怎么去改这一条PHP正则
preg_match_all('#>\s*(\S*)\s*<#Us', $html, $matches);
我现在有这么一条正则,匹配页面上所有的> 与< 之间的字符,好像是这样,我自己猜的,有懂得给我详细解释下吧
问题是,这个匹配我想做个限制,就是除了
非贪婪模式(U)匹配字符串,用正向前瞻不匹配来实现不查找title,下面这个测试正常
<meta charset="utf=8"/>
<?php
$html=<<<str
<a>abc</a>文字文字<b>bbb</b>文字文字<title>title<title>
str;
preg_match_all('#>\s*(\S*)\s*<(?!title)#Us', $html, $matches);
var_dump($matches);
?>
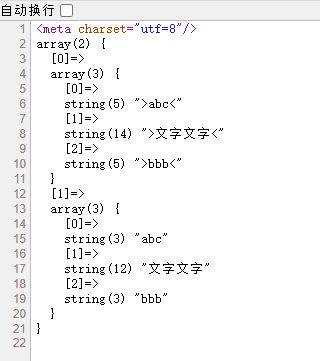
#>\s*(\S*)\s*<#Us
php 中,正则定义可以使用多种符号,只要前后一致即可,比如 你这里, # 表示正则片段,后边 Us 表示正则修饰
> 右尖括号开始
\s* 可以有零个或多个空格
(\S*) 对非空格进行分组匹配,非空格内容可以使零个或多个
\s* 可以有零个或多个空格
< 左尖括号结束
整体来说,这个正则匹配 > 和 < 之间的内容,但其内容只能有一段连续非空格字符,如果有多个字符内容,中间有空格,是无法匹配的
U 没记错的话,应该是修改成非贪婪模式
对于你的需求不匹配 title 之间的内容可以这么写(改动挺大的)
(?<=<(?!title|/)[^<>]*?>)(^[<>]*)(?=</[^<>]*?>)
这个要考虑标签的嵌套,建议用递归平衡组实现。
PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632