不太理解每层代码的含义和要表达的东西

不太明白这个嵌套是如何进行的,每一步对表达的含义不明白是问什么,请求讲解一下
# 读入一个整数 u
u = int(input())
# 读入一个二维列表 A
A = eval(input()) # eval() 函数用于将输入的字符串表示的列表转换为实际的列表对象。
# 定义一个空列表 c
c = []
# 遍历二维列表 A 中的每个元素
for i in A:
# 定义一个空列表 d
d = []
# 遍历当前元素中的每个子元素
for b in i:
# 将当前子元素乘以 u,然后加入列表 d 中
b = b * u
d.append(b)
# 将列表 d 加入列表 c 中
C.append(d) # append() 方法用于将一个元素添加到列表的末尾
# 输出计算结果,这里应该是打印列表 c,而不是打印列表 d
print(c)
每行都加了注释,希望你能采纳
- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/7727400
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:以一元及二元函数为例,通过多项式的函数图像观察其拟合性能;以及对用多项式作目标函数进行机器学习时的一些理解。
- 除此之外, 这篇博客: 爬虫中关于登录以及登录验证码的简单处理方法中的 一,处理没有登录验证的网站。 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
- 1,使用浏览器的检查功能,获取登录表单的属性
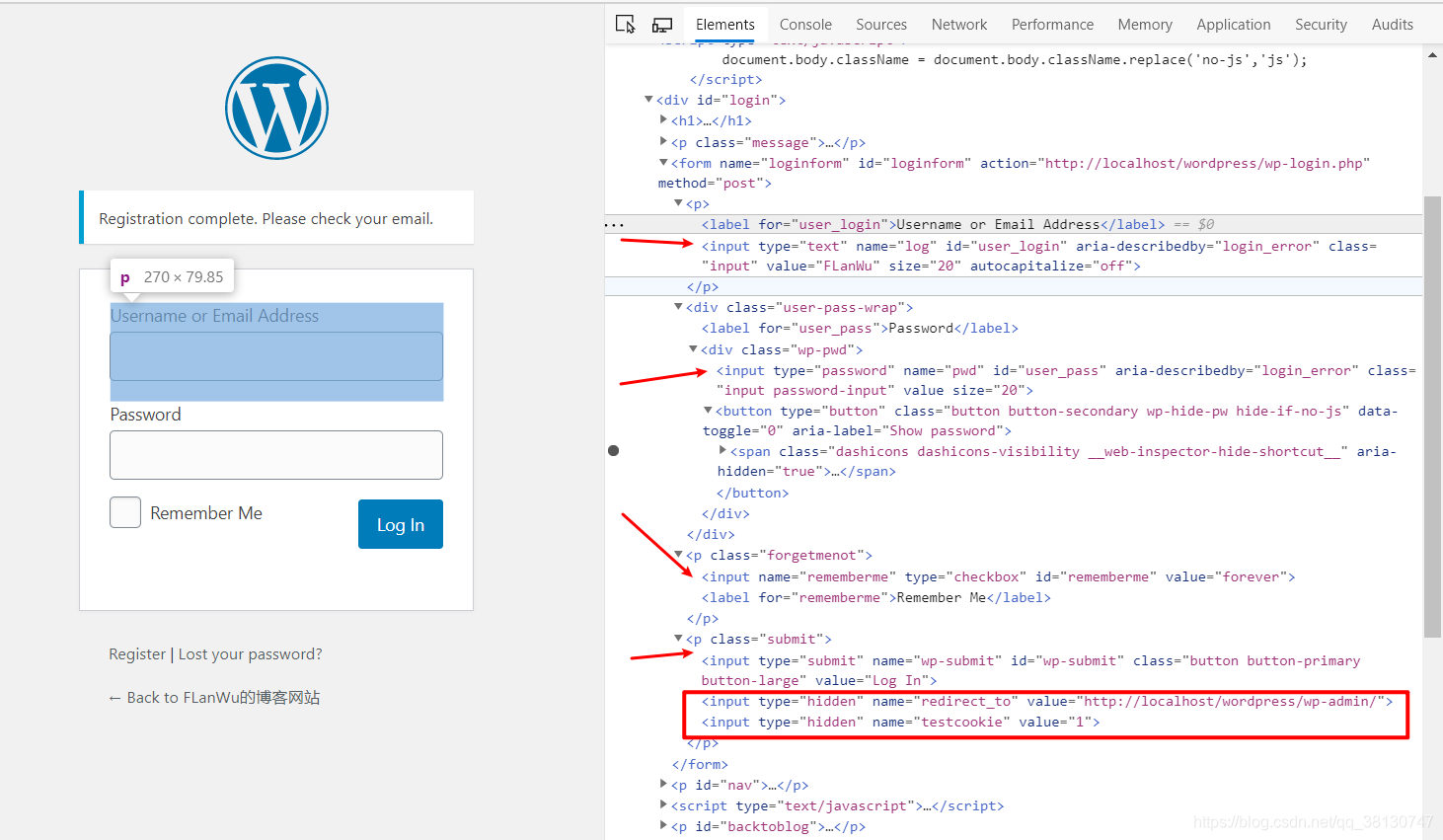
2,查看表单需要提交的name属性,即为我们要post提交的部分,分别为以下属性
- log:账号
- pwd: 密码
- rememberme:记住登录信息,默认值value为forever
- 隐藏标签,hidden:
- redirect_to :值为 http://localhost/wordpress/wp-admin/
- testcookie :值为1
3,找到这些登录信息,即可构造提交表单使用requests进行登录
import requests from bs4 import BeautifulSoup def login_post(url, name, pwd): headers = { 'User-Agent': 'python-requests/2.22.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive' } post_data = { "log": name, "pwd": pwd, "rememberme": "forever", "redirect_to": r"http://localhost/wordpress/wp-admin/", "testcookie": 1, } # 用session保存登录信息,在网站访问期间。 session = requests.session() login_page = session.post(url, data=post_data, headers=headers) # 输出登录状态 print(login_page.status_code) if __name__ == '__main__': url = "http://localhost/wordpress/wp-login.php?loggedout=true&wp_lang=en_US" login_post(url=url,name="FLanWu", pwd="admin123")4,如果最后输出的状态码为200说明登录成功了。若出现4xx,5xx说明有问题,可查找相对应的状态码进行针对性更改。一般是检查属性值或者是其他hidden是否漏写。
- 您还可以看一下 刘建萍老师的人工智能系列课程零基础讲解知识点和实例应用线性回归梯度下降逻辑回归课程中的 讲解机器学中会涉及到的有关数学方面的知识储备有哪些小节, 巩固相关知识点
- 以下回答由chatgpt基于相关博客总结生成:
这段代码主要是实现视频中人脸打马赛克的功能,下面逐行解释:
import cv2 import face_recognition import matplotlib.pyplot as plt import ffmpy3 import subprocess import os from PIL import Image def mask_video(input_video, output_video, mask_path='mask.jpg'): # 读取打码图片 mask = cv2.imread(mask_path) # 读取视频 cap = cv2.VideoCapture(input_video) # 读取视频参数,fps、width、heigth CV_CAP_PROP_FPS = 5 