关于逻辑关系的解析算法
等号左边是特征,等号右边是值,我准备把每一行的逻辑关系解析出来,我要怎么做呢?有没有专门的类库做这件事情呢?
先谢谢了!
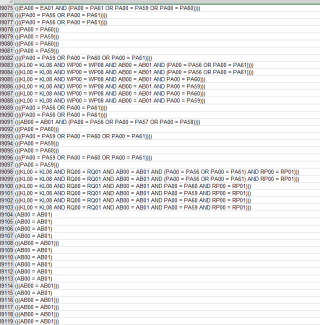
应该查询EVAL函数,字符串的逻辑运算,来解决这个问题!
regex正则表达式库可以,基本上万能提取特征
- 你可以看下这个问题的回答https://ask.csdn.net/questions/993
- 这篇博客也不错, 你可以看下指针是什么?指针怎么理解?怎么理解指针?最简单最通俗的讲解,即使不理解,记住之后也会理解代码,非常有效,希望对你有帮助!
- 您还可以看一下 刘伶华老师的软件测试经典面试题剖析课程中的 你觉得作为一名软件测试工程师,应该要具备什么素质?小节, 巩固相关知识点
- 以下回答由chatgpt基于相关博客总结生成:
我认为你需要使用自然语言处理(Natural Language Processing, NLP)的技术来解析等式中的逻辑关系。具体的解决方案如下:
文本预处理:将等式拆分为左右两个部分,使用分词工具对左右两边进行分词,可以使用Python中的nltk或者spaCy等库来进行分词。
特征提取:将左边的特征和右边的值进行特征提取,可以使用词袋模型或者TF-IDF模型来表示文本特征的重要性,可以使用Python中的scikit-learn库中的CountVectorizer或者TfidfVectorizer来进行特征提取。
逻辑关系分析:可以使用机器学习算法或者深度学习算法来对特征进行分类或者回归,预测特征与值之间的逻辑关系。可以使用Python中的scikit-learn库或者Keras来构建模型,训练模型并进行预测。
输出结果:将预测结果输出并可视化展示,可以使用Python中的matplotlib或者Seaborn等库来进行可视化。
参考代码:
import nltk from sklearn.feature_extraction.text import CountVectorizer from sklearn.model_selection import train_test_split from sklearn.naive_bayes import MultinomialNB import matplotlib.pyplot as plt # 文本预处理 eq = "feature1 + feature2 = value1 + value2" parts = eq.split("=") left = parts[0].strip() right = parts[1].strip() left_tokens = nltk.word_tokenize(left) right_tokens = nltk.word_tokenize(right) # 特征提取 vectorizer = CountVectorizer() feature_matrix = vectorizer.fit_transform([left, right]) feature_names = vectorizer.get_feature_names() X = feature_matrix.toarray() y = [0, 1] # 训练模型并预测 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) clf = MultinomialNB() clf.fit(X_train, y_train) y_pred = clf.predict(X_test) # 可视化展示结果 fig, axs = plt.subplots(1, 2, figsize=(10, 5), sharey=True) fig.suptitle("Logic Relationship Prediction") axs[0].bar(feature_names, X[0]) axs[0].set_title("Left Side") axs[1].bar(feature_names, X[1]) axs[1].set_title("Right Side") plt.show()说明:以上代码仅为示例,仅使用了朴素贝叶斯算法和词袋模型进行特征提取和逻辑关系分析,还可以尝试更复杂的模型和算法,例如深度学习中的循环神经网络(Recurrent Neural Network, RNN)和长短期记忆网络(Long Short-Term Memory, LSTM)。