pythonfghjk
自定义函数,接收一个参数且此参数必须是列表数据类型,返回一个字典给调用者,此字典的键值对为传入列表的索引及对应的元素
def list_to_dict(lst):
"""
将传入的列表转换为字典,字典的键值对为传入列表的索引及对应的元素
:param lst: 传入的列表
:return: 对应的字典
"""
res_dict = {}
for i in range(len(lst)):
res_dict[i] = lst[i]
return res_dict
# 调用自定义函数
test_list = [1, 2, 3, 4, 5]
result = list_to_dict(test_list)
print(result)
输出结果:
{0: 1, 1: 2, 2: 3, 3: 4, 4: 5}
- 帮你找了个相似的问题, 你可以看下: https://ask.csdn.net/questions/7801641
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:python中函数的默认值参数 ,可变参数,关键字参数之字典拆装 ,关键字参数之列表拆装
- 同时,你还可以查看手册:python- 自定义扩展类型:教程- 基础 中的内容
- 除此之外, 这篇博客: 【Python考试资源】包含重点知识、坑点知识,期末考试看这一份就够了中的 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
1python的创造者是“龟叔”Guido van Rossum
2python语言的缺点
运行速度慢 python是解释型语言(不同于编译型),代码需要翻译成CPU所能理解的机器码。但是,不影响用户交互,因为比如python需要0.1,C需要0.001s,而网络需要1s,1.1s和1.001s没有什么区别 代码不能加密 python只能发布源代码,而C语言是可以只发布.exe文件 3解释器
CPython 官方自带的解释器。是用C语言开发的。在命令行下运行 python就是启动CPython解释器。IPython 在CPython的基础之上发展而来的,只是在交互性方面有所增强 PyPy 采用JIT技术,对python进行动态编译,主要的目的是提高执行速度 Jython 可以在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行 IronPython 在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码
4命令行模式与交互模式
命令模式 直接打开cmd。效果为C:\> _ 交互模式 在cmd中输入python。效果为>>> _ 5如何执行python文件?
在命令模式下在hello.py目录learn下执行以下语句。在交互模式中直接输入代码执行
C:\learn> python hello.py6python常用的库以及用法
科学计算 Numpy,Scipy 数据分析 Pandas 画图 matplotlib 数据挖掘 scikit-learn,nltk,pytorch/tensorflow(深度学习) 游戏 Pygame/Bigworld 图像 PIL 机器人控制 PyRO 1输入与输出
输出:print()
print('hello,world') print('The quick brown fox', 'jumps over', 'the lazy dog')注意,如果采用第二种方式,
print()会依次打印每个字符串,遇到逗号“,”会输出一个空格输入:input()
#注意,是字符串输入 name = input() #可以是有提示的输入 name = input('please enter your name: ') print('hello,', name) #输入两个整数 a,b=map(int,input().split()) #输入两个字符串 a,b=input().split()2数据类型
数据类型 注意点 整数 1十六进制如 oxff01
2_的使用:100000000=100_000000,这是因为方便看0的个数
3没有大小限制
4 3**5=243,表示3^5
浮点数 1如1.23e8
2没有大小限制,超出范围就是inf(无限大)
字符串 1" "与' ':两个都可以使用,但是如果字符串内有'的时候,需要用" "如"I‘m OK’"
2在1的情况也可以用转义字符来解决,如'I\'m OK'
3如果字符串中有很多的字符需要转义,但是我想''中的部分不允许被转义,可以使用r''如下图
4一行内如果有很多的换行符不方便使用,可以使用'''...'''如下图
5不可变有序
布尔值 1True和False
2运算法:and or not
空值 None 列表,
字典,
自定义数据类型
list可变有序 s = ['python', 'java', ['asp', 'php'], 'scheme']
tuple不可变有序 t = (1, 2)
dict可变无序 d={'Anne':96,'Bob':84,'Candy':87}
set可变不可变均可无序 s = set([1, 1, 2, 2, 3, 3])
变量 1 变量名可以是大小写、数字和 _ ,不能用数字开头
2 变量的类型可以反复赋值,以及不同的数据类型。这种变量本身类型不固定的语言称之为动态语言