CV_CAP_PROP_FRAME_WIDTH = 3 CV_CAP_PROP_FRAME_HEIGHT = 4 v_fps = cap.get(CV_CAP_PROP_FPS) v_width = cap.get(CV_CAP_PROP_FRAME_WIDTH) v_height = cap.get(CV_CAP_PROP_FRAME_HEIGHT) # 设置写视频参数,格式为 mp4 size = (int(v_width), int(v_height)) fourcc = cv2.VideoWriter_fourcc('m', 'p', '4', 'v') out = cv2.VideoWriter(output_video, fourcc, v_fps, size)这部分代码主要是进行读取视频和设置一些相关参数,如视频的帧率、宽度、高度等。首先通过
cv2.imread函数读取打码图片并保存到mask变量中,然后通过cv2.VideoCapture函数读取待处理的视频,并通过get方法读取视频的帧率、宽度、高度等参数。最后通过VideoWriter函数设置输出视频的格式和相关参数。known_image = face_recognition.load_image_file("tmr.jpg") biden_encoding = face_recognition.face_encodings(known_image)[0]这部分代码主要是读取已知的人脸照片并提取特征编码。通过
face_recognition.load_image_file函数读取已知的人脸照片,并通过face_encodings函数提取人脸的特征编码。cap = cv2.VideoCapture(input_video) while (cap.isOpened()): ret, frame = cap.read() if ret: # 检测人脸 face_locations = face_recognition.face_locations(frame) # print(face_locations) # 对于每一个人脸 for (top_right_y, top_right_x, left_bottom_y, left_bottom_x) in face_locations: unknown_image = frame[top_right_y - 50:left_bottom_y + 50, left_bottom_x - 50:top_right_x + 50] print(face_recognition.face_encodings(unknown_image)) if face_recognition.face_encodings(unknown_image) != []: unknown_encoding = face_recognition.face_encodings(unknown_image)[0] # 对比结果 results = face_recognition.compare_faces([biden_encoding], unknown_encoding) # 是仝卓,就将打码贴图。 if results[0] == True: mask = cv2.resize(mask, (top_right_x - left_bottom_x, left_bottom_y - top_right_y)) frame[top_right_y:left_bottom_y, left_bottom_x:top_right_x] = mask # 写入视频 out.write(frame) else: break这部分代码主要是对视频的每一帧进行处理,检测其中是否存在人脸。对于每一帧中的人脸,通过
face_locations函数检测人脸的位置,并将其作为切片从原始帧中截取出来。然后,通过face_encodings函数提取人脸特征编码,将其与已知的人脸特征编码进行对比,如果匹配,则在打码图片上提取对应大小的区域,并将其覆盖到原始帧的人脸位置上去。最后将处理过的帧写入输出视频中。if __name__ == '__main__': # 将音频保存为cut.mp3 video2mp3(file_name='cut.mp4') # 处理视频,自动打码,输出视频为output.mp4 mask_video(input_video='cut.mp4', output_video='output.mp4') # 为 output.mp4 处理好的视频添加声音 video_add_mp3(file_name='output.mp4', mp3_file='cut.mp3')这部分代码主要是将前面的函数进行调用,并将处理好的视频文件添加音频。通过
video2mp3函数将视频中的音频分离出来并保存到cut.mp3文件中,然后调用mask_video函数对视频进行处理,自动打马赛克,输出视频文件为output.mp4。最后,通过video_add_mp3函数将output.mp4和cut.mp3合并起来,生成最终的视频文件。