对单链表存储进行顺序查找的静态查找和动态查找的算法
#c语言
#静态查找
#动态查找
#顺序查找
#算法
设查找表采用单链表存储,请分别写出对该表进 行顺序查找的静态查找和动态查找的算法。
#include <stdio.h>
#include <stdlib.h>
// 定义单链表结构体
typedef struct Node {
int data;
struct Node* next;
} Node;
// 创建单链表
Node* createList(int arr[], int n) {
Node* head = (Node*)malloc(sizeof(Node));
head->next = NULL;
Node* p = head;
for (int i = 0; i < n; i++) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = arr[i];
newNode->next = NULL;
p->next = newNode;
p = p->next;
}
return head;
}
// 顺序查找的静态查找算法
int staticSearch(Node* head, int key) {
Node* p = head->next;
int i = 0;
while (p != NULL && p->data != key) {
p = p->next;
i++;
}
if (p == NULL) {
return -1; // 未找到关键字
} else {
return i; // 找到关键字,返回其下标
}
}
// 顺序查找的动态查找算法
int dynamicSearch(Node* head, int key) {
Node* p = head->next;
Node* pre = head;
int i = 0;
while (p != NULL && p->data != key) {
pre = p;
p = p->next;
i++;
}
if (p == NULL) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = key;
newNode->next = NULL;
pre->next = newNode;
return -1; // 未找到关键字
} else {
return i; // 找到关键字,返回其下标
}
}
int main() {
int arr[] = {1, 2,10,20,25};
int n = sizeof(arr) / sizeof(int);
Node* head = createList(arr, n);
int pos1 = staticSearch(head, 7);
if (pos1 == -1) {
printf("静态查找:未找到\n");
} else {
printf("静态查找:找到了,下标为%d\n", pos1);
}
// 测试动态查找算法
int pos2 = dynamicSearch(head, 10);
if (pos2 == -1) {
printf("动态查找:未找到\n");
} else {
printf("动态查找:找到了,下标为%d\n", pos2);
}
// 遍历链表,输出所有元素
Node* p = head->next;
printf("链表元素:");
while (p != NULL) {
printf("%d ", p->data);
p = p->next;
}
printf("\n");
return 0;
}

静态查找
Status Search_LinkList(LinkList L, ElemType target) {
LinkList temp = L->next; // temp指向第一个数据节点
int i = 1; // i表示当前节点的位置
while (temp != NULL && temp->data != target) {
temp = temp->next;
i++;
}
if (temp == NULL) {
return ERROR;
} else {
return i;
}
}
动态查找
LinkList Dynamic_Search(LinkList L, ElemType target) {
LinkList p = L->next; // p指向第一个数据节点
LinkList pre = L; // pre指向p的前驱节点
while (p != NULL && p->data != target) {
// 寻找节点p
pre = p;
p = p->next;
}
if (p == NULL) {
return NULL; // 查找失败
} else if (p == L->next) {
return L; // 查找成功,且目标元素是第一个结点
} else {
pre->next = p->next; // 移除节点p
p->next = L->next; // 将p放在表头L->next处
L->next = p;
return L; // 查找成功
}
}
- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/7574172
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:C语言中利用自定义函数来交换俩个变量的值 与 直接在主函数创建一个中间变量 这俩种方法的区别。形参与实参的联系