3 a=‘ABC’,内存做了两件事情,就是创建一个‘ABC’的字符串和创建一个a的变量,并将a指向'ABC'
常量 1 Python中没有完全的常量,一般用大写字符表示
全局变量 1 global 全局变量 总结:字符串和元组合是不可变的,字符串、元组、列表是有序的
print('\\\t\\') print(r'\\\t\\') print('''line1 line2 line3''')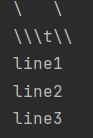
3运算符号
/ 结果一定是浮点数 // 结果一定是整数,向下取整 % 结果一定是整数 结论://和%的结果一定是整数,因此其运算结果一定是精确的
优先级

4字符编码
ASCII 1个字节,只能是常用的几个符号 Unicode 2~6个字节,与ASCII的联系在于,用来表示ASCII是有两个字节,其中前面一个字节是全0,主要作用是显示给用户看 UTF-8 综合了ASCII和Unicode的字节长度,比较灵活,比如英文为1个字节,汉字是3个字节,从而节省空间,主要作用是保存 字符 ASCII Unicode UTF-8 A 01000001 00000000 01000001 01000001 中 x 01001110 00101101 11100100 10111000 10101101
内存:Unicode
外存/浏览器源码/传输数据:UTF-8
5字符串
使用Unicode进行编码
ord() 字符转化为Unicode码,如ord(‘A’) chr() Unicode码转化为字符,如chr(''66) int() 字符数字转化为数值 encode() 字符转化为指定编码的bytes类型,如'ABC'.encode('ascii'),'中文’.encode('utf-8') decode() 字符转化为指定编码的str类型,如b'ABC'.decode('ascii',errors='ignore')#ignore的意思是少量的无效字符忽略,当然也可以不加的 len()
bytes类型计算字节数,str类型计算字符数 字符串名[::-1] 倒序 .islower() 判断是否全部是小写 转化为小写 s.lower() 转化为大写 s.upper() 首单词大写 s.title() 首字符串字母大写 s.capitalize()
>>> len('中文') 2 >>> len('中文'.encode('utf-8')) 6 >>> len('ABC') 3 >>> len(b'ABC') 3 #大小写转换 w = "100hello WORLD" w.upper() Out[72]: '100HELLO WORLD' w.lower() Out[73]: '100hello world' w.title() Out[74]: '100Hello World' w.capitalize() Out[75]: '100hello world'注意:我们从网络或磁盘上读取了字节流,用的就是bytes,由于我们在操作字符串的时候经常遇到str和bytes的互相转化,为了避免乱码,应该坚持使用UTF-8来进行转化,就是encode和decode后面的参数是utf-8。
str是不可变对象
>>> a = 'abc' >>> a.replace('a', 'A') 'Abc' #上面的实际是创建了一个新的对象 >>> a 'abc'解释:对于不变对象来说,调用对象自身的任意方法,也不会改变该对象自身的内容。相反,这些方法会创建新的对象并返回,这样,就保证了不可变对象本身永远是不可变的。
python中的不变对象有:str None
取出特定字符之间的子字符串
#此处为取出[ ]之间的字符串 m=re.findall(r"\[(.+?)\]",L)6格式化
和c语言的输出一样的
%x 十六进制整数
print('%s has %d dollars'%('Tom',100)) print('%s'%(3))#这里的3有没有'都是可以的,因为s是可以自动转化整数为字符串 #指定输出几位以及输出的几位前面需不需要补上0 print('%2d-%02d' % (3, 1)) #输出的小数点数量 print('%.2f' % 3.1415926) #输出带%的时候 print('%d %%' % (7))#format() >>> 'Hello, {0}, 成绩提升了 {1:.1f}%'.format('小明', 17.125) 'Hello, 小明, 成绩提升了 17.1%' #f-string >>> r = 2.5 >>> s = 3.14 * r ** 2 >>> print(f'The area of a circle with radius {r} is {s:.2f}') The area of a circle with radius 2.5 is 19.627特殊数据类型list
列表:一种集合
里面的元素数据类型可以不一样,而且可以套娃,例如
s = ['python', 'java', ['asp', 'php'], 'scheme'] #即为 p = ['asp', 'php'] s = ['python', 'java', p, 'scheme']len() 如len(classmates) a[-1]
a[-2]
获取最后第一个元素
~二~
insert() 插入指定位置如a.insert(1,'jack'),插入到下标为1的位置 append() 末尾追加元素如a.append('Anne') extend() 末尾追加元素列表如a.extend(['Anne','Bob']) pop() 删除尾部的元素如a.pop()
