关于#关系#的问题,如何解决?(关键词-关系代数)
有关关系代数的问题,没有看懂中间的逻辑关系,希望可以帮帮我!

帮你在gpt找了一个回复、你看看对你理解这个逻辑关系有没有帮助
以下内容由CHATGPT及阿里嘎多学长共同生成、有用望采纳:
关系代数是一种基于关系的数学运算,用于对关系进行操作和处理。关系代数包含几种基本的运算,如选择、投影、笛卡尔积、并、交、差等,这些运算可以组合使用来实现更复杂的操作。
在你提供的截图中,左侧显示的是一张关系表,其中包含了多个属性字段和对应的属性值。如果需要对这个关系进行处理,可以使用关系代数中的运算来实现。以下是一些例子:
选择
选择运算用于从关系中选择满足特定条件的行。例如,如果我们需要从上图中选择所有age大于25的人,可以使用以下关系代数表达式:
$selection(age > 25, people)$
其中,$people$表示关系名,$age$表示属性名,$> 25$表示条件。
投影
投影运算用于从关系中选择特定的列。例如,如果我们需要从上图中选择只包含name和age两列的关系表,可以使用以下关系代数表达式:
$projection({name, age}, people)$
其中,${name, age}$表示需要选择的属性名列表,$people$表示关系名。
并
并运算用于将两个关系合并成一个。例如,如果我们需要将上图中的people和下图中的city合并成一个关系表,可以使用以下关系代数表达式:
$people \cup city$
其中,$\cup$表示并运算。
差
差运算用于从一个关系中删除另一个关系中存在的元素。例如,如果我们需要从上图中删除下图中的city中包含的元素,可以使用以下关系代数表达式:
$people - city$
其中,$-$表示差运算。
以上是关系代数中的一些基本运算,通过组合使用这些运算,可以实现更复杂的关系处理操作。
- 你可以看下这个问题的回答https://ask.csdn.net/questions/7707757
- 这篇博客也不错, 你可以看下(纯白话算法系列)归并排序,时间复杂度分析、代码演示,堆是什么?
- 除此之外, 这篇博客: (纯白话算法系列)堆排序,时间复杂度分析、代码演示,堆是什么?堆的数据结构底层中的 堆排序怎么实现 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
