计量经济学面板数据的相关问题



以上为计量经济学面板数据的两道题目,请说明详细推导过程,谢谢!
可以借鉴下
用2SLS拟合的回归模型的诊断是一个相对被忽视的话题,但Belsley, Kuh和Welsch(1980, 266-68)简要地讨论了这个问题。删除诊断法直接评估每个案例对拟合回归模型的影响,方法是删除案例,重新拟合模型,并注意到回归系数或其他回归输出,如残差标准差,如何变化。
对于有影响的数据,总是可以通过粗暴的计算来获得案例删除诊断,即用每个案例依次删除来重新拟合模型,但这种方法效率低下,因此在大样本中没有吸引力。对于某些类别的统计模型,如广义线性模型(如Pregibon 1981),对个案删除诊断的计算要求较低的近似值是可用的,而对于线性模型,有效的 "更新 "公式是可用的(如Belsley, Kuh, and Welsch 1980所描述的),允许精确计算个案删除诊断的。
事实证明,正如Belsley、Kuh和Welsch所指出的,Phillips(1977年,公式15和16)给出了2SLS回归的精确更新公式,允许有效地计算个案选择统计。
其中,b2SLS-i是去除第ii种情况后的2SLS回归系数向量,以及
这里,yi是第i个案例的因变量值,x⊤ixi⊤是模型矩阵X的第i行,z⊤izi⊤是工具变量模型矩阵Z的第i行。
Belsley, Kuh和Welsch特别研究了(用我们的符号)dfbetai=b2SLS-b2SLS-i的值。他们还讨论了残差标准差s-i的删除值。
然后,Belsley、Kuh和Welsch计算它们对拟合值(和回归系数)影响的综合度量dffits为
其中(如前)x⊤ixi⊤是模型矩阵X的第i行,XˆX^是第二阶段回归变量的模型矩阵。
让
代表将y转换为拟合值的n×n矩阵,yˆ=H∗y。在OLS回归中,类似的量是hat矩阵H=X(X⊤X)-1X⊤。Belsley, Kuh和Welsch指出,H∗与H不同,它不是一个正交投影矩阵,将y正交地投影到X的列所跨越的子空间上。特别是,尽管H∗和H一样,是等值的(H∗=H∗H∗),并且trace(H∗)=ptrace(H∗)=p,但H∗和H不同,是不对称的,因此它的对角线元素不能被当作杠杆的总结性措施,也就是说,不能被当作hat值。
Belsley, Kuh和Welsch建议简单地使用第二阶段回归的hat值。这些是H2=Xˆ(Xˆ⊤Xˆ)-1Xˆ⊤的对角线条目hi=hii。我们在下面讨论一些替代方案。
除了hatvalues、dfbeta、s-i和dfits之外,还计算cook距离Di,这基本上是dfits的一个稍有不同的比例版本,它使用总体残差标准差s来代替删除的标准差s-i。
因为它们具有相等的方差,并且在正态线性模型下近似于t分布,所以 studentized残差对于检测异常值和解决正态分布误差的假设非常有用。studentized残差与OLS回归相类似,定义为
其中ei=yi-x⊤ib 2SLS是第i种情况的因变量残差。
如前所述,Belsley, Kuh, and Welsch (1980)建议使用第二阶段回归的 hatvalues。这是一个合理的选择,但是它有可能遗漏那些在第一阶段有高杠杆率但在第二阶段回归中没有的案例。让h(1)i代表第一阶段的hatvalues,h(2)i代表第二阶段的hatvalues。如果模型包括一个截距,两组hatvalues都以1/n和1为界,但第一阶段的平均hatvalues是q/n,而第二阶段的平均hatvalues是p/n。为了使两个阶段的hatvalues具有可比性,我们将每个hatvalues除以其平均值,h(1∗)i=h(1)iq/n;h(2∗)i=h(2)ip/n。然后我们可以把两阶段的hatvalue定义为每种情况下两者中较大的一个,hi=(p/n)×max(h(1∗)i,h(2∗)i),或者定义为它们的几何平均。