删除指定位置的元素如a.pop(4)
a[2]='dudu' 替换指定位置的元素
sort() 正序排序,如a.sort()
使用lamda自定义排序,如l.sort(key=lambda x:x[1])
reverse() 倒序排序,如a.reverse() index() 获取某个元素的下标如l.index('Anne')
count() 一个元素出现的次数如l.count('Anne') 列表加法 合并追加
[1,2,3]+[5,3] >>> [1,2,3,5,3]
列表乘法 重复几次
[1,2,3]*2 >>> [1,2,3,1,2,3]
实现二维数组
l1=[] i=0 while i<5: l1.append([]) i+=1 l1.append('你好')与random库结合使用
L=[3,4,1,3,4,5,1] #在列表中随机抽取一个对象 random.choice(L) #列表打乱 random.shuffle(L)8特殊数据类型tuple
区别于list:初始化后不可修改
#没有元素时 t = () #1个元素 t = (1,) #2个元素时候 t = (1, 2)注意:如果是1个元素,t=(1)是错误的,因为这样既可以表示tuple又可以表示数学计算的小括号,python默认是后者,因此上述式子相当于t=1
不变指的是指的对象不变,对象的内容有可能变的,那就是list,如下
>>> t = ('a', 'b', ['A', 'B']) >>> t[2][0] = 'X' >>> t[2][1] = 'Y' >>> t ('a', 'b', ['X', 'Y'])9特殊数据类型set
与list相比,只是内部不可以重复
一般是用来当作去重工具使用
>>> s = set([1, 1, 2, 2, 3, 3]) >>> s {1, 2, 3} #print的结果也是{}增 s.add(5) 删 s.remove(4) 并/交 & | 10特殊数据类型dict
字典:存储方式:键-值,方便快速查找。很类似一个二维数组或者指针数组
d={'Anne':96,'Bob':84,'Candy':87} print(d['Anne'])判断键是否存在 1方式一:in
if 'Bob' in d:
print(d['Bob'])方式二:get()
if d.get('Bob'):
print(d['Bob'])2自定义返回值
print(d.get('Bobc','sorry'))增 1直接d['Duduo']=88
删 d.pop('Bob') 获 d['Anne'] 区别:与list相比,其查找插入的速度快,不会随着元素的增加而变慢,但是需要占用大量的内存
11条件控制语句
age = 20 if age >= 18: print('adult') elif age >= 6: print('teenager') else: print('kid') if <条件判断1>: <执行1> elif <条件判断2>: <执行2> elif <条件判断3>: <执行3> else: <执行4>注意:python判断从上至下,一旦一个判断是True,下面的就不会执行了,比如上面的结果是adult
简写形式,类似于switch
if x: print('True')12循环
for...in循环:一般用于遍历
names = ['Michael', 'Bob', 'Tracy'] for name in names: print(name)计算1+2+3+...+100
#range(n)是自动生成0~n的整数序列 #range(101)是从0到100,总共101个数字 sum = 0 for x in range(101): sum = sum + x print(sum) #配合list使用 ls1=[i for i in range(1,101)] print(sum(ls1)) #输出0~100的整数 print(list(range(101)))while循环
sum=0 n=100 while n>0: sum+=n n-=1 print(sum)当然,break和continue也同样适用
13数据类型转换
基本数据类型转化
>>> int('123') 123 >>> int(12.34) 12 >>> float('12.34') 12.34 >>> str(1.23) '1.23' >>> str(100) '100' >>> bool(1) True >>> bool('') Falsestr list dict 类型转化
#list-->str s = ''.join(l) #list-->dict l1 = ['a', 'b', 'c'] l2 = [1, 2, 3] dict(zip(l1,l2)) #str-->list l=s.split(',')适合都是逗号或者空格的 或者 l=list(s) #str-->dict s = '{"id": 1, "name": "li"}' d = eval(s) #dict-->list d = {'a': 1, 'b': 2, 'c': 3} list(d) ## ['a', 'b', 'c'] list(d.keys()) ## ['a', 'b', 'c'] list(d.values()) ## [1, 2, 3] #dict-->str str(d)尤其注意list-->dict的时候
