不知道为什么D对,还有其他为什么不对啊

能解释一下每个选项为什么不对和D选项为什么对吗,为什么D后面要加,
这是规定,A会被当做一个数
- 你可以看下这个问题的回答https://ask.csdn.net/questions/7691591
- 你也可以参考下这篇文章:2022年数维杯国际大学生数学建模挑战赛D题三重拉尼娜事件下极端气候灾害损失评估与应对策略研究求解论文及程序
- 除此之外, 这篇博客: 众包置信度:改进众包数据标记的贝叶斯推断中的 D. 对抗性工人 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
在本实验中,研究了增加对抗性工作人员的效果。恶意的数量从0到40不等,其中40名正常工人和5名专家也在工人队伍中。
在图4中,我们可以看到不同的方法对那些积极试图破坏系统的工人的反应。最大似然法和带置信更新规则的贝叶斯推理即使当工作池由大约35%的敌对工作人员组成时,也能保持其准确性。这5种方法中最糟糕的是加权多数票,随着对手数量的增加,加权多数票迅速下降,当对手占系统的30%左右时,加权多数票的准确率低于多数票模型。投票方法成本的增加可以归因于增加更多的对手而增加了员工人数。值得注意的是,随着对手数量的增加,概率方法在多个测试运行中的结果方差大大增加。这表明这些方法中的标签质量变得更加不稳定,尽管它们通常仍然优于投票方法。
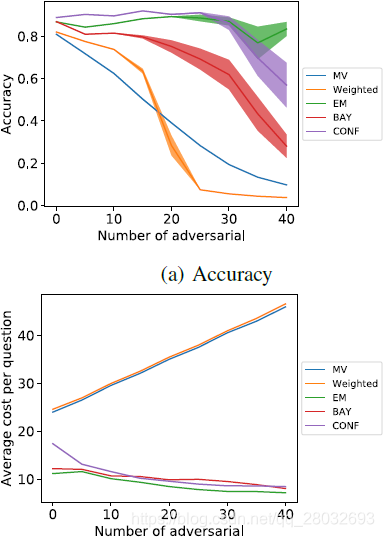
图4:对抗性测试- 您还可以看一下 刘伶华老师的软件测试经典面试题剖析课程中的 工作中有遇到什么困难,怎么解决的?小节, 巩固相关知识点
- 以下回答由chatgpt基于相关博客总结生成:
对于问题所提到的选项正确与错误以及D选项含义,我的回答如下:
A) 动态规划:动态规划是一种在有重叠子问题和最优子结构的情况下优化问题的方法,常用于求解最优化问题。在强化学习中,动态规划的应用主要包括值迭代和策略迭代。动态规划是一种很重要的强化学习算法,但不是因为其引入而使得强化学习具备在利用与探索中寻求平衡的能力。所以这个选项是错误的。
B) Bellman方程:Bellman方程是一组方程,描述了框架强化学习问题中的最优性原理。利用Bellman方程可以求解值函数或者策略函数。在强化学习领域,Bellman方程非常重要,对于证明强化学习算法的收敛性、建立Q-learning等经典算法都有很重要的作用。与选项A一样,选项B也错误。
C) 蒙特卡洛采样:蒙特卡洛法是一种随机方法,对于求解某些与数理统计相关问题具有广泛的应用。在强化学习中,蒙特卡洛法主要用于求解策略值函数,可以通过采样来估计策略值函数的期望。蒙特卡洛方法是一种非常通用的方法,但不是因为其引入而使得强化学习具备在利用与探索中寻求平衡的能力。因此,选项C也错误。
D) 贪心策略:贪心策略是在当前状态下做出的局部最优决策,从而达到全局最优。在强化学习中,贪心策略是一种常用的策略,其直观的想法是在当前状态下只考虑一步,即选择当前可以获得最大收益的动作。对于选项D中提到的需要加后缀的含义,具体来说是指在贪心策略中引入一定的随机性,以避免陷入局部最优解而达不到全局最优,这种策略被称为ε-greedy策略。因此,选项D是正确的。
综上所述,选项A、B和C是错误的,选项D是正确的。同时,需要注意的是D选项需要加后缀的含义是指在贪心策略中引入一定的随机性,以避免陷入局部最优解而达不到全局最优。