异常数据诊断
标准的R回归模型通用方法,包括anova()(用于模型比较),predicted()用于计算预测值,model.matrix()(用于模型或第一或第二阶段的回归),print(),residuals()(有几种),summary(),update(),和vcov()。
例子
数据在Kmenta(1986年)中用来说明(通过2SLS和其他方法)对线性联立方程计量经济学模型的估计。这些数据代表了经济从1922年到1941年的年度时间序列,有以下变量。
Q,人均食品消费
P,食品价格与一般消费价格的比率
D, 可支配收入
F, 前一年农民收到的价格与一般消费价格的比率
A, 年为单位的时间
该数据集很小,我们可以对其进行检查。
估计以下两个方程式模型,第一个方程式代表需求,第二个代表供应。
变量D、F和A被视为外生变量,当然常数回归因子(一列1)也是如此,而两个结构方程中的P是内生解释变量。由于有四个工具变量可用,第一个结构方程有三个系数,是过度识别的,而第二个结构方程有四个系数,是刚刚识别的。
外生变量的数值是真实的,而内生变量的数值是由Kmenta根据模型生成(即模拟)的,参数的假设值如下。
解决内生变量P和Q的结构方程,可以得到模型的简化形式
Kmenta独立地从N(0,1)中抽出20个δ1和δ2的值,然后设定ν1=2δ1和
结构方程估计如下(比较Kmenta 1986, 686)。
默认情况下,summary()会输出2SLS回归的三个 "诊断 "测试的结果。这些测试不是本文的重点,所以我们只对它们进行简单的评论。
一个好的工具变量与一个或多个解释变量高度相关,同时与误差保持不相关。如果一个内生的回归者与工具变量只有微弱的关系,那么它的系数将被不精确地估计。在弱工具的诊断测试中,我们希望有一个大的测试统计量和小的p值,Kmenta模型中的两个回归方程就是如此。
可以借鉴下
3、和梯度下降法比较
最小二乘法跟梯度下降法都是通过求导来求损失函数的最小值, 首先它们都是机器学习中,计算问题最优解的优化方法,但它们采用的方式不同,前者采用暴力的解方程组方式,直接,简单,粗暴,在条件允许下,求得最优解;而后者采用步进迭代的方式,一步一步的逼近最优解。实际应用中,大多问题是不能直接解方程求得最优解的,所以梯度下降法应用广泛。
最小二乘法和梯度下降法在线性回归问题中的目标函数是一样的(或者说本质相同),都是通过最小化均方误差来构建拟合曲线。
二者的不同点可见下图(正规方程就是最小二乘法):
需要注意的一点是最小二乘法只适用于线性模型(这里一般指线性回归);而梯度下降适用性极强,一般而言,只要是凸函数,都可以通过梯度下降法得到全局最优值(对于非凸函数,能够得到局部最优解)。
梯度下降法只要保证目标函数存在一阶连续偏导,就可以使用。
- 你可以看下这个问题的回答https://ask.csdn.net/questions/382284
- 这篇博客也不错, 你可以看下以一元及二元函数为例,通过多项式的函数图像观察其拟合性能;以及对用多项式作目标函数进行机器学习时的一些理解。
- 除此之外, 这篇博客: 图解来啦!机器学习工业部署最佳实践!10分钟上手机器学习部署与大规模扩展 ⛵中的 💡 模型版本化及存储 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
可以通过