zip的底层原理是遍历赋值,如果l1有重复的字段那就赋l2最后一个值
l1 = ['a', 'b', 'a'] l2 = [1, 2, 3] dict(zip(l1,l2)) ## {'a': 3, 'b': 2} dict(zip(l2,l1)) ## {1: 'a', 2: 'b', 3: 'a'}字符串常见处理
#str类型头尾去掉符号 str2.strip( ',' )1将一个函数名赋值到一个变量
>>> a = abs # 变量a指向abs函数 >>> a(-1) # 所以也可以通过a调用abs函数 12自定义函数
格式 def 函数名(参数):
函数体
def my_abs(x): if x >= 0: return x else: return -x #使用三元表达式 def my_abs(x): return x if x>=0 eles -x注意:如果没有写return,实际也会有return的,也就是None
3空函数
pass:什么都不做,一般用作现在还没想好怎么写,但是先让程序跑起来
def nop(): pass if age >= 18: pass4返回多个值
def hello(x,y): return x,y print(hello(1,2)) #结果为(1,2) a,b=hello(1,2) #获取返回值由结果(1,2)可以知道其实际返回的就是一个tuple
5默认参数的函数
背景:如果我想用同一个函数的不同参数,系统会报错说参数不对。
做法:设置默认参数默认,必选参数在前,变化大的参数在后,例如下
def power(x, n=2): s = 1 while n > 0: n = n - 1 s = s * x return s因此power(5)等价于power(5,2),而且不影响power(5,4)的使用
改变默认参数方法
power(6,n=8)易错知识:默认参数必须指向不变对象
def add(L=[]) L.append('END') return L #对象不是L的情况 >>>add([1,2,4]) [1,2,4,'END'] >>>add([2,2,2]) [2,2,2,'END'] #对象是L的情况 >>>add() ['END'] >>>add() ['END','END']但是这样每次add都会多一个END,我想每次只输出一个END该怎么办呢?
---使用None这个不变对象
def add(L=None) if L is None: L=[] L.append('END') return L6可变参数函数*--可扩展变值
在变量前面加上*
比如要用 a^2+b^2+c^2+... def add(*numbers): sum=0 for n in numbers: sum+=n*n return sum #不变参数的list和tuple也可以变成可变参数,只要在其前面加上* num=[1,2,3,4] add[*num]7关键字参数**--可扩展变值和名称,选填
#name和sex是必选项,00是可选项,也可以进行扩充 #一般用与可选项与必选项 def person(name,sex,**oo): print('name:',name,'sex:',sex,'other',oo) person('a','b',city='北京',age='7') >>> name: a sex: b other {'city': '北京', 'age': '7'} #另外一种表现形式,就是将**oo单独拉出来 ok={'city:':'Beijing','age:':'7'} person('a','b',city=ok['city'],age=ok['age'])8命名关键字参数*--不可扩展值和名称,必填
//只接收city和job作为关键字参数。 def person(name, age, *, city, job): print(name, age, city, job) person('Jack', 24, city='Beijing', job='Engineer')实际应用类似于问卷调查中的是否有其他想法,而且要求是必填的
与关键字参数的不同在于它的关键字的不能扩展也不能修改名字
9小总结
*argc和**kw是python的习惯写法
可变参数 *args,接收、存储的是一个tuple list或tuple func(*(1, 2, 3))
关键字参数 **kw,接收、存储的是一个dict 直接传入 func(a=1, b=2)
dict func(**{'a': 1, 'b': 2})
10递归函数
n! def fact(n): if n==1: return 1 else: return n*fact(n-1)#汉诺塔问题 def move(n,a,b,c): if n==1: print(a,'-->',c) else: move(n-1,a,c,b)#将A上面的n-1个移动到b move(1,a,b,c)#将A底层的1个移动到c move(n-1,b,a,c)#将b上面的n-1个移动到c可能会发生栈溢出,可以使用尾递归优化来解决
11 Iterable
可迭代对象,看能否直接用for循环
isinstance(~,Iterable),结果如下
集合数据 list、tuple、dict、set、strgenerator 生成器、带yield的函数 区别:生成器表达式和列表解析的区别
l=["a"for i in range(10)]
