YMIR无法发布yolov4生成的模型,原因是缺少onnx格式的模型文件,解决办法除了转换格式还有什么?
YMIR无法发布yolov4生成的模型,原因是缺少onnx格式的模型文件,解决办法除了转换格式还有什么?
你可以用pychorch重新训练个模型,还能在转onnx给cv调用的
目前我了解的只有转换格式这个方法
- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/7408653
- 除此之外, 这篇博客: Yolov4训练自己的数据集,史上最详细教程(本人多次使用训练,亲测效果不错,小白都可以学会)中的 Yolov4训练自己的数据集,史上最详细教程(本人多次使用训练,亲测效果不错,小白都可以学会。 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
- 代码运行环境Ubuntu18.04+python3.6+显卡1080Ti+CUDA10.0+cudnn7.5.1+OpenCV3.4.6+Cmake3.12.2,详细环境配置安装步骤就不讲解拉,网上教程一大堆。
- 从github克隆下载源码,链接地址:https://github.com/AlexeyAB/darknet
- 训练肯定需要使用GPU加速,那么得打开项目里面的makefile文件修改一些参数的值,1-4、7改为1
makefile前面几行:打开GPU 加速,打开opencv,打开libdarknet.so生成开关
GPU=1 CUDNN=1 CUDNN_HALF=1 OPENCV=1 AVX=0 OPENMP=0 LIBSO=1 ZED_CAMERA=0 # ZED SDK 3.0 and above ZED_CAMERA_v2_8=0 # ZED SDK 2.X编译
在darknet-master目录下运行:cmake.&make -j48下载与训练权重放在主目录下https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.weights
百度网盘: 链接:https://pan.baidu.com/s/16wOHbaa2mG7cTZ_RcGjRnw
提取码:99bl用下面的命令测试一下预训练权重
./darknet如果编译成功则会出现以下信息
usage: ./darknet现在可以测试初始预训练权重效果了
./darknet detect cfg/yolov4.cfg yolov4.weights data/dog.jp
成功则在主目录下出现predictions.jpg 图片为预测后的图片,打开 OPENCV=1的可以直接显示出图片。说明我们的环境配置好了,否则先去配置环境。

5. 训练自己的数据集
–5.1 在主目录下创建yolo-obj.cfg 配置文件。将 yolov4-custom.cfg 中的内容复制到 yolo-obj.cfg里面,并做以下修改。
--5.1.1修改batch=64,修改subdivisions=16(如果显卡是2080TI的,可以把batch设置为96,如果报内存不足,将batch改回64将,或者subdivisions设置为32)
--5.1.2修改max_batches=classes*2000 例如有2个类别人和车 ,那么就设置为4000,N个类就设置为N乘以2000,
--5.1.3修改steps为80% 到 90% 的max_batches值 比如max_batches=4000,则steps=3200,3600
--5.1.4修改classes,先用ctrl+F搜索 [yolo] 可以搜到3次,每次搜到的内容中 修改classes=你自己的类别 比如classes=2
--5.1.5修改filters,一样先搜索 [yolo] ,每次搜的yolo上一个[convolution] 中 filters=(classes + 5)x3 比如filters=21
--5.1.6(可以跳过)如果要用[Gaussian_yolo] ,则搜索[Gaussian_yolo] 将[filters=57] 的filter 修改为 filters=(classes + 9)x3 (这里我没用到,但是还是修改了)
–5.2制作obj.names,在主目录下创建obj.names文件。内容为你的类别 比如人和车 那么obj.names 为如下,多个类别依次往下写person
car–5.3 制作obj.data,在主目录下创建obj.data文件。内容如下
classes= 2 train = ./scripts/2007_train.txt #valid = ./scripts/2007_test.txt #(做测试用的测试txt) valid = ./scripts/2007_val.txt names = darknet-master/obj.name #(找不到的话,可以修改为自己的绝对路径) backup = backup/ # 权重保存的位置–5.4 数据集制作