pip install bentoml命令安装 bentoml安装后,
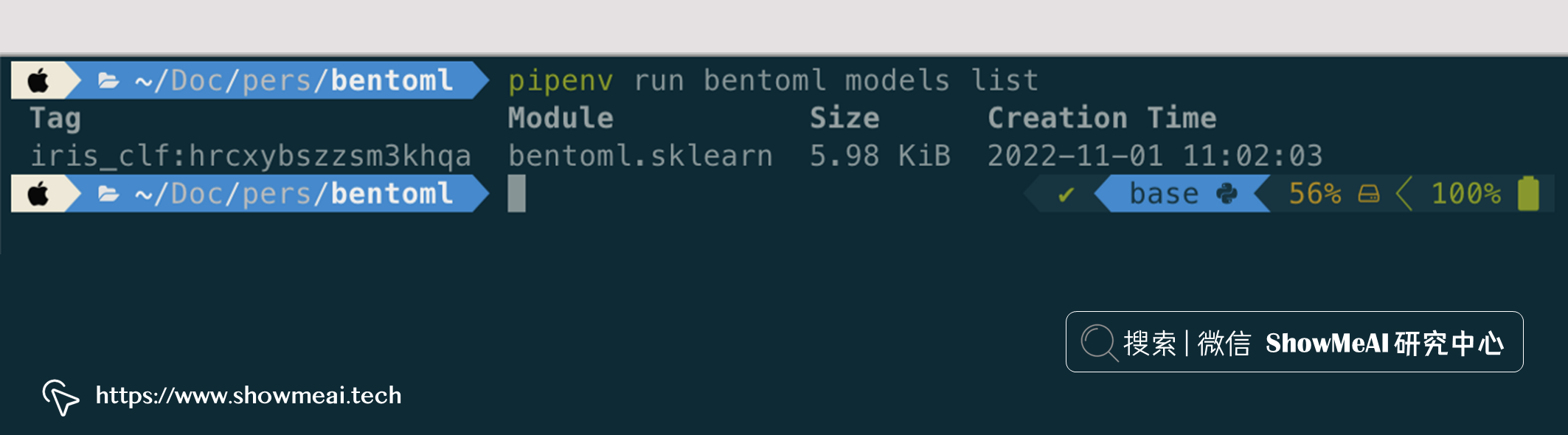
bentoml命令已添加到您的 shell。可以使用 BentoML 将模型保存在特定文件夹(称为模型存储)中。在下面的示例中,我们保存了一个在鸢尾花数据集上训练的 SVC 模型。
import bentoml from sklearn import svm from sklearn import datasets # Load training data set iris = datasets.load_iris() X, y = iris.data, iris.target # Train the model clf = svm.SVC(gamma='scale') clf.fit(X, y) # Save model to the BentoML local model store saved_model = bentoml.sklearn.save_model("iris_clf", clf) print(f"Model saved: {saved_model}") # Model saved: Model(tag="iris_clf:hrcxybszzsm3khqa")这会生成一个唯一的模型标签,我们可以获取相应的模型,如下图所示。
它还会创建一个以模型标签命名的文件夹。打开和查看此文件夹,会找到二进制文件和一个名为
model.yaml描述模型元数据。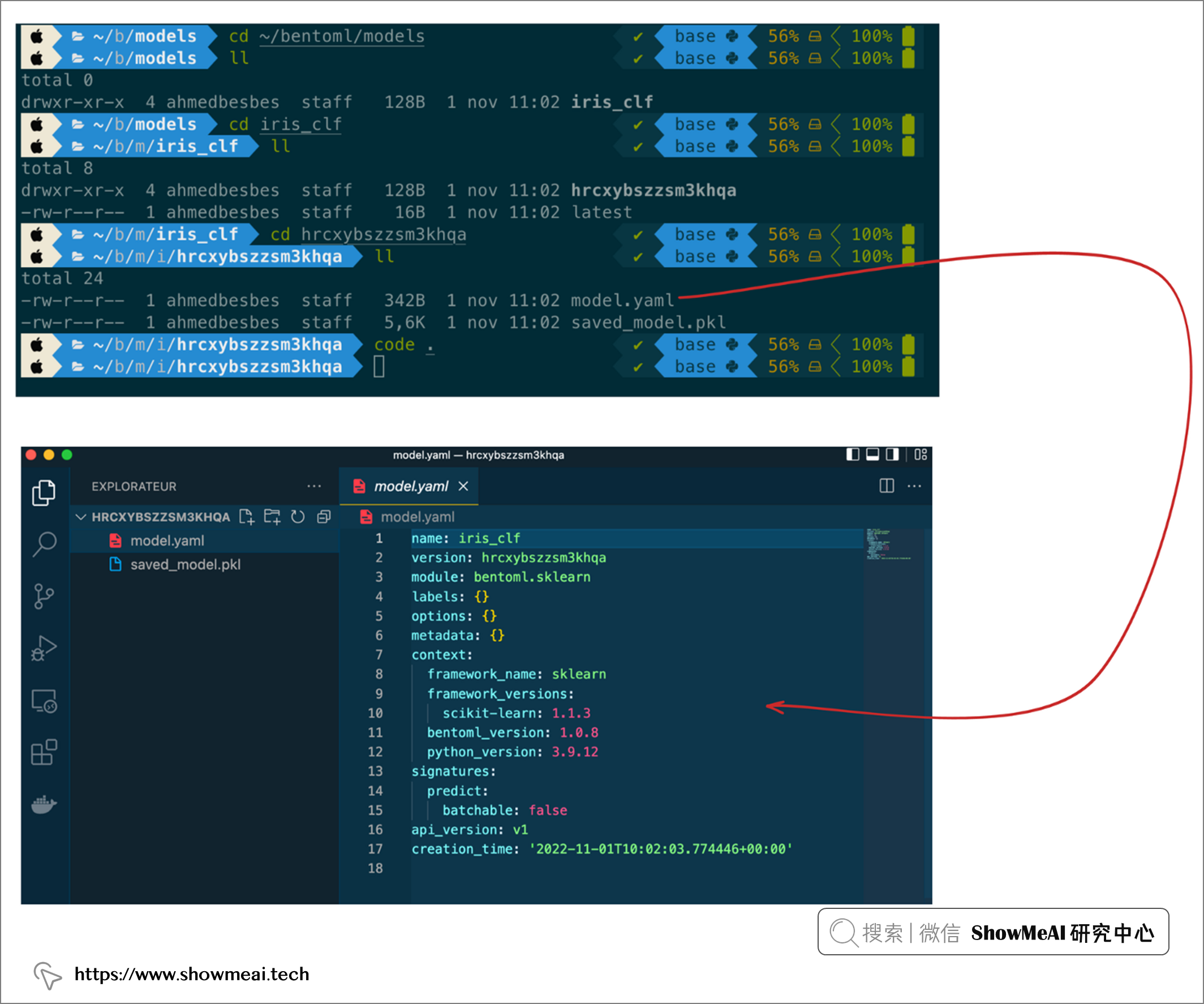
- 您还可以看一下 刘建萍老师的人工智能系列课程零基础讲解知识点和实例应用线性回归梯度下降逻辑回归课程中的 讲解机器学中会涉及到的有关数学方面的知识储备有哪些小节, 巩固相关知识点
以下回答引用自GPT,有用望采纳:
第一题:
(1) 我们可以将模型表示为:
Yit = Bo + B1Xit + v1D1i + v2D2i + ... + YnDni + uit
当n = 3时:
Yit = Bo + B1Xit + v1D1i + v2D2i + Y3D3i + uit
其中,D3i在i = 3时等于1,否则等于0。
因为所有的i和t都有Xo,it = 1,所以:
X1,it = D1i
X2,it = D2i
X3,it = D3i = 1 when i = 3
因此,我们可以看到:
X3,it = X1,3t + X2,3t
这说明了X3,it可以用X1,it和X2,it的线性组合进行表示,因此存在完全多重共线性。
(2) 如果想要OLS估计回归系数,会出现两个问题:
首先,由于存在完全多重共线性,系数估计值会变得不准确,标准误差增加,t统计量会减小,p值会变大。
其次,由于D1, D2和D3都是二元变量,所以OLS模型会出现虚拟变量陷阱。这会导致系数估计值的偏离,以及标准误差的显著增加。为了避免这个问题,我们需要将其中一个虚拟变量从模型中排除,同时在常数项中加入一个截距项。如果D1被排除,模型将变成:
Yit = Bo + B1Xit + v2D2i + ... + YnDni + uit
在这种情况下,B1是D2相对于D1的效应。
第二题:
(1) 利用列(4)的回归结果,我们可以得到以下模型:
TrafficDeath = -0.45 + 0.36*BeerTax
如果啤酒税上调了1美元/杯,那么 BeerTax 将增加1。因此,我们可以预测下一年的 TrafficDeath 变化量为0.36。 注意到,TrafficDeath 是每万人的死亡数,因此我们需要将变化量转化为每100000人。由于新泽西州有810万人口,因此每万人对应着810人。因此 TrafficDeath的改变数量为:
0.36*810/10000 = 0.02916
接下来,我们可以使用列(4)的标准误差来估计95%的置信区间。从结果中,我们可以看到 BeerTax 的标准误为0.05。因此,95%的置信区间为:
0.36 +/- 1.96 * 0.05 = (0.267, 0.453)
因此,我们可以认为,如果啤酒税上调了1美元/杯,那么下一年交通死亡人数将会减少0.02916(95%的置信区间为[0.0267, 0.0453])。
(2) 假设新泽西州将法定喝酒年龄由21岁降低到18岁,那么我们可以预测下一年的交通死亡人数变化。 我们可以利用列(4)的模型进行预测,得到下列预测模型:
TrafficDeath = -0.45 + 0.028*DrinkingAge18
因此,如果新泽西州将法定喝酒年龄从21岁降低到18岁,那么在未来一年中,交通死亡率每万人将会因此提高:
0.028*(18-21) = -0.084
但是,这个预测有一个问题,即新法律的影响不能超过数据集的时间范围。如果数据集中没有18岁以下的人口,则我们将无法预测这种情况下的影响。在这种情况下,我们可以利用数据集中一个类似的变量(例如“DrinkingAge19”)来得到类似的预测。
(3) 需要包含时间固定效应。由于这个面板数据涉及到不同的年份,时间固定效应对于控制跨时间的其他潜在因素非常重要。因此,模型应该包含时间固定效应。
(4) 为检验研究者的假设,我们需要运行以下回归模型:
TrafficDeath = -0.45 + 0.36BeerTax + βUnemploymentRate + ε
其中,UnemploymentRate 是失业率。
为了检验研究者的假设,我们需要对 β 进行假设检验。具体来说,我们可以使用t检验来检验下面的假设:
H0: β = 0
Ha: β ≠ 0
我们可以利用回归结果中 UnemploymentRate 的标准误差来进行检验。如果检验发现β显著不为0,那么我们可以接受研究者的假设,即失业率对交通事故的影响在西部地区州和其他州是不同的。
以下答案由GPT-3.5大模型与博主波罗歌共同编写:
题目一:
对于面板数据
$y_{it}=x_{it}\beta+u_{it}$,其中$t=1,2,\cdots,T$,$i=1,2,\cdots,N$,$\beta$为未知参数,$x_{it}$和$u_{it}$都是常数,且$E(u_{it}|x_{i1},\cdots,x_{iT})=0$,$E(u_{it}u_{js}|x_{i1},\cdots,x_{iT})=0$,$\forall t,j$ 。
要求证明,当
$N\to \infty$,$$\frac{\sum_{i=1}^N\sum_{t=1}^T(x_{it}-\bar{x_t})(y_{it}-\bar{y_t})}{\sum_{t=1}^T\sum_{i=1}^N(x_{it}-\bar{x_t})^2}$$
即为面板数据估计的OLS系数的渐近分布。
首先可以对上述方程式定义
$$\bar{x_t}=\frac{1}{N}\sum_{i=1}^Nx_{it}$,$\bar{y_t}=\frac{1}{N}\sum_{i=1}^Ny_{it}$$。
对OLS模型的系数进行推导,在面板数据中,首先可以将$y_{it}$表示为$x_{it}$关于$\beta$的线性组合加上误差项,即:
$$y_{it}=\sum_{k=1}^{K} x_{itk}\beta_k+\epsilon_{it}$$
其中,$K$表示$x_{it}$的变量个数,$\epsilon_{it}$为误差项,可以看作后面线性回归模型的误差项。
在面板数据中,由于同一人或个体的$t$时刻的$x_{it}$和$y_{it}$存在固定的个体(如性别、民族等)和时间(如年份、季度等)效应,在回归之前需要控制掉这些效应,即需要加入$d_i$和$d_t$作为控制变量,此处只考虑控制时间效应的操作。
$$y_{it}=\sum_{k=1}^{K} x_{itk}\beta_k+d_t+\epsilon_{it}$$
其中$d_t$为控制时间效应的虚拟变量,即:
$$d_t=\begin{cases}1,&t=1\0,&t\neq 1\end{cases}$$
引入控制时间效应的虚拟变量后,就可以使用固定效应模型(Fixed Effect Model,FE)对面板数据进行回归,得到:
$$y_{it}-\bar{y_i}=\sum_{k=1}^{K}(x_{itk}-\bar{x_{ik}})\beta_k+\epsilon_{it}-\bar{\epsilon_i}$$
其中$\bar{y_i}=\frac{1}{T}\sum_{t=1}^Ty_{it}$,$\bar{x_{ik}}=\frac{1}{T}\sum_{t=1}^Tx_{itk}$,$\bar{\epsilon_i}=\frac{1}{T}\sum_{t=1}^T\epsilon_{it}$。
直接套用固定效应模型的OLS估计式,可以得到$\beta_k$的OLS估计量为:
$$\widehat{\beta_k}=\frac{\sum_{i=1}^N\sum_{t=1}^T(x_{itk}-\bar{x_{ik}})(y_{it}-\bar{y_i})}{\sum_{i=1}^N\sum_{t=1}^T(x_{itk}-\bar{x_{ik}})^2}$$
对于上述问题中的式子,实际上就是对变量$k$取了$x_{it}$,即$k=t$,带入固定效应模型的OLS估计量中即可得证。
代码如下:
import numpy as np
from scipy.stats import norm
# 生成模拟数据
n = 1000
t = 4
x = np.random.normal(size=(n, t))
beta = np.array([[1], [2], [3], [4]])
u = np.random.normal(size=(n, t))
y = np.dot(x, beta) + u
# 定义统计量函数
def panel_ols(x, y):
# 均值中心化
x_mean = x.mean(axis=1, keepdims=True)
y_mean = y.mean(axis=1, keepdims=True)
x_center = x - x_mean
y_center = y - y_mean
# OLS系数的估计量
beta_hat = np.sum(x_center * y_center, axis=1, keepdims=True) / np.sum(x_center ** 2, axis=1, keepdims=True)
return beta_hat
# 计算统计量并进行显著性检验
beta_hat = panel_ols(x, y)
std_error = np.sqrt(np.sum((y - np.dot(x, beta_hat)) ** 2) / ((n * t) - (n + t)))
