k——means聚类分析求解答
我用的R15数据集做k_means聚类,也就是将数据分为15个类别
from sklearn.cluster import KMeans
import numpy as np
import pandas as pd
import time
start = time.perf_counter()
data1 = pd.read_table("R15.csv",header= None,sep = ",")
X = np.array(data1)
y1 = pd.read_table("R15_real_result.csv",header= None,sep = ",")
Y = np.array(y1)
n = len(X)
cluster = KMeans(n_clusters= 15 )
cluster = cluster.fit(X)
y_pred = cluster.labels_
save = pd.DataFrame(y_pred)
save.to_csv('R15_y_pred.dat', index = False,header = False)
#改正
y_pred1 = pd.read_table('R15_y_pred.csv', header = None, sep = ',')
y_pred1 = np.array(y_pred1)
"结果分析"
results_kmeans = []
for i in range(0,n):
results_kmeans.append(int(y_pred1[i]))
results_real = []
for i in range(0,n):
results_real.append(int(Y[i]))
# "可视化"
import matplotlib.pyplot as plt
X1 = pd.read_csv('Y_R15.csv',header = None)
n = len(X1)
type1_x = []
type1_y = []
type2_x = []
type2_y = []
type3_x = []
type3_y = []
type4_x = []
type4_y = []
type5_x = []
type5_y = []
type6_x = []
type6_y = []
type7_x = []
type7_y = []
type8_x = []
type8_y = []
type9_x = []
type9_y = []
type10_x = []
type10_y = []
type11_x = []
type11_y = []
type12_x = []
type12_y = []
type13_x = []
type13_y = []
type14_x = []
type14_y = []
type15_x = []
type15_y = []
type_x = []
type_y = []
for i in range(0,n):
if results_kmeans[i] == 0: #根据标签进行数据分类,注意标签此时是字符串
type1_x.append(X1[0][i]) #取的是样本数据的第一列特征和第二列特征
type1_y.append(X1[1][i])
if results_kmeans[i] == 1:
type2_x.append(X1[0][i])
type2_y.append(X1[1][i])
if results_kmeans[i] == 2:
type3_x.append(X1[0][i])
type3_y.append(X1[1][i])
if results_kmeans[i] == 3:
type4_x.append(X1[0][i])
type4_y.append(X1[1][i])
if results_kmeans[i] == 4:
type5_x.append(X1[0][i])
type5_y.append(X1[1][i])
if results_kmeans[i] == 5:
type6_x.append(X1[0][i])
type6_y.append(X1[1][i])
if results_kmeans[i] == 6:
type7_x.append(X1[0][i])
type7_y.append(X1[1][i])
if results_kmeans[i] == 7: #根据标签进行数据分类,注意标签此时是字符串
type8_x.append(X1[0][i]) #取的是样本数据的第一列特征和第二列特征
type8_y.append(X1[1][i])
if results_kmeans[i] == 8:
type9_x.append(X1[0][i])
type9_y.append(X1[1][i])
if results_kmeans[i] == 9:
type10_x.append(X1[0][i])
type10_y.append(X1[1][i])
if results_kmeans[i] == 10:
type11_x.append(X1[0][i])
type11_y.append(X1[1][i])
if results_kmeans[i] == 11:
type12_x.append(X1[0][i])
type12_y.append(X1[1][i])
if results_kmeans[i] == 12:
type13_x.append(X1[0][i])
type13_y.append(X1[1][i])
if results_kmeans[i] == 13:
type14_x.append(X1[0][i])
type14_y.append(X1[1][i])
if results_kmeans[i] == 14:
type15_x.append(X1[0][i])
type15_y.append(X1[1][i])
if results_kmeans[i] == -1:
type_x.append(X1[0][i])
type_y.append(X1[1][i])
"DPC聚类结果"
#plt.scatter(X2[:,0],X2[:,1],alpha=0.2,c=np.array(result2))
fig, ax = plt.subplots()
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
plt.title('(d) k-means',y=-0.15)
"第一聚类划分后结果"
plt.scatter(type1_x,type1_y,c = 'firebrick',s=10,label = 'C1')
"第二聚类划分后结果"
plt.scatter(type2_x,type2_y,c = 'darkorange',s=10,label = 'C2')
"第三聚类划分后结果"
plt.scatter(type3_x,type3_y,c = 'olivedrab',s=10,label = 'C3')
"第四聚类划分后结果"
plt.scatter(type4_x,type4_y,c = 'dodgerblue',s=10,label = 'C4')
"第五聚类划分后结果"
plt.scatter(type5_x,type5_y,c = 'mediumorchid',s=10,label = 'C5')
"第六聚类划分后结果"
plt.scatter(type6_x,type6_y,c = 'deeppink',s=10,label = 'C6')
"第七聚类划分后结果"
plt.scatter(type7_x,type7_y,c = 'darkseagreen',s=10,label = 'C7')
"第八聚类划分后结果"
plt.scatter(type8_x,type8_y,c = 'rosybrown',s=10,label = 'C8')
"第九聚类划分后结果"
plt.scatter(type9_x,type9_y,c = 'sandybrown',s=10,label = 'C9')
"第十聚类划分后结果"
plt.scatter(type10_x,type10_y,c = 'forestgreen',s=10,label = 'C10')
"第11聚类划分后结果"
plt.scatter(type11_x,type11_y,c = 'navy',s=10,label = 'C11')
"第12聚类划分后结果"
plt.scatter(type12_x,type12_y,c = 'slateblue',s=10,label = 'C12')
"第13聚类划分后结果"
plt.scatter(type13_x,type13_y,c = 'paleturquoise',s=10,label = 'C13')
"第14聚类划分后结果"
plt.scatter(type14_x,type14_y,c = 'navajowhite',s=10,label = 'C14')
"第15聚类划分后结果"
plt.scatter(type15_x,type15_y,c = 'khaki',s=10,label = 'C15')
plt.scatter(type_x,type_y,c = 'k',s=10)
plt.legend(loc=[1,0])
plt.show()
出以下错误,请问是什么原因导致的

报错信息:"list index out of range" 意思是索引超出了列表的范围。这通常是因为你试图访问列表中不存在的索引导致的。
例如,如果你有一个列表 a = [1, 2, 3],然后你试图访问 a[3],会出现"list index out of range"错误,因为列表中只有三个元素,索引从0开始,最大索引为2.
这种错误通常是因为程序没有足够的检查来确保索引是合法的,或者是因为程序没有正确处理边界情况而导致的。
- 这篇博客: 关于K-means的通俗理解中的 1、K值的选定 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
对于二维的数据,我们还能通过肉眼观察法进行确定,超过二维的数据怎么办?
拍脑袋法
将样本量除以2再开平方出来的值作为K值,具体公式为: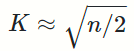
肘部法则
此种方法适用于 K 值相对较小的情况,当选择的k值小于真正的时,k每增加1,cost值就会大幅的减小;当选择的k值大于真正的K时, k每增加1,cost值的变化就不会那么明显。这样,正确的k值就会在这个转折点,类似elbow的地方。具体公式: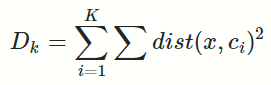

间隔统计量
轮廓系数
Canopy算法
ok这里只做前两个了解,感兴趣的朋友可自行深入了解哈。详情可见:链接: https://www.biaodianfu.com/k-means-choose-k.html.