在scripts文件夹下按如下目录创建VOCdevkit 文件夹,放自己的训练数据。VOCdevkit --VOC2007 ----Annotations #(放XML标签文件) ----ImageSets ------Main ----JPEGImages # (放原始图片)把自己的原始未标注图片和标签信息放入相应文件夹下。–5.5 scripts文件夹下有voc_label.py,打开后修改自己的类别信息,
sets=[ (‘2007’, ‘train’), (‘2007’, ‘val’), (‘2007’, ‘test’)]
classes = [“person”,“car” ] 按自己的类别修改,但是顺序要和obj.name 保持一致,
-5.6 在主目录下创建make_data.py 文件,把如下代码方进去。运行此文件在scripts 文件下生成 3个相应的txt文件,在Main 下生成四个txt文件。
import os import random import sys root_path = './scripts/VOCdevkit/VOC2007' xmlfilepath = root_path + '/Annotations' txtsavepath = root_path + '/ImageSets/Main' if not os.path.exists(root_path): print("cannot find such directory: " + root_path) exit() if not os.path.exists(txtsavepath): os.makedirs(txtsavepath) trainval_percent = 0.9 train_percent = 0.8 total_xml = os.listdir(xmlfilepath) num = len(total_xml) list = range(num) tv = int(num * trainval_percent) tr = int(tv * train_percent) trainval = random.sample(list, tv) train = random.sample(trainval, tr) print("train and val size:", tv) print("train size:", tr) ftrainval = open(txtsavepath + '/trainval.txt', 'w') ftest = open(txtsavepath + '/test.txt', 'w') ftrain = open(txtsavepath + '/train.txt', 'w') fval = open(txtsavepath + '/val.txt', 'w') for i in list: name = total_xml[i][:-4] + '\n' if i in trainval: ftrainval.write(name) if i in train: ftrain.write(name) else: fval.write(name) else: ftest.write(name) ftrainval.close() ftrain.close() fval.close() ftest.close()-5.7运行voc_labels.py文件,在VOC2007文件下生成labels文件,文件夹里包含相应的txt.(现在voc2007文件里多出一个labels 文件夹)

-5.8 开始训练
首先下载预训练权重yolov4.conv.137,放入主目录下。链接:https://pan.baidu.com/s/1yhB8pRcGH84gyRWeNictBA
提取码:gi4d用下面的命令开始训练:
./darknet detector train obj.data yolo-obj.cfg yolov4.conv.137 -map#训练2000此后在之前训练的基础上继续训练(适合中途停止后继续训练)
./darknet detector train obj.data yolo-obj.cfg backup/yolo-obj_2000.weights -map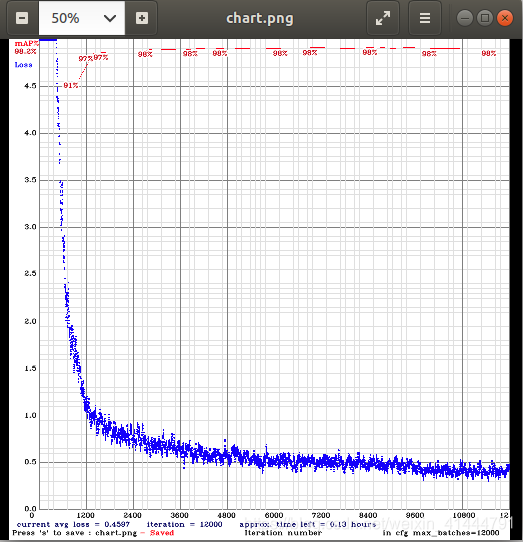 大家可以看到收敛效果还是很明显的,效果扛扛的。不愧是吊打一切的目标检测算法。
大家可以看到收敛效果还是很明显的,效果扛扛的。不愧是吊打一切的目标检测算法。-5.9测试
修改obj.data,
valid = ./scripts/2007_test.txt
#valid = ./scripts/2007_val.txt测试:
./darknet detector map obj.data yolo-obj.cfg backup/yolo-obj_final.weights好了,你竟然认真的看完了,记得点赞收藏,下次观看不迷路,有任何问题欢迎流言私信我。