上位机不用给下位机发送指令,下位机会不定时的给我回传数据,那我解析这一块,怎么去写,一直解析吗,求解答
上位机不用给下位机发送指令,下位机会不定时的给我回传数据,那我解析这一块,怎么去写,一直解析吗,求解答
两种方式
1.同步方式,写个线程不停的去读数据,然后判断数据是否完整,完整了就处理,不完整就先缓存,等继续接收数据拼接之后再处理
2.异步方式,数据接收后自动执行回调函数,函数里判断数据是否完整
解析指的上位机的接收数据解析吗?
是一样的,因为我不知道你具体用啥方式“串口”,“tcp”,“udp”
所以我可以用通用抽象描述,因为无论上面那种都是 stream流式接收,所以你采用 异步read就行(含义是有数据来就读,没数据来就等)
那么就不存在你说的“一直解析”的事情,因为没有数据来你只是等着数据来,没有数据来你解析啥?
Stream stream=new MemoryStream();
while (true)
{
var readcout = await stream.ReadAsync(buffer,0);
//下面是解析,没数据来这个就await执行不到下面,也就不存在解析的事情
}
写一个循环一直等数据,数据来了再解析
- 帮你找了个相似的问题, 你可以看下: https://ask.csdn.net/questions/7549494
- 你也可以参考下这篇文章:【动态内存管理】动态内存分配、常见错误、经典笔试题、柔性数组
- 除此之外, 这篇博客: 稳定排序与不稳定排序(插入, 冒泡, 归并, 选择, 快速)排序中的 冒泡排序 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
(内部排序)
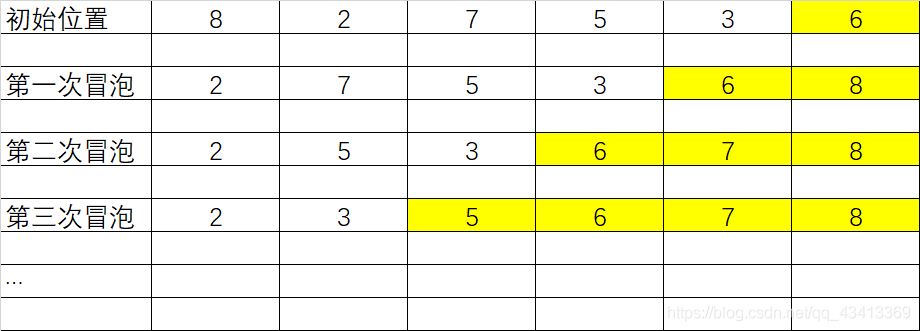
每两两交换一次位置, 比如说第一次冒泡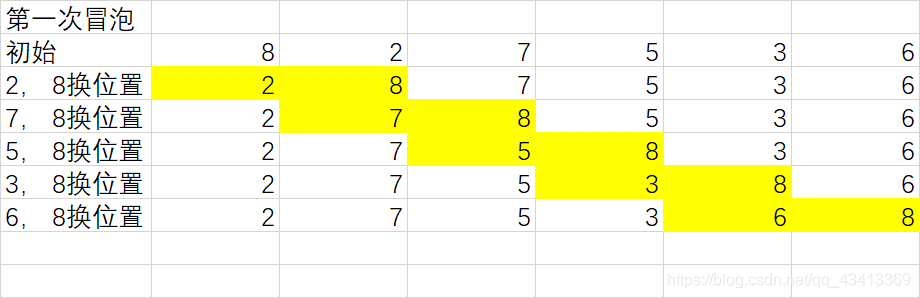
时间复杂度为O(n^2)void bubble_sort(int* num, int n) { for (int i = 1; i < n && times; i++) { for (int j = 0; j < n - i; j++) { if (num[j] <= num[j + 1]) continue; swap(num[j], num[j + 1]); } } return; }第三轮开始可以优化
void bubble_sort(int* num, int n) { int times = 1; for (int i = 1; i < n && times; i++) { times = 0; for (int j = 0; j < n - i; j++) { if (num[j] <= num[j + 1]) continue; swap(num[j], num[j + 1]); times++; } } return; }- 以下回答由chatgpt基于相关博客总结生成:
针对如何解析下位机不定时回传的数据的问题,建议采取以下解析方式:
- 对接收到的数据进行缓存:由于下位机不定时回传数据,不能保证每一次回传都能得到完整的数据,因此可以采用缓存的方式对数据进行存储,等待下一次回传进行拼接。
代码示例:
int cache_size = 1024; //缓存大小为1024字节 char *cache = (char*)malloc(cache_size); //动态分配缓存空间 int data_len = 0; //已缓存的数据长度 //接收数据的代码,假设接收到的数据保存在recv_data中 int recv_len = strlen(recv_data); if (data_len + recv_len > cache_size) { //缓存空间不足,可以进行相应处理 } else { memcpy(cache + data_len, recv_data, recv_len); //将接收到的数据复制到缓存中 data_len += recv_len; }- 解析缓存中的数据:解析方式需要根据具体的数据格式来确定,可以采用字符串操作、正则表达式等方式进行解析。需要注意的是,每次解析时需要判断缓存中的数据是否能够完整解析,如果不能完整解析,先进行缓存,等待下一次解析。
代码示例:
假设数据格式为:数据长度(2字节)+数据内容。以下示例假设数据长度使用网络字节序(大端序)表示。
int header_size = 2; //数据头部长度为2字节 while (data_len >= header_size) { int data_size = ntohs(*(uint16_t*)cache); //解析数据长度, ntohs用于将网络字节序转换为主机字节序 if (data_len < header_size + data_size) { break; //缓存中的数据不足以解析完整内容 } else { char *data = (char*)malloc(data_size + 1); //动态分配存储数据的空间 memcpy(data, cache + header_size, data_size); //复制数据内容到data中 data[data_size] = '\0'; //添加字符串结尾符 //进行后续的数据处理 //... //将已解析的数据从缓存中删除 memmove(cache, cache + header_size + data_size, data_len - header_size - data_size); data_len -= header_size + data_size; } }- 如果数据中含有不可见字符(如二进制数据),可以先将数据进行base64编码,然后进行发送和解码操作。
代码示例:
发送端:
char *data = "hello world"; //要发送的数据 int data_len = strlen(data); char *base64_data = (char*)malloc(base64_encoded_size(data_len)); //动态分配存储编码后数据的空间 base64_encode(data, data_len, base64_data); //对数据进行编码 //将base64_data发送至下位机解析端:
char *base64_recv_data = "aGVsbG8gd29ybGQ="; //接收到的base64编码数据 char *recv_data = (char*)malloc(base64_decoded_size(strlen(base64_recv_data))); //动态分配存储解码后数据的空间 int recv_len = base64_decode(base64_recv_data, recv_data); //对数据进行解码 //对recv_data进行后续处理总体来说,在解析不定时回传数据时,我们需要采取缓存的方式来存储数据,然后根据具体的数据格式采用相应的解析方法进行解析,并且需要判断缓存中的数据是否能够完整解析,如果不能完整解析,则需要等待下一次回传数据进行拼接。如果数据中含有不可见字符,则可以先进行base64编码,发送时解码,接收时再进行解码,以保证数据的完整性和正确性。