- 除此之外, 这篇博客: 使用C语言实现冒泡排序算法中的 冒泡排序属于交换排序的一种。所谓交换,就是根据序列中两个关键字的比较结果来确定这两个记录在序列中的位置。 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
冒泡排序的基本思想: 假设一个待排序列长度为n,从后往前(或从前往后)两两比较元素的值,若为正序则不操作,若为逆序(即A[i-1]>A[i])则交换它们,直到序列比较完,称为一趟“冒泡”,此时将最小的元素交换到待排序列的第一个位置,也是它的最终位置。下一趟排序时,上一趟确定的最小元素不再参与排序,每趟排序都将序列中最小的元素交换到第一个位置,依次类推,最多进行n-1趟冒泡就能把所有元素排好序。
排序完成的判断条件: 使用flag作为标志位,每趟冒泡前初始为false,若发生元素交换则置为true,在一趟冒泡完成后判断flag值,若为true则继续排序,若为false则说明没有发生元素交换,排序完成。
冒泡排序的性能分析:
空间复杂度:仅进行元素交换需要常数个辅助空间,因此空间复杂度为O(1)。
时间复杂度:当待排序列已经有序时,明显进行一趟冒泡后flag值为false,排序完成,直接结束,比较次数为n-1,移动次数为0;当待排序列逆序时,需要进行n-1趟冒泡,第i趟排序需要进行n-i次比较,每次比较必须移动元素3次以交换位置,在这种情况下,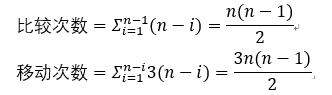
从而最坏情况下的时间复杂度为O(n2)。平均时间复杂度也为O(n2)。
举例说明冒泡过程:
设一个初始序列为A={10,6,9,3,5,2}
第一趟冒泡结果,A={2,10,6,9,3,5} (元素2到达最终位置)
第二趟冒泡结果,A={2,3,10,6,9,5} (元素3到达最终位置)
第三趟冒泡结果,A={2,3,5,10,6,9} (元素5到达最终位置)
第四趟冒泡结果,A={2,3,5,6,10,9} (元素6到达最终位置)
第五趟冒泡结果,A={2,3,5,6,9,10} (元素9到达最终位置)
此时排序完成
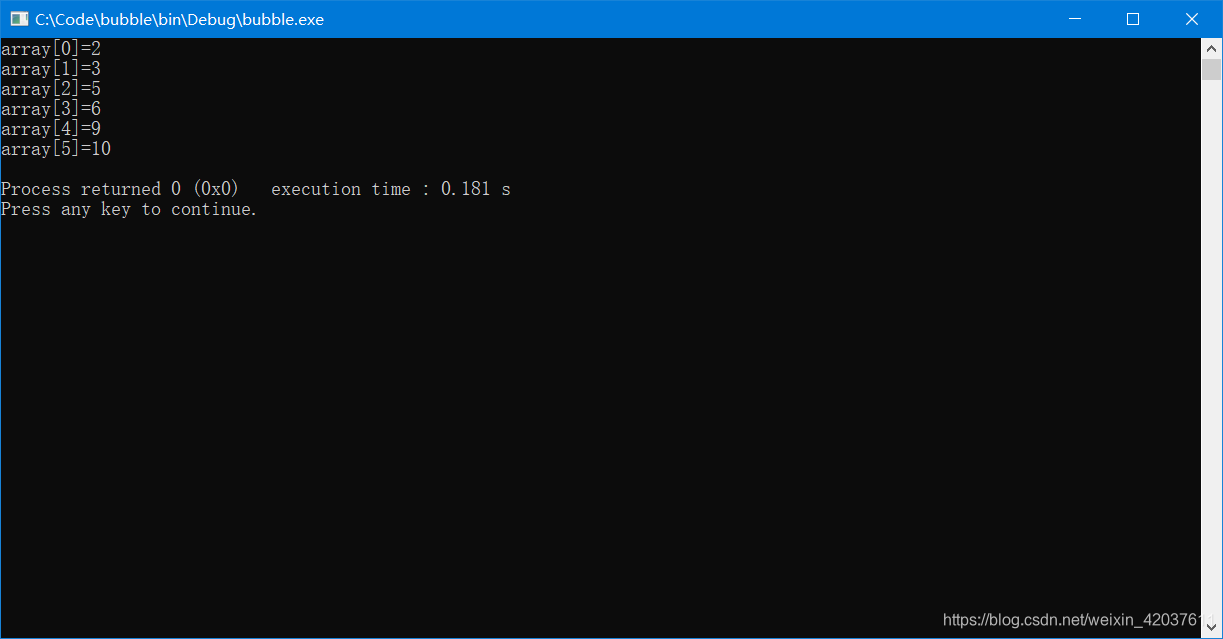
传统冒泡排序算法如下:#include <stdio.h> void bubblesort(int a[],int length); void swap(int a[],int i,int j); int main() { int array[6]={10,6,9,3,5,2}; /*定义一个数组*/ int i; bubblesort(array,6); for(i=0;i<6;i++) { printf("array[%d]=%d\n",i,array[i]); /*输出排序后的数组*/ } } void bubblesort(int a[],int n) /*冒泡排序算法*/ { if(n==0||n<2) /*序列长度小于2直接返回*/ return; int i,j,flag; for(i=0;i<n;i++) /*外层循环比较的次数*/ { flag=0; for(j=n-1;j>i;j--) /*内层循环比较的范围*/ { if(a[j-1]>a[j]) { swap(a,j-1,j); flag=1; } } if(flag==0) return; } } void swap(int a[],int i,int j) /*交换元素位置*/ { int temp; temp=a[i]; a[i]=a[j]; a[j]=temp; }运行结果如下图示:
- 您还可以看一下 Abel小智老师的嵌入式开发系统学习路线 从基础到项目 精品教程 工程师必备课程 物联网课程中的 C语言开发基础介绍小节, 巩固相关知识点
- 以下回答由chatgpt基于相关博客总结生成:
单链表存储以及静态查找和动态查找的概念
单链表存储是指将数据节点按顺序通过指针链接起来存储,每个节点里面通过指针指向下一个节点。这种存储方式的优点是插入和删除数据时不需要移动大量数据,只需要对指针进行修改。静态查找是指数据在查找过程中是不变的,而动态查找是指数据在查找过程中是动态改变的,即在查找过程中可以进行插入和删除。静态查找适合于查找频繁而插入删除较少的数据,而动态查找适合于插入删除操作比较频繁的数据。
单链表存储的查找表的顺序查找的静态算法
顺序查找是最朴素的一种查找方法,它的基本思想是从第一个元素开始,依次向后查找,直到查找到关键字为止。在基于链表的顺序查找中,我们通常首先找到链表的头结点,然后沿着链表顺序结构一个一个进行查找,找到关键字就返回,直到整个链表查找结束。具体的步骤如下:
- 定义一个指针p指向头节点;
- 依次将指针p移动到下一个节点;
- 当找到关键字时返回数据;如果没有找到,返回信息“数据不存在”。
单链表存储的查找表的顺序查找的动态算法
针对动态查找的特点,我们需要维护一个局部有序的结构,在查找时以一定的策略来优化查找效率。常见的动态查找算法有二叉排序树、平衡查找树、哈希表等。这里以二叉排序树为例,介绍单链表存储的查找表的动态查找的算法思路。二叉排序树(Binary Search Tree)是一种二叉树,其中每个节点都包含一个关键字和数据,关键字的大小决定了它的位置,具体的规则是左子树的关键字小于右子树的关键字。
具体的步骤如下:
- 从根节点开始查找,如果二叉排序树不存在,则把该节点插入到树中;
- 如果节点数据等于查找关键字,则查找到所要数据,返回;
- 如果节点的数据大于查找关键字,则到左子树上查找;
- 如果节点的数据小于查找关键字,则到右子树上查找;
- 如果查找到最后一层仍然没有找到,则查找结束,返回信息“数据不存在”。