为什么堆排序这么重要呢??因为其复杂度是O(logN)的,要知道O(logN)比O(n²)要好太多太多了,比如要排序10亿个数据,log10亿只有28.9,而十亿的平方是多少就不用说了吧,性能差距太多了!!!所以面试堆排序必问,一定要完全地弄熟练这个排序!
堆排序其实是一种抽象的数据结构,它存储在一维数组中,画成树的样子只是便于理解,可是树怎么能存在一位数组当中呢?
堆有一种存放的原则,根节点的左孩子一定是(n * 2)+ 1,右孩子一定是(n * 2)+ 2,一个孩子的父节点一定是(n - 1) / 2.有一个特殊的根节点是0这个根节点,0的根节点套用公式是(0 - 1)/ 2,-1÷2其实还是0,所以大家不必担心。
所以首先需要将数组中无序的元素变成堆的这种结构,举个栗子:
比如1,2,3,4,5,6这六个元素已经依次排列在数组中了,这个例子是最不好的情况,也就是已经排好序的数组,看看他的时间复杂度会不会很高。
很显然如果用堆的结构排它是这样的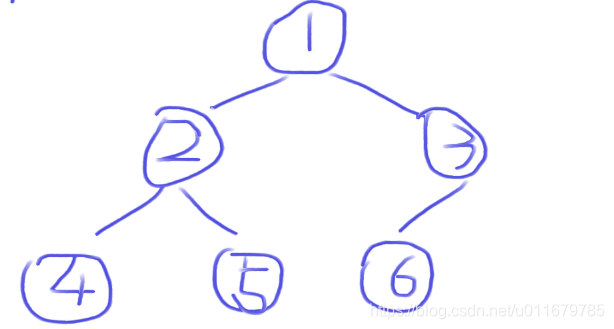
这很明显是一个小根堆,但是堆排序需要用大根堆,我们怎么把这个小根堆变成大根堆呢?首先定义一个index,这个index从第1个元素开始,因为是从第0个元素默认它已经是一个大根堆结构了,走到2这个数字,进行判断,如果这个元素大于它的根节点(怎么找到它的父节点呢?(index - 1)/2),那么就进行交换,也就是1和2交换,堆中现在是2,1,数组中是(2,1),3,4,5,6
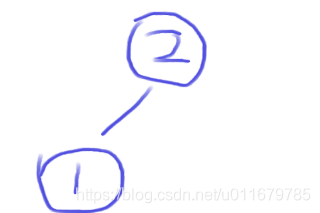
index++,往堆中新增一个3,然后判断它跟父节点的关系,很明显3>2,所以就交换位置,堆中元素如下:数组中元素为(3,1,2),4,5,6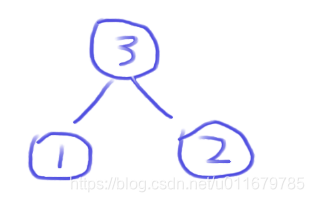
index++,往堆中新增一个4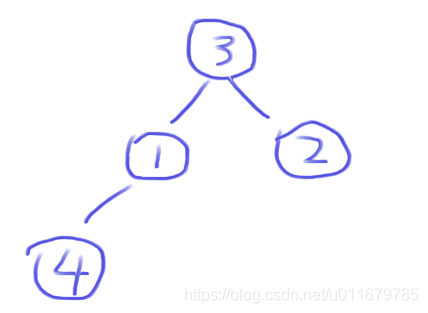
很明显4比它的父节点1要大,那么就跟1交换位置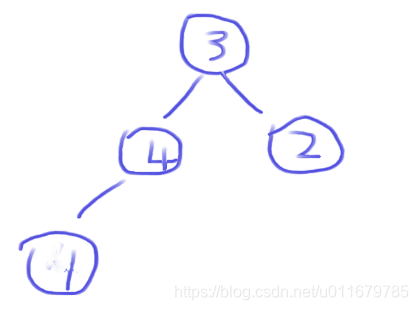
再进行判断,4比父节点3还要大,继续换,堆中位置如下,数组中:(4,3,2,1),5,6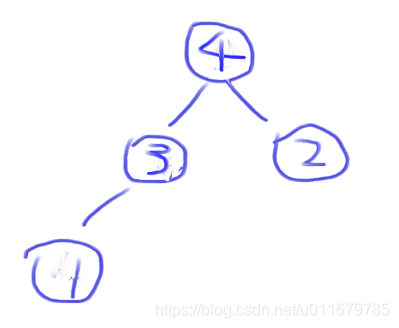
同理5,6也是这样排,最后堆中位置如下: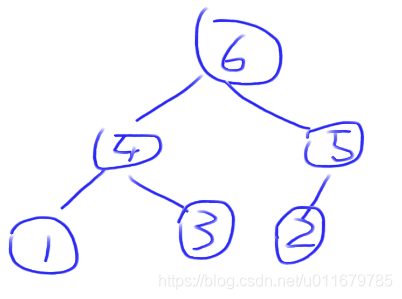
数组中为:6,4,5,1,3,2,那么怎么进行排序呢??