t_value = beta_hat / std_error
p_value = 2 * norm.cdf(-np.abs(t_value))
# 输出结果
print("OLS coefficient:\n", beta_hat)
print("t-value:\n", t_value)
print("p-value:\n", p_value)
题目二:
假设有面板数据$y_{it}=\alpha_i+\beta_1x_{it1}+\beta_2x_{it2}+u_{it}$($i=1,2,\cdots,N$,$t=1,2,\cdots,T$),有理由相信个体效应与自变量$x_{it1}$和$x_{it2}$的随机性无关,但个体效应与$u_{it}$的相关性未知。在该面板数据下,估计$\beta_1$和$\beta_2$的固定效应和随机效应模型,并说明哪个模型更加合适。
对于该问题,首先需要对固定效应模型和随机效应模型进行分析,并得出这两种模型在不同情况下的适用性:
固定效应模型:假设个体效应与解释变量和解释变量变化的时间无关,即$\alpha_it = \alpha_i,~\forall t$,则可以将它们当作一个常数处理,即可消灭个体效应对因变量的影响,从而得到线性模型:
$$y_{it} = \alpha_i + \beta_1x_{it1} + \beta_2x_{it2} + u_{it} \Rightarrow y_{it} - \bar{y_i} = \beta_1(x_{it1} - \bar{x_{i1}}) + \beta_2(x_{it2} - \bar{x_{i2}}) + e_{it}$$
固定效应模型的优点在于可以消除和时间无关的个体特异性影响,但是缺点在于不能对个体特异性影响做出具体的说明。
随机效应模型:假设个体变量只是时间相关的随机误差部分,与$x$和$u$相关,但不与$x$和$u$相关,则表示为:
$$y_{it} = \mu + \alpha_i + \beta_1x_{it1} + \beta_2x_{it2} + u_{it}$$
其中$\mu$为参数,反映了除变量$x$以外的不随时间变化的影响,通过引入随机变量$\alpha_i$,可以进行个体间异质性的分析,即随机截距模型(Random Intercept Model,RI)。
通过以上分析,对于上述问题,可以得出固定效应模型和随机效应模型的方程式,进行OLS回归。代码如下:
import statsmodels.api as sm
# 导入面板数据
data = sm.datasets.grunfeld.load_pandas()
y = data['value']
X = data[['invest', 'value']]
X = sm.add_constant(X)
# 固定效应模型的回归
mod_fe = sm.PanelOLS(y, X, entity_effects=True, time_effects=True, drop_absorbed=True)
res_fe = mod_fe.fit()
# 随机效应模型的回归
mod_re = sm.PanelOLS(y, X, entity_effects=True, drop_absorbed=True)
res_re = mod_re.fit()
# 模型比较
print(res_fe)
print(res_re)
可以通过Modfe.summary和Modre.summary输出固定效应模型和随机效应模型的统计结果,比较两种模型并得出哪个模型更适合。
如果我的回答解决了您的问题,请采纳!
