu.com/hm.js?fa0ea664baca46780244c3019bbfa951"; var s = document.getElementsByTagName(\'script\')[0]; s.parentNode.insertBefore(ga, s); })(); (function () { var ga = document.createElement(\'script\'); ga.type = \'text/javascript\'; ga.async = true; ga.src =(\'https:\' == document.location.protocol ? \'https://\' : \'http://\') + "w.cnzz.com/c.php?id=30089965"; var s = document.getElementsByTagName(\'script\')[0]; s.parentNode.insertBefore(ga, s); })();//1277928702 var _gaq = _gaq || []; _gaq.push([\'_setAccount\', \'UA-495269-1\']); _gaq.push([\'_setDomainName\', \'none\']); _gaq.push([\'_setAllowLinker\', true]); _gaq.push([\'_trackPageview\']); (function () { var ga = document.createElement(\'script\'); ga.type = \'text/javascript\'; ga.async = true; ga.src = (\'https:\' == document.location.protocol ? \'https://ssl\' : \'http://www\') + \'.google-analytics.com/ga.js\'; var s = document.getElementsByTagName(\'script\')[0]; s.parentNode.insertBefore(ga, s); })(); (function () { var ga = document.createElement(\'script\'); ga.type = \'text/javascript\'; ga.async = true; ga.src = (\'https:\' == document.location.protocol ? \'https://\' : \'http://\')+"w.cnzz.com/c.php?id=30090267"; var s = document.getElementsByTagName(\'script\')[0]; s.parentNode.insertBefore(ga, s); })();//1277928762 var mhruid=0; (function () { var ga = document.createElement(\'script\'); ga.type = \'text/javascript\'; ga.async = true; ga.src =\'https://css122us.cdnmanhua.net/v202303131713/dm5/js/mhrsta.js\'; var s = document.getElementsByTagName(\'script\')[0]; s.parentNode.insertBefore(ga, s); })(); var _hmt = _hmt || []; (function() { var hm = document.createElement("script"); hm.src = "//hm.baidu.com/hm.js?6580fa76366dd7bfcf663327c0bcfbe2"; var s = document.getElementsByTagName("script")[0]; s.parentNode.insertBefore(hm, s); })(); '
- 这篇博客: 简单完整的Python小爬虫教程中的 2.2 获得页面中所需内容的选择器(selector) 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
*本文默认读者已知网页结构。网页一般由三部分组成,分别是 HTML(超文本标记语言)、CSS(层叠样式表)和JScript(活动脚本语言)。
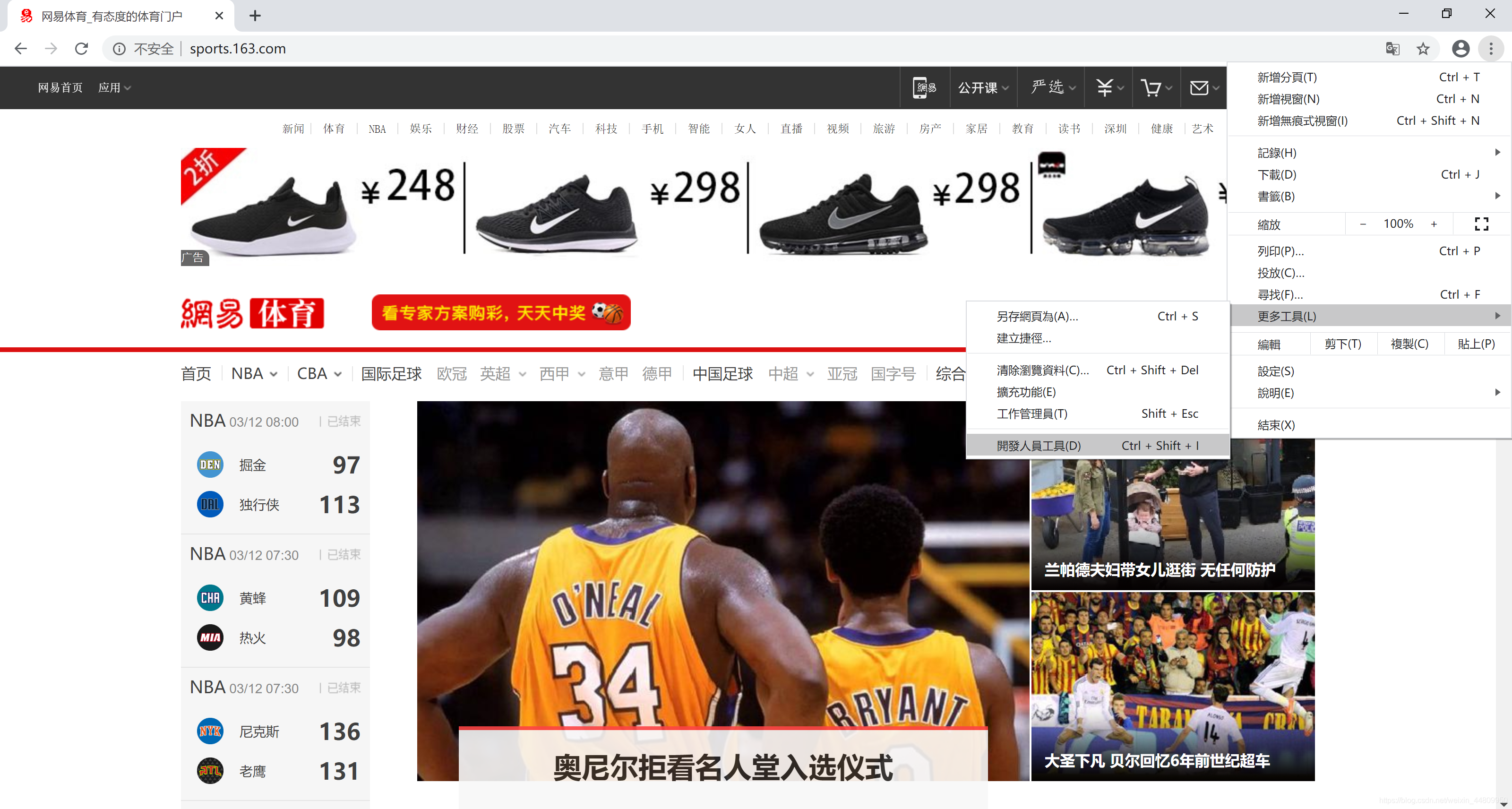
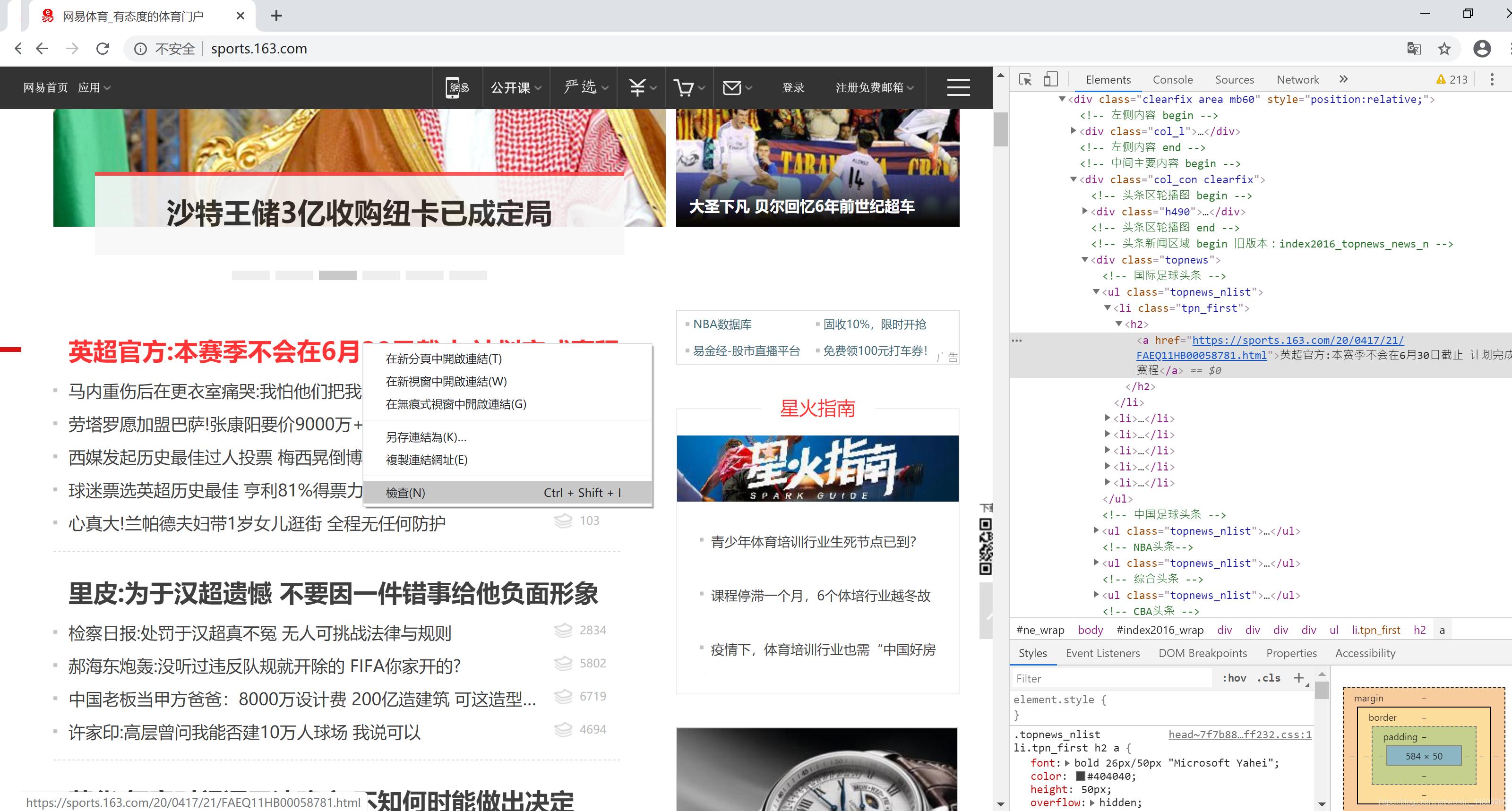
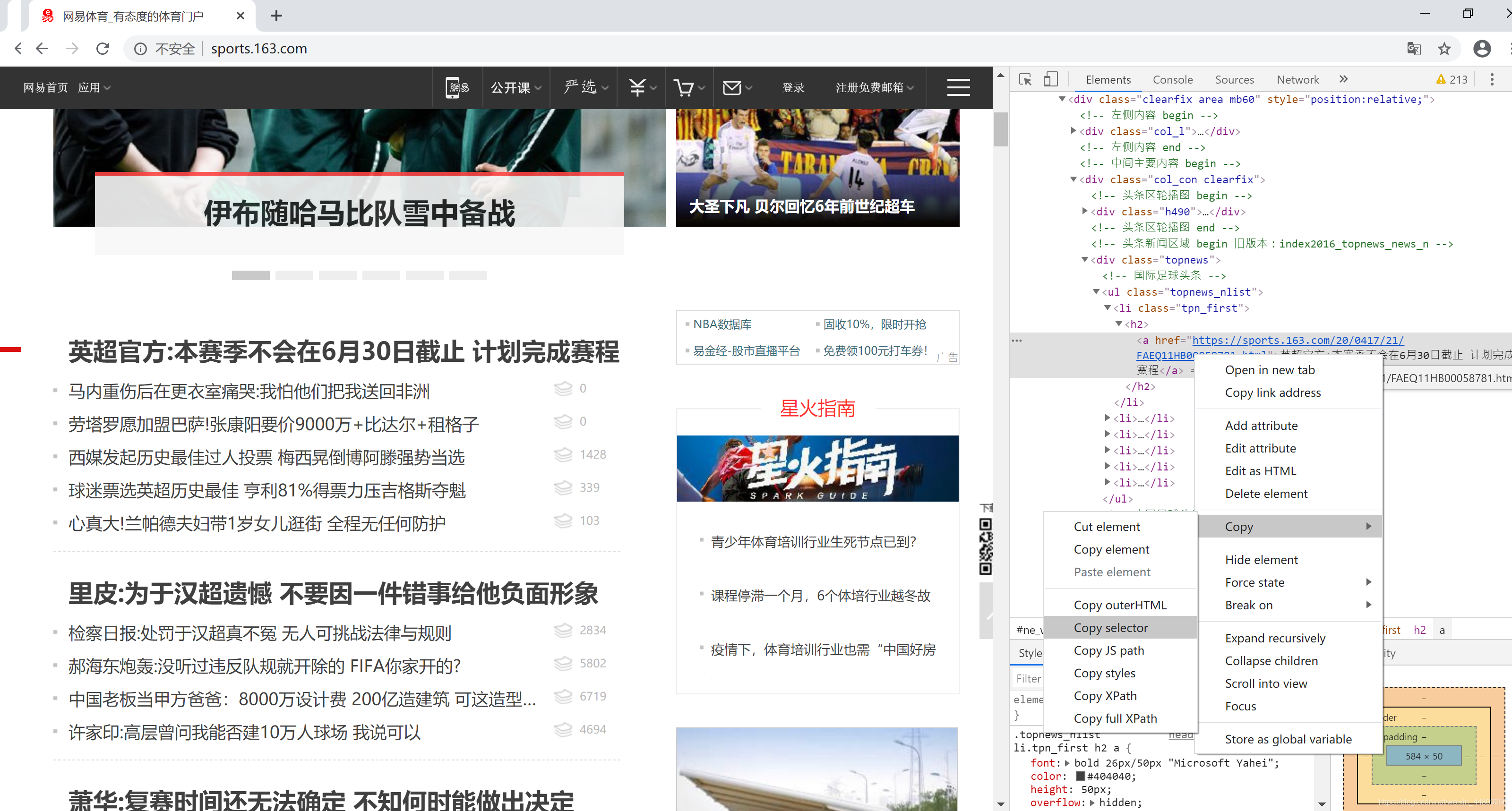
推荐用Chrome浏览器打开网页。点击右上角“自定及管理”按钮,选择“更多工具”菜单,选择“开发人员工具”子菜单,打开网页开发平台。然后在一个网页的所需信息上,右键点击鼠标,弹出浮动菜单选择“检查”。在开发平台上选中的所需信息位置上,右键点击鼠标,弹出浮动菜单选择“Copy”,然后选择“copy selector”,复制所需页面的选择器。整个操作过程如下所示:
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^
可能是因为你使用了不完整的代码或者没有正确处理数据
以下是一个示例代码,可以爬取指定页面的漫画章节名称和图片链接:
import requests
from bs4 import BeautifulSoup
url = "https://www.dm5.com/manhua-daojianxiao/"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
# 获取所有章节链接
chapter_links = soup.select(".tg-list > li > a")
for link in chapter_links:
chapter_url = link["href"]
chapter_title = link.text.strip()
print(chapter_title)
# 进入章节页面
chapter_response = requests.get(chapter_url)
chapter_soup = BeautifulSoup(chapter_response.content, "html.parser")
# 获取所有图片链接
image_links = chapter_soup.select("#cp_img > img")
for image in image_links:
image_url = image["data-original"]
print(image_url)
运行这个代码,应该可以得到每个章节的名称和所有图片的链接
如果你只想获取特定章节的信息,可以修改 url 变量为相应页面的链接