python如何在txt文件中每一行后加文字,并保存到新文件中

如何建立一个新的txt文件,然后在旧的文件里的每一行后添加一段文字,并保存到建立的新文件中,然后读取出来
可以使用readlines()函数读取原文件的所有行保存到列表,再遍历每一行,在每一行文件后去除换行符,使用+拼接python成绩,再加一个换行符再写入新文件就可以了。
代码如下:
参考链接:
https://blog.csdn.net/weixin_44245595/article/details/114503612
https://blog.csdn.net/m0_62735081/article/details/124978101
https://www.runoob.com/python3/ref-random-randint.html
https://www.jb51.net/article/279851.htm
import random
# https://blog.csdn.net/wzhrsh/article/details/101629075
with open("shiyan8_3.txt",'w') as f:
with open("shiyan8_1.txt",'r') as f1:
# https://blog.csdn.net/weixin_44245595/article/details/114503612
stus = f1.readlines() # 读取文件的所有行,保存到列表中,每一个元素保存一行
# print(stus)
for stu in stus: # 遍历读取到的每一行
# https://blog.csdn.net/m0_62735081/article/details/124978101
# https://www.runoob.com/python3/ref-random-randint.html
pythonScore = random.randint(60,100) # 产生一个60到99之间的成绩
# https://www.jb51.net/article/279851.htm
stu=stu.strip() # 删除每一行结尾的换行,此函数也可以删除前导的换行符
# 将每一行删除换行后的学生信息,添加上Python成绩,以及一个换行后
# 写入shiyan8_3.txt文件
stu=stu+' Python考试'+str(pythonScore)+'分\n'
f.write(stu)
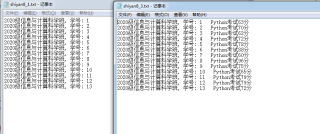
shiyan8_1.txt:(测试数据文件)
2020级信息与计算科学班, 学号: 1
2020级信息与计算科学班, 学号: 2
2020级信息与计算科学班, 学号: 3
2020级信息与计算科学班, 学号: 4
2020级信息与计算科学班, 学号: 5
2020级信息与计算科学班, 学号: 6
2020级信息与计算科学班, 学号: 7
2020级信息与计算科学班, 学号: 8
2020级信息与计算科学班, 学号: 9
2020级信息与计算科学班, 学号: 10
2020级信息与计算科学班, 学号: 11
2020级信息与计算科学班, 学号: 12
2020级信息与计算科学班, 学号: 13
- 你可以看下这个问题的回答https://ask.csdn.net/questions/7702378
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:python读入一个多行的txt文件,给每行的数据加双引号并保存为一行输出
- 除此之外, 这篇博客: 【python】批量重命名文件夹中的所有图片名称和文件夹中所有的txt文件中的 一、介绍 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
最近在做基于YOLOv3的火焰目标检测项目,在制作数据集时,发现图片名称很是杂乱,不利于YOLOv3模型的训练,所以编写python程序对文件夹下的图片和labels文件夹下的txt文件进行批量重命名。
- 您还可以看一下 赵帅老师的Python爬虫基础&商业案例实战课程中的 批量生成舆情报告准备知识点:自动生成txt文件小节, 巩固相关知识点