java 第 N 个泰波那契数
在力扣提交第 N 个泰波那契数的时候 为什么第一种代码比 第二种使用了 更小的内存 不理解
1.
class Solution {
HashMap<Integer,Integer> val= new HashMap<Integer,Integer>();
public int tribonacci(int n) {
if(n==0){
return 0;
}
if(n<=2){
return 1;
}
if (val.containsKey(n)) {
return val.get(n);
}else{
int a = tribonacci(n-1)+tribonacci(n-2)+tribonacci(n-3);
val.put(n,a);
return a;
}
}
}
2.
class Solution {
public int tribonacci(int n) {
int a =0;
int b=1;
int c= 1;
if(n==0){
return 0;
}
if(n<=2){
return 1;
}
for(int i =3;i<=n;i++){
a=a+b+c;
b=b^c;
c=b^c;
b=b^c;
a=a^c;
c=a^c;
a=a^c;
}
return c;
}
}
第一种和第二种比并不节约内存
只是HashMap<Integer,Integer> val= new HashMap<Integer,Integer>();
的存在,和不用它缓存已经算出的结果的传统递归比,节约了内存。
第一种代码,缓存了之前计算的结果,第二种代码,每次都要从头重新计算,大计算量导致消耗的时间和内存都超过了缓存方式。
第一种代码使用了 HashMap 来存储计算过的结果,避免了重复计算,可以减少内存的使用。
而第二种代码则只是使用了变量来保存每个数的值,没有进行任何缓存,所以在计算较大的n时会占用更多内存,
因为需要保存所有之前的值才能继续计算。
所以第一种代码比第二种代码使用了更小的内存。
另外可以尝试使用一个数组来保存每个数的值,这样就不用使用 HashMap 或者变量来存储计算过的结果了。这种方式比较简单,代码如下:
class Solution {
public int tribonacci(int n) {
if (n == 0) return 0;
if (n <= 2) return 1;
int[] dp = new int[n + 1];
dp[0] = 0;
dp[1] = 1;
dp[2] = 1;
for (int i = 3; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2] + dp[i - 3];
}
return dp[n];
}
}
这种实现方式的时间复杂度和空间复杂度都是 O(n),因为需要保存所有之前的值才能继续计算。但是相比第一种代码,这种方式没有额外的 HashMap 开销,所以可能会稍微快一些。
这两个代码在计算第N个泰波那契数的结果上是相同的,但是第一种代码使用了一个HashMap来存储之前计算过的结果,可以避免重复计算,从而提高了效率。而第二种代码使用了循环来计算,没有使用额外的空间,但需要进行N次计算,算法的时间复杂度较高。因此,第一种代码在时间复杂度和空间复杂度上都优于第二种代码。但是在力扣的测试环境中,可能会受到其他因素的影响,导致第一种代码的内存占用量比第二种更小。所以,具体情况要具体分析。
- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/7663115
- 你也可以参考下这篇文章:(java)三种方法求斐波那契数列的第n项
- 除此之外, 这篇博客: Java旋转矩阵 | 给你一幅由 N × N 矩阵表示的图像,其中每个像素的大小为 4 字节。请你设计一种算法,将图像旋转 90 度。 不占用额外内存空间能否做到?中的 Java题解 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
这道题确实是没想到,看到官方题解才大概明白,建议查看官方题解视频,讲的比较清晰:
大概的意思就是我们可以将整个矩形的二维数组理解成四个部分,我们需要其中每个部分的所有元素都需要一次旋转操作,四个部分操作类似,最终实现整个矩阵的旋转。
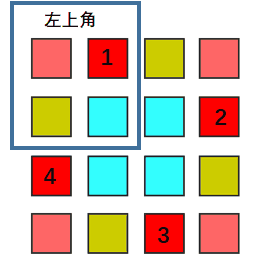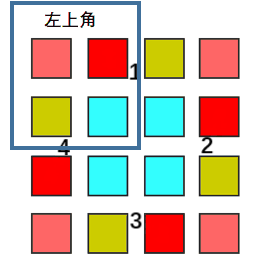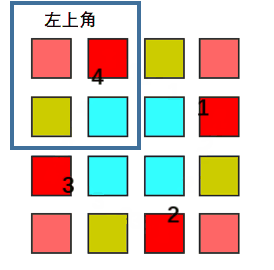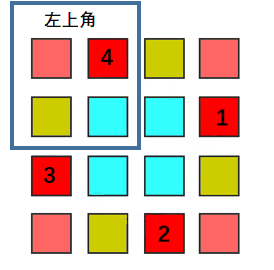
动画演示(来自力扣用户@前额叶没长好) 我们需要的就是确定这个最小旋转单元的大小和旋转的规律,就可以实现原地旋转了。
下面直接给出代码:
class Solution { public void rotate(int[][] matrix) { int n = matrix.length; for (int i = 0; i < n / 2; i++) { for (int j = 0; j < (n + 1) / 2; j++) { int t = matrix[i][j]; matrix[i][j] = matrix[n - j - 1][i]; matrix[n - j - 1][i] = matrix[n - i - 1][n - j - 1]; matrix[n - i - 1][n - j - 1] = matrix[j][n - i - 1]; matrix[j][n - i - 1] = t; } } } }- 您还可以看一下 沙利穆老师的由浅入深学Java课程中的 又来N组数据小节, 巩固相关知识点