在一个已经训练好的神经网络中,如何给定一个输出值来反向推出特征值的数值大小
已经建立好了mlp神经网络,并且训练也达到了理想情况,如何由人为给定一个输出值来反向得到特征值大小呢?
不知道你这个问题是否已经解决, 如果还没有解决的话:- 这篇文章:全连接网络(FC)、前馈神经网络(BP)、多层感知机(MLP) 也许能够解决你的问题,你可以看下
- 除此之外, 这篇博客: 深度学习初步,全连接神经网络,MLP从原理到实现(一)原理部分,反向传播详细解释和实际计算例子中的 2.多层全连接神经网络中的反向传播 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
损失函数有很多均方误差,交叉熵损失函数等等。
把所有样本的损失值加起来为总的损失,参数即为神经网络中的权重,将总的损失优化到最小即为最终的权重参数,优化使用梯度下降,只不过可能是各种梯度下降的变形。
如何计算用于更新参数的偏微分
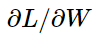 是一个重要的问题。
是一个重要的问题。补充:链式求导法则

要计算
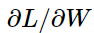 这里L是总的损失,这里求导举例只举例单个样本对参数求导,总的直接所有样本加起来就行,所以以l代表单个样本的损失值。
这里L是总的损失,这里求导举例只举例单个样本对参数求导,总的直接所有样本加起来就行,所以以l代表单个样本的损失值。反向传播:
为了使用梯度下降,需要求出梯度,也就是损失函数L关于权重w的一阶导数。设有N个样本,那么:
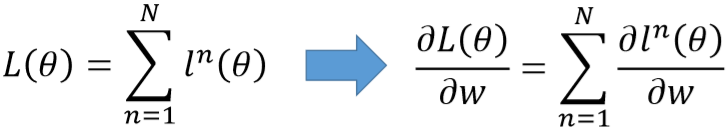
因为多个样本和单个样本求梯度没什么差别,所以下面的例子以求单个样本的损失函数(以l表示)对w的导数为例。类似的,专注损失l对某个特定的w的导数而不是所有w,因为其他w的求法都可以类似得到。
对于这样一个简单的nn结构:

关注左上角的局部部分:

损失函数l是在NN的输出端形成的,要求出l对w1的导数,就要利用开始提到的链式求导法则。
Z的值直接影响到了
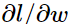 ,所以链式求导从这里开始。
,所以链式求导从这里开始。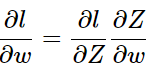
因为:
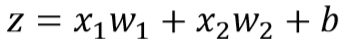
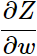 很容易直接得到就是x1,因为这里是输入层后的隐层,所以是x1,如果不是,直观的后面任意层的
很容易直接得到就是x1,因为这里是输入层后的隐层,所以是x1,如果不是,直观的后面任意层的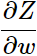 就是前一层的输入a
就是前一层的输入a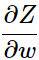 没有
没有 这么容易计算,因为z还影响了下一层的输入a,而a又进一步影响后面层的w,这种影响一直延续下去直到输出层。
这么容易计算,因为z还影响了下一层的输入a,而a又进一步影响后面层的w,这种影响一直延续下去直到输出层。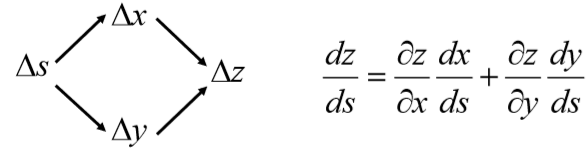
仔细想想这里的Z就类似上图种的s,只不过NN结构中,Z影响到的变量要比图中的s更多。
接着,继续对
 展开,Z紧接着送到了激活函数σ中,产生了a。所以:
展开,Z紧接着送到了激活函数σ中,产生了a。所以:
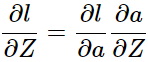
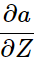 就是激活函数的导数,写成
就是激活函数的导数,写成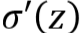 。
。继续写出
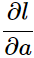 。
。
根据链式法则:
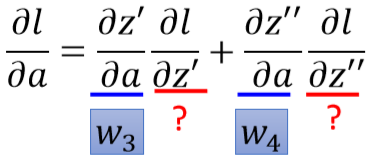
所以:
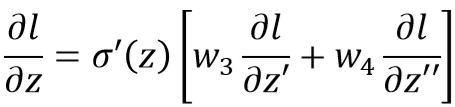
如果z'和z''不是输出层,那么这个过程还有继续进行下去。我们把这个过程看作逆向的:

我们将求
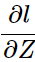 这个过程反过来看:
这个过程反过来看: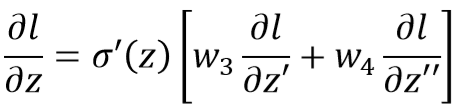
比如:

我们要求
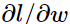 ,那么可以分为2个步骤,
,那么可以分为2个步骤,前向传播求出
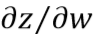
反向传播求
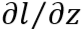
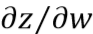 就是上一层的输出,本层的输入
就是上一层的输出,本层的输入而
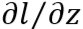 需要从输出层开始计算。
需要从输出层开始计算。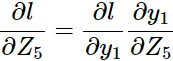
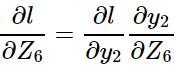
有了
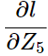
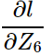 那么前面的
那么前面的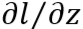 就可以反向回去。
就可以反向回去。比如:
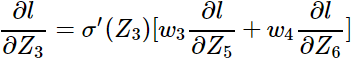
这样从后往前计算就可以算出所有的
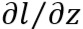 ,最后将
,最后将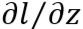 和
和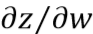 乘起来就可以得到
乘起来就可以得到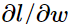 。(注意这里的思维要想成所有的w)
。(注意这里的思维要想成所有的w)下面举一个实际的例子:

NN结构如图,规定激活函数使用sigmoid,损失函数使用交叉熵,输出层[y1,y2]使用softmax。输入单个样本x1,x2=1,2,y=[1,0](one-hot编码表示类别是y1)。
补充:softmax和交叉熵输出层的求导。
参考:https://blog.csdn.net/qian99/article/details/78046329
最后一层softmax做激活函数,那么输出a的表达式为:

z就是上一层的输入和权重的乘积求和再加上b
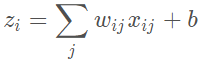
激活函数σ(z):
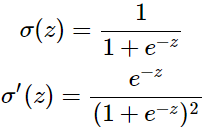
损失函数:
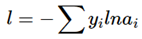
这里l是单个样本,求和是因为多个类别,比如总共有3个类别,如果某个样本的真实类别是2,那么标签是一个向量[0 1 0],遍历就是要遍历这个向量,
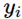 就是指不同类别的真实值(这里就只有y2=1,其他为0),
就是指不同类别的真实值(这里就只有y2=1,其他为0),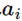 就是经过softmax后不同类别的概率分布。
就是经过softmax后不同类别的概率分布。要求的是:
、
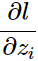
这里
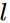 代表单个样本的损失,如果是多个样本只需要求和:
代表单个样本的损失,如果是多个样本只需要求和: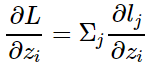
因为
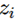 直接影响了a的值,而因为softmax的特效,所有a的分母部分都包含了
直接影响了a的值,而因为softmax的特效,所有a的分母部分都包含了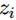 。
。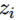 影响了所有a的值:
影响了所有a的值:
根据链式法则:
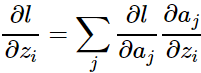
先来计算
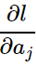 ,因为
,因为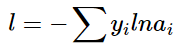 ,只对
,只对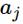 求偏导,所以其他
求偏导,所以其他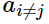 均当作常数项。那么:
均当作常数项。那么: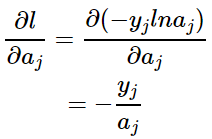
再计算
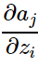 ,需要分情况讨论,因为j=i时,a的分子部分含有
,需要分情况讨论,因为j=i时,a的分子部分含有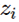 。
。当i=j:
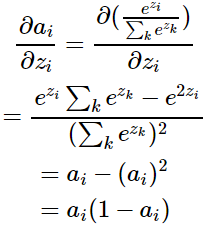
当i≠j时:
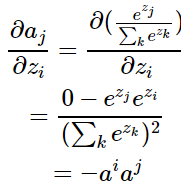
将上面2种情况组合起来:

所以最后:
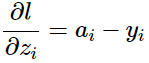
有了上面的例子开始计算:
输如样本x=[1,2],y=[1,0],权重初始如图,偏置b都为0.1
(1)先进行一次前向传播,计算所有的神经元输出输出a:

(2)反向传播计算梯度
符号说明:
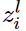 表示第l(不包含输入层)层第i(从上往下数)个单元产生的z值
表示第l(不包含输入层)层第i(从上往下数)个单元产生的z值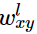 表示第l层第x个单元与第l-1层第y个单元之间连接的权重。
表示第l层第x个单元与第l-1层第y个单元之间连接的权重。
计算
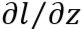 :
:第3层:

第2层:
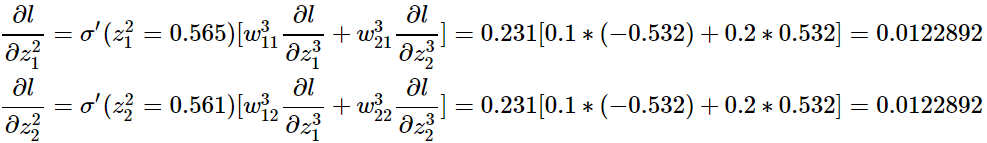
第1层:
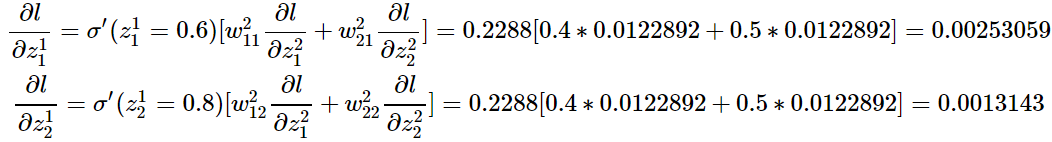
有了
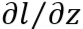 ,计算
,计算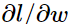 就很简单了:比如:
就很简单了:比如:
(3)向量化/矩阵化运算
但是这样串行的思想不利用计算,需要把上面的计算过程向量化矩阵化。

1)a的计算
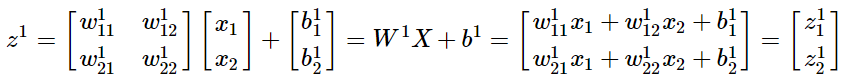

其他层的计算类似,输入x变为输入上一层的输出a
2)
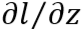

其他情况类似推广。
3)
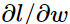
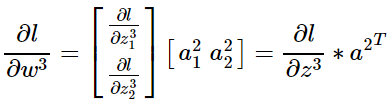
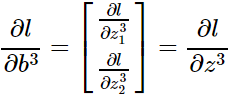
其他情况类似推广。
可以计算梯度后就可以更新参数了。
- 您还可以看一下 赵辛老师的深度学习之神经网络 核心算法与项目实战课程中的 MLP实现非线性边界数据分类(1)小节, 巩固相关知识点
- 以下回答来自chatgpt:
对于已经训练好的MLP神经网络,如果想通过输入一个输出值来反向计算出相应的特征值大小,可以使用反向传播算法和梯度下降算法来完成。
具体步骤如下:
1.根据MLP神经网络的结构,定义反向传播算法函数backpropagate()。
def backpropagate(output, target, layers): error = output - target for i in reversed(range(len(layers))): layer = layers[i] error = layer.backward(error) return error2.定义MLP神经网络的类和各层,并使用已训练好的权重w和偏置b对建立的神经网络进行初始化。在类中定义前向传播算法函数forward()和反向传播算法函数backward()。在前向传播算法中,根据经过加权输入进行激活后的输出值和权重,计算出模型输出值。在反向传播算法中,根据输出值和目标值求解梯度。
class MLP(): def __init__(self, num_inputs, num_hidden, num_outputs): self.num_inputs = num_inputs self.hidden_layer = DenseLayer(num_hidden, num_inputs) self.output_layer = DenseLayer(num_outputs, num_hidden) self.layers = [self.hidden_layer, self.output_layer] def forward(self, inputs): x = self.hidden_layer.forward(inputs) x = self.output_layer.forward(x) return x def backward(self, output, target): error = backpropagate(output, target, self.layers) return error3.在测试数据上进行预测,通过输入输出值,得到输出的特定特征值的大小。具体步骤如下:
(1)读取测试数据,进行标准化处理。
(2)将标准化后的数据输入到神经网络中,得到输出结果。
(3)通过调用backward()函数,返回输入值的特定特征值大小。
import numpy as np # 读取测试数据,并进行标准化处理 test_data = np.loadtxt('test_data.csv', delimiter=',') mean = np.mean(test_data, axis=0) std = np.std(test_data, axis=0) test_data = (test_data - mean) / std # 定义MLP神经网络的结构 mlp = MLP(num_inputs=5, num_hidden=4, num_outputs=3) # 加载已训练好的权重和偏置 mlp.hidden_layer.weights = np.loadtxt('hidden_weights.csv', delimiter=',') mlp.hidden_layer.biases = np.loadtxt('hidden_biases.csv', delimiter=',') mlp.output_layer.weights = np.loadtxt('output_weights.csv', delimiter=',') mlp.output_layer.biases = np.loadtxt('output_biases.csv', delimiter=',') # 对每个测试样本进行预测,输出特定特征值大小 for input in test_data: output = mlp.forward(input) feature_value = mlp.backward(output, [1, 0, 0]) # 输出第一个特征值的大小 print('Feature Value:{}'.format(feature_value))注意事项:
(1)反向传播算法要求激活函数是可微分的,一般采用sigmoid或者ReLU。
(2)在使用梯度下降算法时,需要谨慎选择学习率,以避免梯度爆炸或者梯度消失的问题。
(3)为了避免过拟合,常采用正则化方法,如L1正则化和L2正则化等。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^