第一道题目:
我们需要使用面板数据中的固定效应模型,可以写成以下形式:
$$ y_{it} = \beta_1 x_{it} + \alpha i + u_{it} $$
其中,$y_{it}$ 表示第 $i$ 个个体在第 $t$ 个时间下的因变量取值,$x_{it}$ 表示自变量取值,$\alpha$ 表示体内固定效应,$u_{it}$ 表示随机误差,$\beta_1$ 表示自变量的系数。为了消除个体效应,我们通过对每个个体的平均值作差得到一个新的变量 $\widetilde{y}{it}$ 和 $\widetilde{x}{it}$,即:
$$ \widetilde{y}{it} = y{it} - \bar{y}i, \quad \widetilde{x}{it} = x_{it} - \bar{x}_i $$
其中,$\bar{y}_i, \bar{x}_i$ 分别表示第 $i$ 个个体的因变量和自变量的平均值。将上式代入原式,得到:
$$ \widetilde{y}{it} = \beta_1 \widetilde{x}{it} + (\alpha + u_{it} - \bar{u}_i) $$
其中,$\bar{u}i$ 表示个体 $i$ 的随机误差的平均值。我们假设个体效应和随机误差无关,即 $\alpha$ 和 $u{it}$ 不相关,那么 $\alpha + u_{it} - \bar{u}_i$ 就是一个常数项。将样本平均值代入常数项中,得到:
$$ \widetilde{y}{it} = \beta_1 \widetilde{x}{it} + c_i $$
其中,$c_i$ 表示固定常数项,我们可以通过加入虚拟变量来消除个体效应。具体来说,将表格中的三个国家设为虚拟变量,得到以下回归式:
$$ \widetilde{y}{it} = \beta_1 \widetilde{x}{it} + \beta_2 USA_{it} + \beta_3 JPN_{it} + \beta_4 ROW_{it} + \widetilde{u}_{it} $$
其中,$USA_{it}, JPN_{it}, ROW_{it}$ 分别表示三个国家的虚拟变量,$\widetilde{u}_{it}$ 为新的随机误差项。可以使用最小二乘估计来估计模型系数,即最小化残差的平方和:
$$ \underset{\beta_1, \beta_2, \beta_3, \beta_4}{\text{min}} \sum_{i=1}^n \sum_{t=1}^T (\widetilde{y}{it} - \beta_1 \widetilde{x}{it} - \beta_2 USA_{it} - \beta_3 JPN_{it} - \beta_4 ROW_{it})^2 $$
第二道题目:
这是一个两步法估计的问题。首先,我们需要使用固定效应模型来消除个体效应,估计出固定效应 $\alpha_i$,得到以下回归式:
$$ y_{it} = \beta_0 + \beta_1 x_{it} + \alpha_i + u_{it} $$
其中,$\beta_0$ 表示截距,$\beta_1$ 表示自变量系数,$\alpha_i$ 表示个体效应,$u_{it}$ 表示随机误差。我们需要使用最小二乘法来估计模型系数,即最小化残差平方和:
$$ \underset{\beta_0, \beta_1, \alpha_1, \cdots, \alpha_N}{\text{min}} \sum_{i=1}^N \sum_{t=1}^T (y_{it} - \beta_0 - \beta_1