在动态场景中移动物体
我正在寻找一种代码来检测动态场景中的移动物体。 大多数方法都使用背景减法,但对于动态背景,此方法不起作用。 你有什么建议? 我不想使用 AI 模型,因为它是一个嵌入式应用程序。
谢谢。
- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/7778163
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:人工智能AI中关于数据标注标签处理的工具集锦
- 除此之外, 这篇博客: 对图像直方图的理解中的 直方图均衡的目的是为了使灰度分布的更广泛,从而来拉伸对比度。 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
有两个问题比较难懂,一是为什么要选用累积分布函数,二是为什么使用累积分布函数处理后像素值会均匀分布。
第一个问题。均衡化过程中,必须要保证两个条件:①像素无论怎么映射,一定要保证原来的大小关系不变,较亮的区域,依旧是较亮的,较暗依旧暗,只是对比度增大,绝对不能明暗颠倒;②如果是八位图像,那么像素映射函数的值域应在0和255之间的,不能越界。综合以上两个条件,累积分布函数是个好的选择,因为累积分布函数是单调增函数(控制大小关系),并且值域是0到1(控制越界问题),所以直方图均衡化中使用的是累积分布函数。
第二个问题。累积分布函数具有一些好的性质,那么如何运用累积分布函数使得直方图均衡化?比较概率分布函数和累积分布函数,前者的二维图像是参差不齐的,后者是单调递增的。直方图均衡化过程中,映射方法是
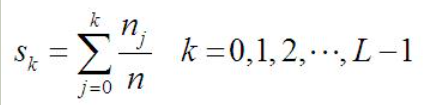
其中,n是图像中像素的总和,
 是当前灰度级的像素个数,L是图像中可能的灰度级总数。
是当前灰度级的像素个数,L是图像中可能的灰度级总数。来看看通过上述公式怎样实现的拉伸。假设有如下图像:
得图像的统计信息如下图所示,并根据统计信息完成灰度值映射:

直方图均衡化参考链接:https://www.cnblogs.com/tianyalu/p/5687782.html
- 您还可以看一下 CSDN讲师老师的AI出入证-人工智能助力疾控复工课程中的 复杂网络技术可以构建跨多度连接、多种关联关系的图数据库数据服务小节, 巩固相关知识点
- 以下回答由chatgpt基于相关博客总结生成:
针对动态场景中移动物体的检测问题,建议使用运动目标检测(Moving Object Detection)方法。常用的运动目标检测方法包括基于光流的方法、基于帧差法的方法、基于背景建模的方法等。由于使用了背景减法的方法在动态背景下不起作用,可以考虑使用基于光流的方法或基于帧差法的方法进行处理。
基于光流的方法可以用来检测局部区域的运动物体,具体步骤如下:
- 对连续的两帧图像计算稠密光流场;
- 对光流场进行聚类,将与物体运动相关的光流聚为一类;
- 根据运动物体的形态特征,如运动轨迹、大小、形状等,抽取运动目标,并进行跟踪。
参考代码:
#include <opencv2/opencv.hpp> using namespace cv; using namespace std; int main() { VideoCapture cap(0); //打开摄像头 Mat frame, preFrame, grayFrame, preGrayFrame; vector<uchar> status; vector<float> err; //输入输出光流图像 Mat flow, cflow; Mat img, img0; //创建随机颜色 vector<Scalar> colors; RNG rng; for (int i = 0; i < 100; i++) colors.push_back(Scalar(rng.uniform(0, 255), rng.uniform(0, 255), rng.uniform(0, 255))); //循环处理视频流 while (waitKey(30) != 27) { cap >> frame; if (frame.empty()) break; cvtColor(frame, grayFrame, COLOR_BGR2GRAY); if (!preGrayFrame.empty()) { calcOpticalFlowFarneback(preGrayFrame, grayFrame, flow, 0.5, 3, 15, 3, 5, 1.2, 0); cvtColor(preGrayFrame, cflow, COLOR_GRAY2BGR); //计算运动物体的边界矩形 vector<vector<Point>> contour; vector<Vec4i> hierarchy; findContours(threshold, contour, hierarchy, RETR_CCOMP, CHAIN_APPROX_SIMPLE); for (int i = 0; i < contour.size(); i++) { Rect box = boundingRect(contour[i]); rectangle(cflow, box, colors[i % 100], 2); } imshow("optical_flow", cflow); } preGrayFrame = grayFrame.clone(); } return 0; }基于帧差法的方法可以用来检测全局区域的运动物体,具体步骤如下:
- 选取参考帧;
- 对当前帧与参考帧进行帧差计算,得到差分帧;
- 对差分帧进行阈值划分,得到二值图像;
- 对二值图像进行形态学操作,对噪点进行滤除,得到物体轮廓;
- 对物体轮廓进行聚类,提取运动目标。
参考代码:
#include <opencv2/opencv.hpp> using namespace cv; using namespace std; int main() { VideoCapture cap(0); //打开摄像头 Mat frame, preFrame, grayFrame, preGrayFrame, diffFrame, threshold; //循环处理视频流 while (waitKey(30) != 27) { cap >> frame; if (frame.empty()) break; cvtColor(frame, grayFrame, COLOR_BGR2GRAY); if (!preGrayFrame.empty()) { //帧差计算 absdiff(preGrayFrame, grayFrame, diffFrame); //二值化处理 threshold(diffFrame, threshold, 30, 255, THRESH_BINARY); //形态学处理 Mat element = getStructuringElement(MORPH_RECT, Size(5, 5)); morphologyEx(threshold, threshold, MORPH_OPEN, element); //轮廓分析 vector<vector<Point>> contour; vector<Vec4i> hierarchy; findContours(threshold, contour, hierarchy, RETR_CCOMP, CHAIN_APPROX_SIMPLE); for (int i = 0; i < contour.size(); i++) { Rect box = boundingRect(contour[i]); rectangle(frame, box, Scalar(0, 0, 255), 2); } imshow("frame", frame); imshow("threshold", threshold); } preGrayFrame = grayFrame.clone(); } return 0; }
这是一篇原创研究文章,提出了一种基于 RGB-D 图像的视觉里程计方法,可以在动态室内场景中检测移动物体并估计相机位姿。该方法使用三角形约束和极线几何约束来分类 RGB 图像上的特征点,并将分类后的特征点映射到深度图像上,根据动态特征点的数量来给每个聚类分配一个动态或静态的标签,从而生成一个动态区域掩码,去除被掩码覆盖的特征点,最后使用剩余的静态特征点来估计相机位姿。
参考链接:https://ietresearch.onlinelibrary.wiley.com/doi/10.1049/csy2.12079