w=(“a” for i in range(10))- 列表解析式的返回结果是一个list而生成器表达式的返回是一个generator
- generator是每次读取部分数据,而list是一次性读取所有的数据,因此在数据量大的时候list会非常的浪费内容
- 生成器最外层是(),列表最外层是[ ]
- 生成器只能遍历一次,列表可以遍历无数次
12常用技巧
切片 获取特定位置的元素 取后10个元素:L【-10:】
每3个取一个:L【::3】
前10个每2个取一个L【:10:2】
tuple和str也可以用
(0,1,2,3,4)【:3】
'ABCDEFG' 【:3】
迭代 for in dict迭代
迭代key for key in d:
迭代value for values in d.values()
迭代key和value for k,v in d.items()
迭代字符串 for ch in 'ABC'
判断能否迭代 isinstance([1,2,3],Iterable)
List实现索引+元素 for i,v in enumerate([1,2,3])
列表生成器 列表数据进行处理
[表达式 for 条件]
1到10的数 [i for i in range(1,11)]
x^x的偶数 [x*x for x in range(1,10) if x%2==0]
全排列 [m+n for m in 'ABC' for n in '123']
for 前面可以有else,但是表示的是表达式,for后面的是过滤条件,不能有else
生成器 根据算法推算出下一个元素,比[]的优势在于不需要大量的存储空间 g=(x*x for x in range(1,11))
for n in g: print(n)
#切片实现去除字符串首尾的空格 def trim(s): l=len(s) if s==l*(' '): return '' else: while s[0]==' ': s=s[1:] while s[-1]==' ': s=s[:-1] return #list表达式 #100以内数字,奇数为负数,偶数为0 [-x if x%2==1 else 0 for x in range(1,11)] #generator函数实现斐波那契数列 def fib(max): n,a,b=0,0,1 while n<max: yield b a,b=b,b+a n+=1 return 'done' print([x for x in fib(6)]) #注意,如果直接输出fib(5)的话会返回一个generator对象 #实际上,每次执行时遇到yield停止,然后下一次的执行送yield的下面开始的 #有yield的标志都是generator函数 #杨辉三角 def triangles(): l=[1] while(True): yield l x=[0]+l y=l+[0] l=[x[i]+y[i] for i in range(len(x))] n = 0 results = [] for t in triangles(): results.append(t) n = n + 1 if n == 10: break for t in results: print(t)1高阶函数
变量既可以指向一个对象也可以指向一个函数,所以函数名可以看成指向一个函数的变量
如def add() m=add
高阶函数:函数的参数可以是另一个函数名
2 map函数
作用,将数值集进行函数计算返回数值集,返回一个generator对象
格式:map(f,l) :f为函数,l为Iterable可循环对象
def f(x): return x*x r=map(f,[1,2,3,4,5]) l=list(r) #list()函数让Iterator对象变成list print(l) #也可以实现与list列表生成器的功能 list(map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9]))3 reduce函数
相当于一个递归函数,每次将前两个参数进行函数计算
#将数字字符串转化为数字 from functools import reduce d = {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9} def strtoint(s): def fn(x,y): return x*10+y def charmnum(s): return d[s] return reduce(fn,map(charmnum,s))#首先将s遍历使用charmnum变成数字list,随后递归相加 print(strtoint('123412'))4 filter()函数
作用:过滤序列
格式:fileter(f,l)f为一个函数,l为Iterable
区别:map主要用于计算,filter主要用于过滤
底层逻辑:将每个Iterable进行计算,True留False丢
5 sorted()函数
实现排序
#正常排序 sorted(L) #倒序 sorted(L,reverse=True) #按照特定内容排序,特定内容可理解为函数,然后对数值有一个返回 #如按照绝对值排序 sorted(L,key=abs) #按照分数排序 L = [('Bob', 75), ('Adam', 92), ('Bart', 66), ('Lisa', 88)] def by_score(t): return t[1] L2 = sorted(L, key=by_score) print(L2)L.sort()和sorted(L)函数的区别
