机器视觉与图像识别的区别是什么
在与人交流过程中听到了机器视觉与图像识别,感觉二者应该是有区别的。
机器视觉与图像识别在概念及具体实现过程的区别是什么呢?
基本上可以说差不多,前者偏重一个整体的感知,比如说感知空间位置、深度、距障碍的距离,双眼定距等,特别是机器人的场景
后者偏重识别,比如说图像文字识别一类的
该回答引用NewBing
您好,这是Bing。很高兴为您解答。😊
机器视觉与图像识别是两个相关但不相同的概念。根据网上的一些资料,我总结了以下几点区别:
- 机器视觉是指用机器代替人眼来做测量和判断的技术,主要应用于制造业、检验、医疗诊断等各个领域。机器视觉系统通过图像摄取装置将被摄取目标转换成图像信号,传送给专用的图像处理系统,得到被摄目标的形态信息,根据像素分布和亮度、颜色等信息,转变成数字化信号; 图像系统对这些信号进行各种运算来抽取目标的特征,进而根据判别的结果来控制现场的设备动作¹²³。
- 图像识别是指对输入的图像进行分析和理解,从中提取出有意义的信息,如图像中包含的对象、场景、动作、属性等。图像识别是计算机视觉的一个重要分支,也是人工智能的一个核心问题。图像识别一般是用户通过访问,调用API接口提取图像,对图像中的语音或者是文字进行识别:比如超市用的商品条形码、某条街地商户地址及信息,手写文字等¹⁴。
可以看出,机器视觉与图像识别在概念上的区别主要在于:
- 机器视觉更强调对图像的测量和控制,而图像识别更强调对图像的理解和分类。
- 机器视觉更侧重于软硬件结合的系统设计和实现,而图像识别更侧重于算法和模型的研究和开发。
- 机器视觉更多应用于工业领域,而图像识别更多应用于生活领域。
在具体实现过程上的区别主要在于:
- 机器视觉需要考虑图像采集设备、光源、环境等因素的影响,而图像识别一般只需要处理已有的图像数据。
- 机器视觉需要进行精确的标定、校正、配准等操作,以保证测量结果的准确性,而图像识别一般只需要进行一些预处理操作,如去噪、增强、归一化等。
- 机器视觉需要设计合适的特征提取和匹配算法,以适应不同的应用场景和目标,而图像识别一般可以使用通用的特征提取和分类算法,或者使用深度学习等方法自动学习特征。
希望这些信息能够帮助您理解机器视觉与图像识别之间的区别。如果您还有其他问题,请随时提问。😊
源: 与必应的对话, 2023/5/26
(1) 计算机视觉技术与图像识别有何区别? - 知乎 - 知乎专栏. https://zhuanlan.zhihu.com/p/534067368.
(2) 图像处理、机器视觉、机器学习、深度学习,有什么区别呀? - 知乎. https://www.zhihu.com/question/456552069.
(3) 计算机视觉、机器视觉和图像处理,三者之间主要有什么关系?_图像处理、计算机视觉、机器视觉的关系_人工智能爱好者的博客-CSDN博客. https://blog.csdn.net/zhinengxuexi/article/details/88978877.
(4) 机器视觉怎样入门 - 知乎 - 知乎专栏. https://zhuanlan.zhihu.com/p/78441643.
(5) 机器视觉与图像处理技术,你知道哪些? - 知乎专栏. https://zhuanlan.zhihu.com/p/546180868.
- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/7752788
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:图像分类、图像识别和图像检索的区别
- 除此之外, 这篇博客: 仿射变换和透视变换矩阵的参数含义与区别中的 仿射变换 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
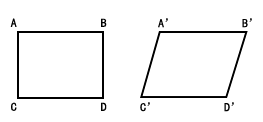
仿射变换是把一个二维坐标系转换到另一个二维坐标系的过程,转换过程坐标点的相对位置和属性不发生变换,是一个线性变换,该过程只发生旋转和平移过程。因此,一个平行四边形经过仿射变换后还是一个平行四边形。
所以,仿射= 旋转 + 平移
仿射变换矩阵为:
其中,(x,y)是原图坐标,(x’,y’)是变换后的坐标;m11,m12,m21,m22为旋转量,m13,m23为平移量。所以仿射变换矩阵实际为2*3的矩阵,以上只是齐次性,为了方便简洁表达旋转和平移,因此,仿射变换为线性变换。在opencv中,实现仿射变换的函数为:
- warpAffine(src,dst,M,(cols,rows))
- src:输入图像
- dst:输出图像
- M:2*3的仿射变换矩阵
- (cols,rows):输出图像的行数和列数
以下用python编程语言,opencv函数库简单实现一下仿射变换,以下程序实现把一张图片顺时针旋转45°,向左平移200个像素点,向下平移30个像素点,该过程的仿射变换矩阵为:
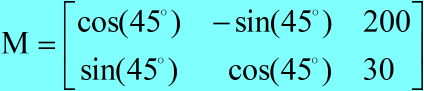
import cv2 as cv import numpy as np src = cv.imread("Google.jpg") rows,cols = src.shape[0:2] M = np.array([[np.cos(np.pi/4),np.sin(-np.pi/4),500],[np.sin(np.pi/4),np.cos(np.pi/4),30]]) #顺时针旋转45度,向左平移200,向下平移30 dst = cv.warpAffine(src,M,(2*cols, 2*rows))#把输出图像的大小改为输入图像的两倍 cv.imshow("src",src) cv.imshow("dst",dst) cv.imwrite("affine.jpg", dst) cv.waitKey(0)输入图像src:

输出图片dst:
- 您还可以看一下 2017CCTC大会老师的【区块链专场】深入理解跨链技术课程中的 深入理解跨链技术小节, 巩固相关知识点
- 以下回答来自chatgpt:
机器视觉和图像识别的区别在于:机器视觉是利用机器代替人眼来进行检测、测量、识别和定位等功能,它的核心是图像处理技术,强调在图像中寻找信息和特征,然后进行分类和识别;而图像识别则是针对图像中的特定物体或场景进行识别和分析。
具体实现过程中,机器视觉一般需要从视频、图片等数据源中,通过图像采集、预处理、特征提取、类别判别等步骤,最终得出识别结果。而图像识别一般是利用深度学习等算法对大量数据进行训练,从而建立识别模型并进行识别。
以上给出的参考代码则是一个利用机器视觉技术实现自动打码的示例,其中使用了OpenCV和face_recognition等库实现了人脸检测和识别,以及视频读取、处理和保存等功能。具体实现过程中,首先通过face_recognition库得到已知人脸的编码,然后利用OpenCV读取视频,并进行人脸检测和对比,在需要打码的位置添加打码图片,最后将处理好的视频保存。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^