如何理解POMDP中的状态估计与最优策略的求解?
如题,求解POMDP问题时,一般需要通过贝叶斯理论公式
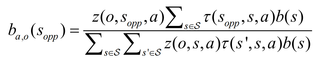
根据上一时刻的动作a、当前时刻的观测状态o、系统可能状态Sopp,计算状态转移概率函数和观测状态概率函数,从而更新置信状态。
看到一种方法是用最大化即时奖励R对应的动作决定策略π,而并非求值函数?这种在线规划算法只需进行一次迭代 ↓
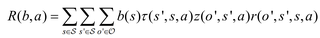
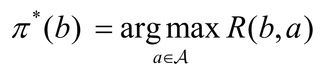
请问这种方法有理论依据吗?
另外,如果从得到的置信状态概率分布b(Sopp)中,贪婪选择其中最有可能(概率最大)的对应的状态,来作为系统的真实状态,从而转换为一个完全可观测的决策规划问题,并用相应领域的一些一般方法来解决,而不是上述的将POMDP动态规划转化为线性规划的方法或者其他POMDP求解算法,请问这种方法又可行吗?
以下内容引用自GPT,有用望采纳:

上述公式描述了使用最大化即时奖励R对应的动作来确定策略π的方法。首先,对于每个置信状态b,根据式子计算在该置信状态下采取各种可能动作带来的即时奖励R(b, a)。然后,从所有动作中选择使R(b,a)最大的那个动作作为最优动作,对应的策略即为π*。使用这种方法可以获得一种启发式的策略,而不需要显式地计算值函数。
这种用最大化即时奖励R对应的动作决定策略π的方法是一种启发式策略,它并没有一个显式的值函数来表示累计奖励。然而,在实践中,这种方法相对简单且易于计算,并且已经得到证明在某些情况下是具有理论优势的。具体而言,这种方法在假设奖励满足一定条件时,可能会以较快的速度收敛到全局最优解。但是需要注意一点,这种方法不能保证获得全局最优解的概率,因此不能够完全替代其他POMDP算法。
至于第二个问题,将得到的置信状态概率分布b(s)中最有可能的状态作为系统真实状态的方法确实可以将POMDP问题转换为一个完全可观测的决策规划问题,从而可以使用一些一般的MDP求解算法来解决。这种方法被称为基于置信状态的搜索。但需要注意的是,由于POMDP中的未知性质,用单个状态来代表整个置信状态是不准确的,因此这种基于置信状态的搜索方法只能提供近似解。当然,这种方法也具有其独特的优点,例如在某些情况下,它可以使用有限的计算资源来获得可接受的近似解,并且可能对于处理POMDP问题中的计算复杂度问题具有一定的优势。
另外,如果采用基于置信状态的搜索方法,则需要先使用POMDP中的观测模型和转移模型计算出某个时刻系统处于所定义的置信状态概率分布b(Sopp)下各个状态出现的概率,然后选择其中概率最大的状态作为当前系统真实状态,从而将POMDP问题转换成一个看似完全可观测的MDP问题。需要注意的是,在实际情况下,并不存在一种叫做“真实状态”的概念,因此使用该方法必须要意识到这种近似可能会引入误差并导致所得结果不太准确。