先把第0位置的元素和第5位置的元素进行交换,也就是(2,4,5,1,3),6,size = 6,size-1,也就是堆中有效位置变成了从第0位置到第4位置,6就被排除了,堆中现在是: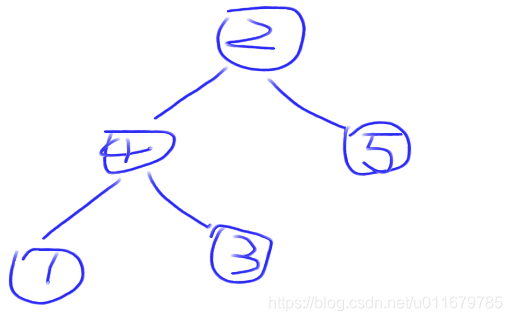
所以需要一步操作叫heapify,就是把不是堆的结构变成堆结构,把index变量指向2,先找他的两个孩子哪个最大,然后让index和两个孩子的最大值进行比较,如果相等,则不需要交换位置,如果index小于最大值,则和这个最大值进行交换,也就是先找2的两个孩子哪个最大,显然是5,然后2和5比较,显然5大,所以交换位置,由于交换位置后2没有子节点了,所以停止比较,堆中位置如下: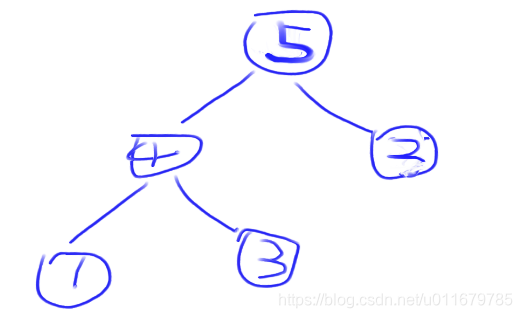
在数组中的位置:5,4,2,1,3,6,虽然6还在,可是在堆的范围内它已经被排除在外了,所以是一个越界的元素,取到它也没用,实际上堆中的元素是5,4,2,1,3,然后还是弹出第0个元素,和–size进行交换,也就是5和3交换,变成(3,4,2,1),5,6,堆中元素只剩下了3,4,2,1,再执行heapify方法,把其变成大根堆结构,也就是3和两个孩子节点中较大的那个元素比较,如果根节点小于孩子节点较大的那个元素,则和较大的元素进行交换,也就是3和4进行交换,堆变成了4,3,2,1,再执行交换,4,1交换,数组中变成(1,3,2),4,5,6,堆中元素只有1,3,2,1小于3,所以变成3,1,2,再执行交换,2,1,数组中元素变成(2,1),3,4,5,6,然后堆中元素只剩下2,1了,所以2>1,然后进行交换,变成1,2,3,4,5,6,排序到此也就结束了。看一下代码实现:
package com.bean.com.bean.sortAlg; import java.util.Arrays; public class HeapSort { public static void HeapSort(int[] arr) { if(arr == null || arr.length < 2) { return; } for(int i = 0; i < arr.length; i++) { HeapInsert(arr, i);//把数组变成堆结构 } int size = arr.length; swap(arr, 0, --size);第0位置元素和第--size元素进行交换 while(size > 0) {//只要堆空间还有元素 heapify(arr, 0, size);//把堆空间heap化 swap(arr, 0, --size);//再交换第0个元素和堆空间的最后一个元素 } } //把index之前的元素全部变成大根堆 public static void HeapInsert(int[] arr, int index) { while(arr[index] > arr[(index - 1) / 2]) {//和父节点比较 swap(arr, index, (index - 1) / 2); index = (index - 1) / 2; } } //从index到size变成大根堆 public static void heapify(int[] arr, int index, int size) { int left = index*2 + 1;//左孩子 while(left < size) { int largest = arr[left + 1] > arr[left] && left + 1 < size ? left + 1 : left; largest = arr[largest] > arr[index] ? largest : index; if(largest == index) break; swap(arr, largest, index); index = largest; left = index * 2 + 1; } } public static void swap(int[] arr, int left, int right) { int temp = arr[left]; arr[left] = arr[right]; arr[right] = temp; } public static int[] generateRandomArray(int maxSize, int maxNum) { if(maxSize == 0) { return null; } int[] randomArray = new int[(int) (Math.random() * (maxSize+1) )]; for(int i = 0; i < randomArray.length; i++) { randomArray[i] = (int)(Math.random() * (maxNum+1) - (int)(Math.random() * (maxNum))); } return randomArray; } public static int[] arrayCopy(int[] arr) { if(arr == null) { return null; } int[] copyArray = new int[arr.length]; for(int i = 0; i < arr.length; i++){ copyArray[i] = arr[i]; } return