L=[1,5,4,54,5] #sort必须要单独的一行进行排序,print(L.sort())的输出是None L.sort() print(L) print(sorted(L))6匿名函数lambda
作用:表示是一个表达式,也可认为是不需要命名函数的名字,随时随用。如下
list(map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9]))这样我们就不需要单独的写一个函数出来
当然,既然是匿名函数,他本质上还是一个函数,所以也可以赋值给变量上,如下
f = lambda x: x * x总结:可以拿来当做一个工具,和列表表达式一起结合使用
7库
注意:上述的几个函数在Python3中需要导入库functools
8装饰器Decorator
pass
9偏函数
pass
一个.py文件就是一个模块
mycompany.web也是一个模块,它的文件名叫做__init__.py。每个包下面都有这个模块,如果没有的话,python就会把它当做普通的目录而不是一个包。常见的标准模块:string、os、sys、time、re、random(random、randint、uniform等)、math(sqrt、sin、cos、exp、log)
1 三大特性:封装+继承+多态
2类
#这里的Object指的是父类对象,如果没有继承的话还是要写Object的 class Student(object): #注意,这里的__init__是初始化方法,第一个永远是self,实例化的时候不需要写上self def __init__(self, name, score): self.name = name self.score = score def print_score(self): print('%s: %s' % (self.name, self.score)) bart = Student('Bart Simpson', 59)注意类的写法和初始化
3访问限制--封装
目的:为了安全性,或者说更方便的扩展类的属性一些操作,而使实例化对象不能使用如对象.Name或者对象.__Name的方式来直接访问
做法:就是在属性的前面加上__
如果需要访问,就建立一个set和get的方法如下
class Student(object): def __init__(self, name, score): self.__name = name self.__score = score def get_name(self): return self.__name def get_score(self): return self.__score注意:如果你使用了如Student.__Name="大白菜",随后进行打印这个东西,结果是大白菜的,但是,实际上是没有对它内部的属性进行修改,底层逻辑是创建了一个新的对象
其实私有化的变量也是可以取到的,只要用如s1._Studeng__name
因此,Python中没有完全的私有,它只是制定了一个规则让你获取属性更加困难
4继承和多态
如类class Student(object):中将object修改为父类即可
class Timer(object): def run(self): print('Start...')注意:由于python有动态变量的特征,所以它不管你有什么类,只要你这个类中有相同的名字的方法,你都可以作为超类,这种特性叫做鸭子类型(只要你长的像鸭子,可以游泳,可以走路,那你就是一个类鸭子)。
class Duck: def quack(self): print("嘎嘎嘎嘎。。。。。") class Bird: def quack(self): print("bird imitate duck....") class geese: def quack(self): print("doge imitate duck....") def in_the_forest(duck): duck.quack() duck = Duck() bird = Bird() doge = geese() for x in [duck, bird, doge]: in_the_forest(x) 本来forest要求的对象只能是鸭子,但是其他类都有鸭子中quack的方法,所以也可以传入进来5 获取用户对象信息
判断变量/函数类型 type() 返回Class类型 判断类类型 isinstance() 返回True或False 得到一个对象的所有属性和方法 dir() 返回list,里面都是str 判断有没有某个属性或者方法 hasattr() 返回True或False #type() >>> type('str') <class 'str'> #判断是函数类型怎么办?导入types包,用里面的函数 >>> type(fn)==types.FunctionType True >>> type(abs)==types.BuiltinFunctionType True >>> isinstance(h, Dog) True #还可以用来判断是某些类中的一种 >>> isinstance([1, 2, 3], (list, tuple)) True >>> getattr(obj, 'z', 404) # 获取属性'z',如果不存在,返回默认值404 404 hasattr(obj, 'y') # 有属性'y'吗?同时,也包含有方法'y'吗?注意:
1 能用type()判断的都可以用isinstance()进行判断
2 isinstance判断的是该类以及其父类(注意逻辑关系)
6 添加类属性和实例属性
#类属性 class Teacher(object): name="teacher" 实例属性 t=Teacher() t.sex='男'注意,类属性和属性的名称最好不要一样的。实例属性想要什么就加什么,动态性嘛
7 添加类方法和实例方法
#定义一个方法,导入MethodType方法,随后调用Method方法 from types import MethodType class Student(object): pass s=Student() def set_age(self, age,name): self.age = age self.name=name s.set_age = MethodType(set_age, s) s.set_age = 25,'dudu' print(s.set_age) #类绑定方法 Student.set_age=set_age8 __slots__
作用:表示实例的属性和方法有哪些
#表示只能添加名字是name和set_age的属性或者方法 class Student(object): __slots__ =('set_age','name')注意:子类可以定义的属性是自身的__slots__和父类的__slots__
9 @property修饰器
目的:
1 可以直接用student1.score的方法,又可以对条件进行赋值
2 设置读写权限
3 使得私有变量的书写更加简洁
#注意,第一个@是可读,第二个@是可写,使用这个还是需要初始化的 class Screen(object): def __init__(self, width): self._width = width @property def width(self): return self._width @width.setter def width(self,values): self._width=values @property def height(self): return self._height @height.setter def height(self,values): self._height=values @property def resolution(self): return self._width * self._height s = Screen(1024) s.height = 768 print('resolution =', s.resolution) if s.resolution == 786432: print('测试通过!') else: print('测试失败!')解释为什么在变量前面都要加_,因为这样表示的是私有属性,一般来说需要通过set和get方法来进行操作,但是这样实例化后进行操作比较复杂,我还是想用原来的student.name来进行操作,所以@propert可以实现这点
10 多重继承
做法:只要将object设置为多个父类对象如
class Dog(Mammal, Runnable): pass11 枚举类
作用:除了简单的枚举之外,更重要的是可以当做常量
from enum import Enum, unique @unique class Weekday(Enum): Sun = 0 # Sun的value被设定为0 Mon = 1 Tue = 2 Wed = 3 Thu = 4 Fri = 5 Sat = 6 #这样可以访问该变量 print(Weekday.Wed.value) #变量是不可改变的,以下内容是错误的 Weekday.Wed.value=912 元类
除了使用常规的创建类外,使用type()也可以创建类
def fn(self): print("I'm an animal") Animal=type('Animal',(object,),dict(myself=fn)) dog=Animal() dog.myself()type()中的三个参数分别为
1 类名字
2 继承的父类,注意一个父类的时候tuple()的写法
3 方法
13 metaclass元类
作用:创建类的模板,也就是说根据metaclass创建类,根据类创建实例对象
pass(一般用不太到,太难了)
14 zip函数
作用:将n个列表合成一个n列的矩阵
a=[1,23,4,5] b=['e','y','r','d'] for x,y in zip(a,b): print(x,y)- 您还可以看一下 CSDN就业班老师的Python爬虫技术和浏览器模拟,验证码识别视频教程课程中的 网络爬虫实战小节, 巩固相关知识点
- 以下回答由chatgpt基于相关博客总结生成:
代码实现:
def list_to_dict(lst): """ 将一个列表转换为字典 :param lst: 输入一个列表 :return: 返回一个包含该列表索引位置和对应元素的字典 """ return {i: lst[i] for i in range(len(lst))}使用方式示例:
l = [1, 2, 3, 'hello', 'world'] d = list_to_dict(l) print(d)输出结果:
{0: 1, 1: 2, 2: 3, 3: 'hello', 4: 'world'}