句子向量化BIMPM等模型
Bert开启了文本相似度的一个新纪元,在它之前也有不错的深度学习模型,那Bert相比之下的优点是什么呢?仅仅因为它的效果好吗? 之前的模型,比如BIMPM都是对 词向量平均得句子向量吗?
- 这篇博客: 短文本匹配/文本蕴含/自然语言推理(一)中的 BiMPM 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
Bilateral Multi-Perspective Matching for Natural Language Sentences
双边多角度句子匹配,这篇文章的创新点在于:1、双边,认为句子不应该仅仅考虑一个方向,从问句出发到答句,也应该从答句去反推问句。2、多角度,在考虑句子间的交互关系时采用了4种不同的方式。这篇文章发表在2017年的IJCAIi,模型取得了很好的效果,但是缺点在于参数很多,运算速度比较慢。
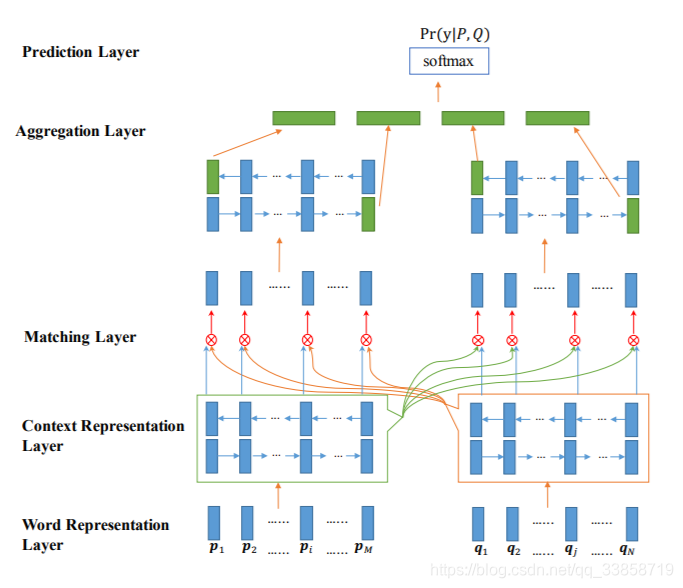
模型的整体框架图,输入是预训练的 glove embeddings 和 chars embeddings,经过 BiLSTM 的编码之后,对每一个step的 LSTM 的输出进行从p到q和从q到p的两两配对,有四种组合方式,然后将所有的结果进行拼接和预测结果。Word Representation Layer
将句子中的每个单词表示为d维向量,这里d维向量分为两部分:一部分是固定的词向量,另一部分是字符向量构成的词向量。这里将一个单词里面的每个字符向量输入LSTM得到最后的词向量。Context Representation Layer
将上下文信息融合到P和Q每个time-step的表示中,这里利用Bi-Lstm表示P和Q每个time-step的上下文向量。Matching Layer
比较句子P的每个上下文向量(time-step)和句子Q的所有上下文向量(time-step),比较句子Q的每个上下文向量(time-step)和句子P的所有上下文向量(time-step)。为了比较一个句子的某个上下文向量(time-step)和另外一个句子的所有上下文向量(time-step),这里设计了一种 multi-perspective匹配方法。这层的输出是两个序列,序列中每一个向量是一个句子的某个time-step对另一个句子所有的time-step的匹配向量。
Multi-Perspective的四种方案: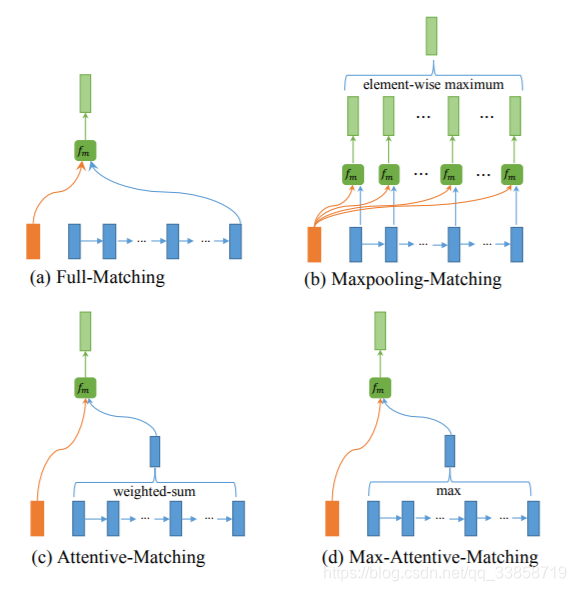
1、Full-Matching:如图a所示,将P在上层LSTM输出的隐藏层每一个 hih_ihi 与Q在上层LSTM最后输入的 hnh_nhn 做计算
2、Maxpooling-Matching:如图b所示,图中清晰地表明了如何操作,不同于Full-matching模式,这里将P与Q在每一个时刻的上一层的隐藏层输出做相应计算,并且在每一维度上取max
3、Attentive-Matching:先计算P中每一个前向(反向)文法向量与Q中每一个前向(反向)文法向量的余弦相似度,然后利用余弦相似度作为权重对Q各个文法向量进行加权求平均作为Q的整体表示,最后P中每一个前向(后向)文法向量与Q对应的整体表示进行匹配。
4、Max-Attentive-Matching:与Attentive-Matching类似,不同的是不进行加权求和,而是直接取Q中余弦相似度最高的单词文法向量作为Q整体向量表示,与P中每一个前向(反向)文法向量进行匹配。Aggregation Layer
聚合两个匹配向量序列为一个固定长度的匹配向量。对两个匹配序列分别应用BiLSTM,然后连接BiLSTM最后一个time-step的向量(4个)得到最后的匹配向量。