copyArray; } public static void printArray(int[] arr) { if(arr == null) { return; } for(int i = 0; i < arr.length; i++) { System.out.print(arr[i]+" "); } System.out.println(); } public static void ArrSort(int[] arr) { Arrays.sort(arr); } public static boolean isEqual(int[] arr1, int[] arr2) { if(arr1 == null && arr2 != null || arr1 != null && arr2 == null) { return false; }else if(arr1 == null || arr2 == null) { return true; }else if(arr1.length != arr2.length) { return false; } for(int i = 0; i < arr1.length; i++) { if(arr1[i] != arr2[i]) return false; } return true; } public static void main(String[] args) { int maxSize = 20; int maxNum = 50; int testTimes = 50000; boolean flag = true; for(int i = 0; i < testTimes; i++) { int[] arr1 = generateRandomArray(maxSize, maxNum); int[] arr2 = arrayCopy(arr1); ArrSort(arr1); HeapSort(arr2); flag = isEqual(arr1, arr2); if (!flag) { break; } } System.out.println(flag ? "Congraduation! Everything is ok!" : "Damn.. the wrong " + "method has been found.."); int[] arr1 = generateRandomArray(maxSize, maxNum); printArray(arr1); HeapSort(arr1); printArray(arr1); } }- 您还可以看一下 思寒老师的持续集成接口自动化测试从零基础到实战精通课程中的 移动端代理抓包-数据拦截与修改方法教学小节, 巩固相关知识点
- 以下回答由chatgpt基于相关博客总结生成:
关系代数是一种关系型数据库的查询语言,它主要有用于查询的算符、逻辑运算符、以及一些集合运算符等。
为更好地理解关系代数的逻辑关系,我建议你可以从以下两个方面展开学习:
学习关系模型的具体定义与概念 关系代数作为关系型数据库的查询语言,它的核心就是关系。对于每一张关系表,它都可以用一组关系的属性和关系的集合来描述。在学习关系代数之前,我们需要先了解关系模型的具体定义与概念,从而更好地了解SQL中的数据类型、数据完整性、表的设计与规范等方面的内容。你可以查阅一些相关的书籍或者文档资料进行学习。
学习关系代数的基础操作及其语义 关系代数中的基础操作包括选择、投影、并、差、笛卡尔积等。这些操作都有详细的定义和语义,我们需要对它们进行深入的学习和理解。例如,在选择操作中,我们需要从一个关系中选择满足特定条件的行,在投影操作中,我们需要从一个关系中仅选出特定的列。同时,我们还需要学习如何将这些基础操作组成一些更为复杂的查询。这些内容也可以通过查阅相关的书籍或者文档资料进行学习。
下面提供一些关系代数的基础操作的代码示例:
选择操作:
例如,针对一个名为R的关系表,其中包含属性A、B、C,我们需要从中选择满足A > 5的所有行,可以使用以下代码:
select * from R where A > 5;
投影操作:
例如,针对一个名为S的关系表,其中包含属性A、B、C,我们需要仅选择出属性A和属性B的所有列,可以使用以下代码:
select A,B from S;
并操作:
例如,针对两个名为R和S的关系表,其中都包含属性A、B、C,我们需要取这两张表的并集,即包含这两张表中全部的记录,可以使用以下代码:
select * from R union select * from S;
差操作:
例如,针对两个名为R和S的关系表,其中都包含属性A、B、C,我们需要取这两张表的差集,里面包含R中有但S中没有的所有记录,可以使用以下代码:
select * from R except select * from S;
笛卡尔积:
例如,针对两个名为R和S的关系表,其中分别包含属性A、B、C和属性D、E、F,我们需要取这两张表的笛卡尔积(即将两个关系表的每一行都与另一个关系表的每一行进行组合,生成一个新的关系表),可以使用以下代码:
select * from R,S;
带权图的广搜(不能处理边权为负的情况):
以下是带权无向图的广搜算法的代码示例:
void BFS(ALGraph G, int v) { int visit[MAX_VERTEX_NUM]; Queue Q; InitQueue(&Q); for (int i = 0; i