BIMPM模型文本匹配
BIMPM模型可以进行文本匹配,好像也可以进行双向的词的交互和文本间的交互。
那么这个模型是否可以理解句意呢?它的优点和缺点是什么?
最近在做深度学习的文本匹配,想与Bert模型做一个对比
感谢大家的回复
- 这篇博客: 【文本匹配】交互型模型中的 8. Bimpm 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
Bimpm可视为对之前各类交互型文本匹配模型的一次总结。
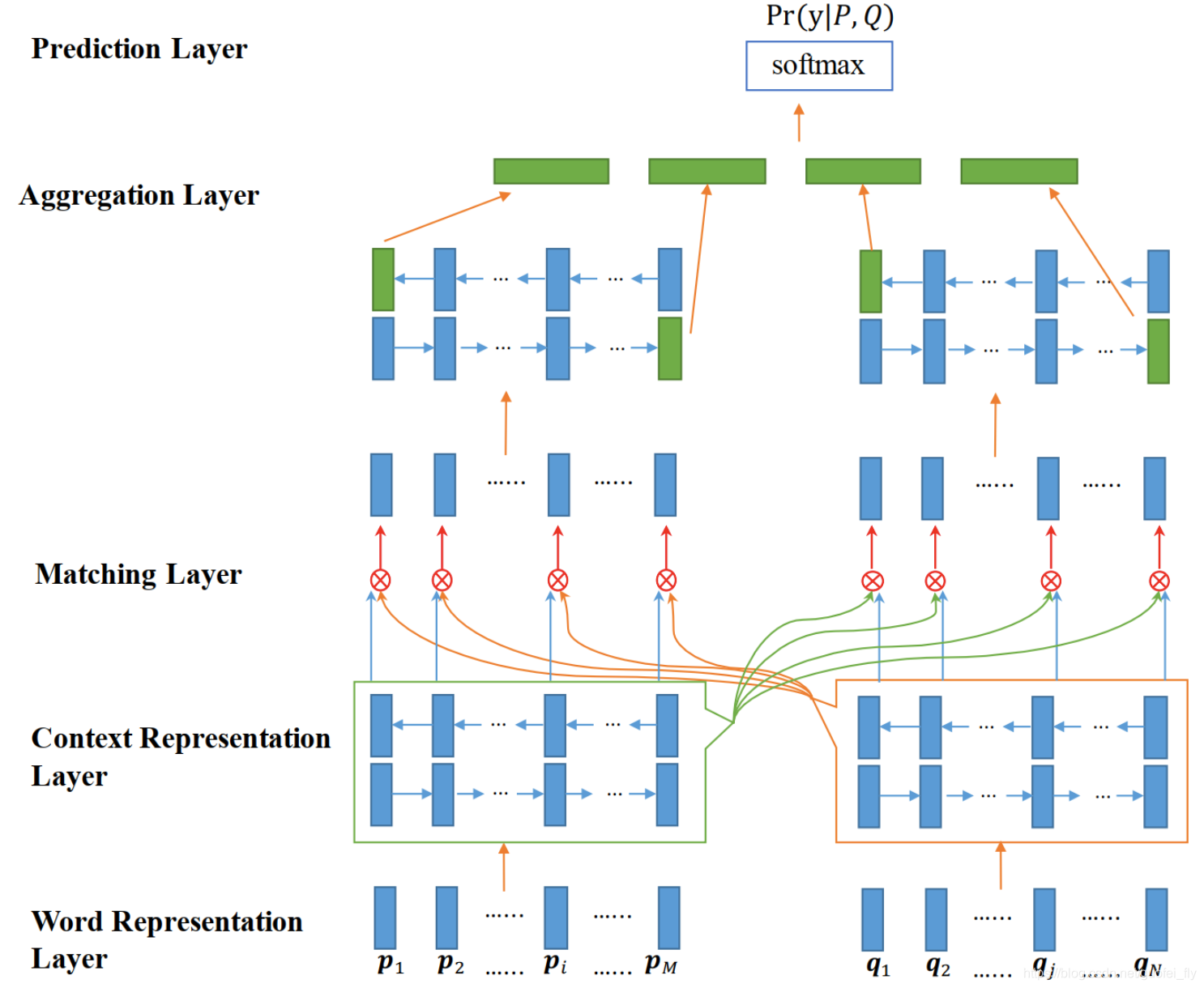
该模型在各层的具体做法总结如下:(1)编码层采用BiLSTM得到每个token隐层的向量表示;
(2)匹配层遵循mk=cosine(Wk∗v1,Wk∗v2)m_k=cosine(W_k*v_1,W_k*v_2)mk=cosine(Wk∗v1,Wk∗v2)的方式可以得到两个文本的任意token pair之间在第k个view下的匹配关系,至于v1v_1v1和v2v_2v2如何取,文章提供了4种策略:
- 策略一:其中一个句子取各token隐层的向量表示,另一个句子采用隐层最后时间步处的输出;
- 策略二:其中一个句子取各token隐层的向量表示,另一个句子采用隐层各时间步输出与之匹配后取再取Max-Pooling值;
- 策略三:其中一个句子取各token隐层的向量表示,另一个句子采用cross-attentive后得到的加权句子向量;
- 策略四:其中一个句子取各token隐层的向量表示,另一个句子采用cross-attentive后attention score最高处token的向量作为句子向量。
这四种策略的区别在于对句子向量的计算不同。
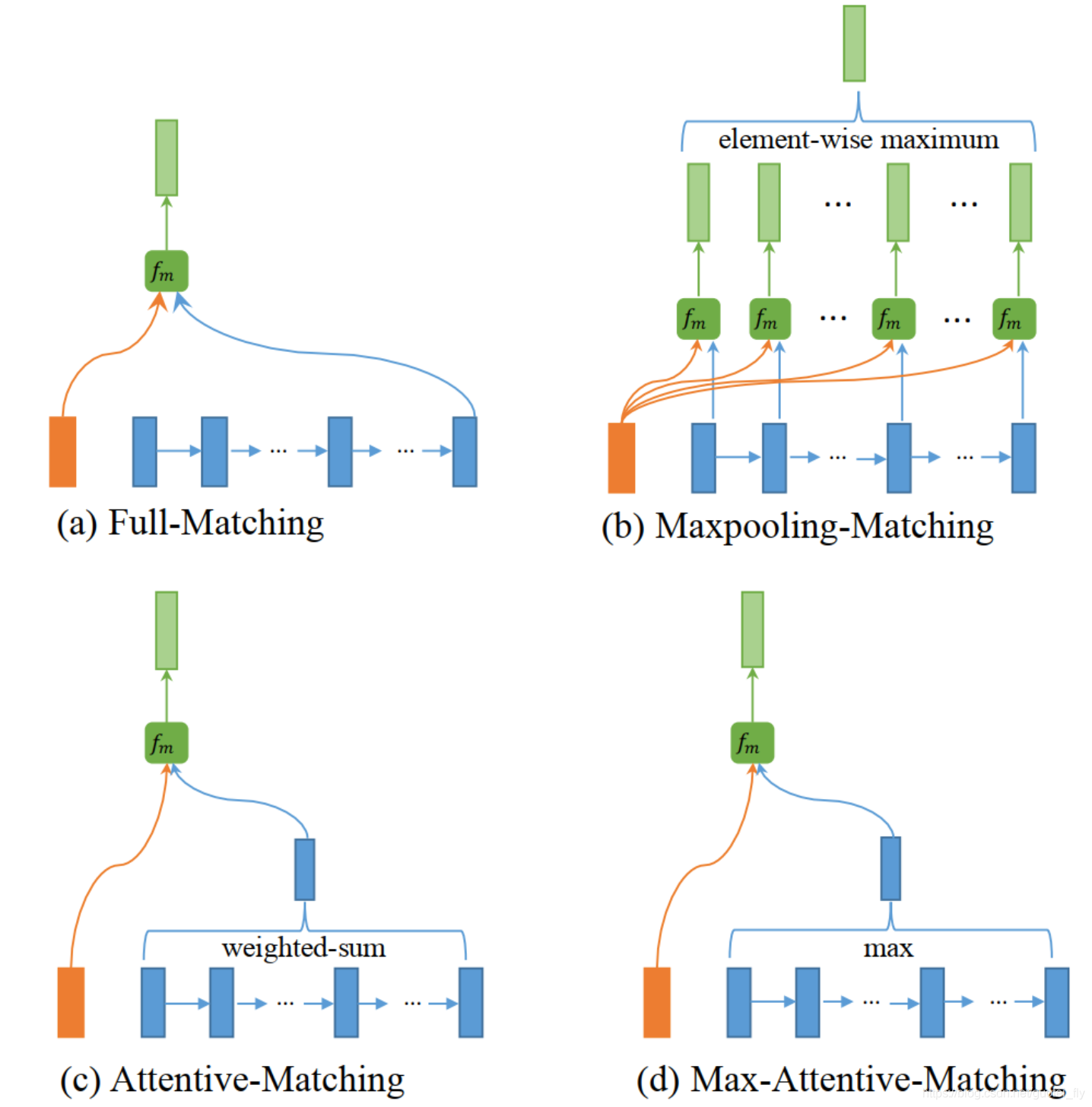
(3)聚合层,首先对上面各种策略得到的输出层再通过一层BiLSTM层,然后将各策略下最后时间步的输出进行拼接,得到最后的聚合向量;(4)预测层:两层MPL+softmax
- 以下回答由chatgpt基于相关博客总结生成:
BIMPM模型可以在一定程度上理解句意,因为它考虑了双边匹配和多角度匹配,从不同角度对比文本,可以更全面地理解句意。关于交互词与文本之间的优缺点,BIMPM模型的优点是可以充分挖掘句子之间的交互信息,提高文本匹配的准确性;缺点则是参数较多,运算速度不够快。与BERT模型进行对比筛选时,可以考虑BIMPM模型的效果、速度和参数量等方面进行比较。
具体解决方案如下:
- 输入层:将每个单词表示为固定词向量和字符向量构成的词向量,输入BiLSTM进行编码。
class InputLayer(nn.Module): def __init__(self, hidden_size, emb_size, vocab_size, dropout=0.1): super(InputLayer, self).__init__() self.embedding = nn.Embedding(vocab_size, emb_size) self.char_embedding = nn.Embedding(vocab_size, emb_size) self.char_lstm = nn.LSTM(emb_size, emb_size // 2, bidirectional=True, batch_first=True) self.dropout = nn.Dropout(dropout) def forward(self, premise, hypothesis, premise_chars, hypothesis_chars): emb_premise = self.embedding(premise) emb_hypothesis = self.embedding(hypothesis) char_emb_premise = self.char_embedding(premise_chars) char_emb_hypothesis = self.char_embedding(hypothesis_chars) batch_size, seq_len = premise.size() char_emb_premise = char_emb_premise.view(batch_size*seq_len, -1, emb_size) char_emb_hypothesis = char_emb_hypothesis.view(batch_size*seq_len, -1, emb_size) _, (char_h_premise, _) = self.char_lstm(char_emb_premise) _, (char_h_hypothesis, _) = self.char_lstm(char_emb_hypothesis) char_emb_premise = char_h_premise.transpose(0, 1).contiguous().view(batch_size, seq_len, -1) char_emb_hypothesis = char_h_hypothesis.transpose(0, 1).contiguous().view(batch_size, seq_len, -1) input_premise = torch.cat([emb_premise, char_emb_premise], dim=2) input_hypothesis = torch.cat([emb_hypothesis, char_emb_hypothesis], dim=2) input_premise = self.dropout(input_premise) input_hypothesis = self.dropout(input_hypothesis) return input_premise, input_hypothesis- 匹配层:采用不同的策略计算两个文本之间的匹配向量,得到多种不同方面的匹配信息。
class MatchingLayer(nn.Module): def __init__(self, hidden_size, dropout=0.1): super(MatchingLayer, self).__init__() self.num_views = 8 self.dropout = nn.Dropout(dropout) self.full_f = nn.Linear(hidden_size * 2, hidden_size, bias=False) self.full_g = nn.Linear(hidden_size * 2, hidden_size, bias=False) self.maxpool_f = nn.Linear(hidden_size * 2, hidden_size, bias=False) self.maxpool_g = nn.Linear(hidden_size * 2, hidden_size, bias=False) self.atten_f = nn.Linear(hidden_size * 2, hidden_size, bias=False) self.atten_g = nn.Linear(hidden_size * 2, hidden_size, bias=False) self.max_atten_f = nn.Linear(hidden_size * 2, hidden_size, bias=False) self.max_atten_g = nn.Linear(hidden_size * 2, hidden_size, bias=False) def forward(self, premise_encoded, hypothesis_encoded): batch_size, p_seq_len, h_seq_len, hidden_size = *premise_encoded.size(), premise_encoded.size(2) # 双向LSTM编码输出 premise_encoded = self.dropout(premise_encoded) hypothesis_encoded = self.dropout(hypothesis_encoded) premise_encoded_full, (premise_hidden_full, _) = self.full_lstm(premise_encoded) hypothesis_encoded_full, (hypothesis_hidden_full, _) = self.full_lstm(hypothesis_encoded) premise_encoded_maxpool, _ = torch.max(premise_encoded, dim=1) hypothesis_encoded_maxpool, _ = torch.max(hypothesis_encoded, dim=1) # 获取匹配信息 views = [] for i in range(self.num_views): if i == 0: # Full-Matching premise_encoded_i = premise_encoded_full.unsqueeze(2).expand(batch_size, p_seq_len, h_seq_len, hidden_size) hypothesis_encoded_i = hypothesis_encoded_full.unsqueeze(1).expand(batch_size, p_seq_len, h_seq_len, hidden_size) match_vector_i = torch.cat([premise_encoded_i, hypothesis_encoded_i], dim=3) mv_f = self.full_f(match_vector_i) mv_g = self.full_g(match_vector_i) elif i == 1: # Maxpooling-Matching premise_encoded_i = premise_encoded.unsqueeze(2).expand(batch_size, p_seq_len, h_seq_len, hidden_size) hypothesis_encoded_i = hypothesis_encoded.unsqueeze(1).expand(batch_size, p_seq_len, h_seq_len, hidden_size) match_vector_i = torch.cat([premise_encoded_i, hypothesis_encoded_i], dim=3) mv_f = self.maxpool_f(match_vector_i) mv_g = self.maxpool_g(match_vector_i) elif i == 2: # Attentive-Matching atten_p2h = torch.matmul(premise_encoded, hypothesis_encoded.transpose(1, 2)) atten_p2h_norm = nn.functional.softmax(atten_p2h.view(-1, h_seq_len), dim=1).view(batch_size, p_seq_len, h_seq_len, 1) atten_h2p = torch.matmul(hypothesis_encoded, premise_encoded.transpose(1, 2)) atten_h2p_norm = nn.functional.softmax(atten_h2p.view(-1, p_seq_len), dim=1).view(batch_size, h_seq_len, p_seq_len, 1) premise_encoded_i = atten_p2h_norm.expand_as(premise_encoded) * premise_encoded hypothesis_encoded_i = atten_h2p_norm.transpose(1, 2).expand_as(hypothesis_encoded) * hypothesis_encoded match_vector_i = torch.cat([premise_encoded_i, hypothesis_encoded_i], dim=3) mv_f = self.atten_f(match_vector_i) mv_g = self.atten_g(match_vector_i) else: # Max-Attentive-Matching atten_p2h, _ = torch.max(torch.exp(atten_p2h - atten_p2h.max(dim=1, keepdim=True)[0]), dim=2) atten_h2p, _ = torch.max(torch.exp(atten_h2p - atten_h2p.max(dim=1, keepdim=True)[0]), dim=2) atten_p2h_norm = nn.functional.softmax(atten_p2h, dim=1).view(batch_size, p_seq_len, 1, 1) atten_h2p_norm = nn.functional.softmax(atten_h2p, dim=1).view(batch_size, h_seq_len, 1, 1) premise_encoded_i = atten_p2h_norm.expand_as(premise_encoded) * premise_encoded hypothesis_encoded_i = atten_h2p_norm.expand_as(hypothesis_encoded) * hypothesis_encoded match_vector_i = torch.cat([premise_encoded_i, hypothesis_encoded_i], dim=3) mv_f = self.max_atten_f(match_vector_i) mv_g = self.max_atten_g(match_vector_i) # 计算匹配向量,并放入列表 align_i = torch.matmul(nn.functional.softmax(torch.matmul(mv_f, mv_g.transpose(2, 3)).view(-1, h_seq_len)).view(batch_size, p_seq_len, h_seq_len, 1), hypothesis_encoded_i).squeeze(3) compare_i = torch.cat([premise_encoded, align_i, premise_encoded - align_i, premise_encoded * align_i], dim=2) view_i = self.view_transformation(compare_i) views.append(view_i) # 拼接不同策略下的匹配向量,得到多种匹配信息 views = torch.cat(views, dim=1) views = self.dropout(views) return views- 聚合层:应用BiLSTM将不同策略下的匹配向量序列聚合成一个定长匹配向量。
class AggregationLayer(nn.Module): def __init__(self, hidden_size, num_layers, dropout=0.1): super(AggregationLayer, self).__init__() self.lstm = nn.LSTM(input_size=hidden_size*8, hidden_size=hidden_size, num_layers=num_layers, bidirectional=True, batch_first=True) self.dropout = nn.Dropout(dropout) def forward(self, views): # 拼接不同策略下的匹配向量,得到多种匹配信息 views = torch.cat(views, dim=1) views = self.dropout(views) # 应用BiLSTM将匹配向量序列聚合成一个定长匹配向量 aggregated, _ = self.lstm(views) aggregated = self.dropout(aggregated[:, -1, :]) return aggregated- 预测层:在聚合层的基础上,应用两层全连接网络和softmax函数进行最终的二分类预测。
```python class Prediction