列表及集合转化问题 求解 急

不太理解如何输入及输出
记得采纳一下哎!

input_str = input("请输入一行整数以空格间隔:")
input_list = [int(x) for x in input_str.split()] # 将输入转换为整数列表
output_list = []
for i in input_list:
if i not in output_list: # 判断元素是否出现过
output_list.append(i) # 若该元素未出现,则将其添加到输出列表中
output_str = " ".join([str(x) for x in output_list]) # 将输出列表转换为字符串
print(output_str) # 输出结果
- 帮你找了个相似的问题, 你可以看下: https://ask.csdn.net/questions/7598327
- 这篇博客你也可以参考下:深入浅出理解模型方差偏差噪声与泛化误差的关系
- 除此之外, 这篇博客: 排序模型训练中过程中的损失函数,盘它!中的 损失函数介绍 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
0-1损失函数,最直观的损失函数就是模型的预测结果,即0-1损失函数(0-1 Loss Function),其数据表达式如下:

虽然0-1损失函数能够客观的评价模型的好坏,但缺点是数学性质不好,不连续且不可导,比较难以优化。因此经常使用连续可微的损失函数代替。
平方损失函数(Quadratic Loss Function),经常用在预测标签y为实数值的任务中。其数学表达式如下:
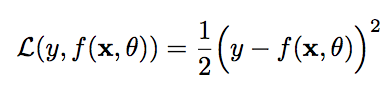
平方损失函数一般不适用于分类问题。
附:平方损失函数前边有系数1/2 是因为在求倒数之后将系数去掉。
交叉熵损失函数(Cross-Entroy Loss Function),一般用于分类问题。假设样本的标签y属于{1,2,....,C}为离散的类别,模型f(x,theta)属于[0,1]^C 的输出为类别标签的条件概率分布,即:
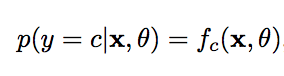
并满足:
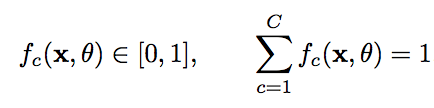
我们可以使用一个C维的one-hot向量y来表示样本标签。假设样本的标签为k,那么标签向量y只有第k维的值为1,其余元素的值为0。标签向量y可以看作是样本标签的真实概率分布。即第c维(记为y_c,1=< c =<C )是类别c的真实概率。假设样本的类别为k,那么他属于第k类的概率为1,其他类的概率为0。
对于两个概率分布,一般可以用交叉熵来衡量他们的差异。标签的真实概率分布y和预测样本概率f(x,theta)之间的交叉熵为:
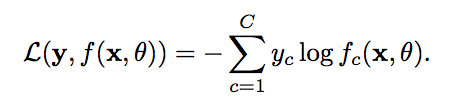
公式-1 比如对于三分类问题,一个样本的 标签向量为y=[0,0,1]^T,模型预测的标签分布为f(x,theta)=[0.3,0.3,0.4]^T,则他们的交叉熵为:

因为y为one-hot向量,公式-1也可以写为:

其中f_y(x,theta)可以看作是真实类别y的似然函数,因此交叉熵损失函数也就是负对数似然损失函数(Negative Log-likelihood Function)。
对数损失函数(Logarithmic Loss Function),该损失函数用到了极大似然估计的思想。P(Y|X)通俗的解释就是:在当前模型的基础上,对于样本X,其预测值为Y,也就是预测正确的概率。由于概率之间的同时满足需要使用乘法,为了将其转化为加法,我们将其取对数。最后由于是损失函数,所以预测正确的概率越高,其损失值应该是越小,因此再加个负号取个反。

Hinge损失函数(Hinge Loss Function),对于二分类问题,假设y和f(x,theta)的取值分别为{-1,+1},Hinge损失函数为:

- 您还可以看一下 李振良老师的中大型网站架构演进与建设实践课程中的 网站架构图介绍与环境准备小节, 巩固相关知识点
- 以下回答由chatgpt基于相关博客总结生成:
对于列表和集合的输入和输出,需要注意以下几个点:
1.列表和集合的创建:列表可以通过
list()函数或中括号[]来创建,集合可以通过set()函数或花括号{}来创建。2.列表和集合的索引和切片:列表和集合均支持索引和切片操作。需要注意的是,集合是无序的,所以切片操作不保证顺序和元素个数的一致性。
3.列表和集合的添加和删除:可以通过
append()和insert()方法向列表中添加元素,通过remove()和discard()方法删除元素。集合可以通过add()方法添加元素,通过remove()和discard()方法删除元素。4.列表和集合的遍历:可以通过
for循环遍历列表和集合中的所有元素。5.列表和集合的排序:列表可以通过
sort()和sorted()函数进行排序,集合本身无法排序,但可以通过把集合转为列表后使用sort()和sorted()函数排序。例如:
# 创建列表 lst = list(range(1, 11)) lst2 = [1, 2, 3, 4, 5] # 创建集合 s = set([4, 5, 6]) s2 = {1, 2, 3, 4, 5} # 列表和集合的索引和切片 print(lst[0]) # 输出1 print(s2[1:3]) # 输出{2, 3} # 列表和集合的删除操作 lst.remove(1) # 删除列表中的1 s2.discard(5) # 删除集合中的5 # 列表和集合的遍历 for i in lst: print(i) for j in s2: print(j) # 列表和集合的排序 lst2.sort() # 对列表进行排序 s_lst = sorted(list(s2)) # 把集合转为列表后进行排序 print(lst2) print(s_lst)以上代码展示了列表和集合的创建、索引和切片、添加和删除、遍历以及排序等操作。需要注意的是,列表和集合是Python中常用的数据类型之一,在实际应用中的使用非常普遍,因此熟练掌握其输入和输出方式是非常必要的。