哪位能告诉我第十二行哪错了,提升说语法错误
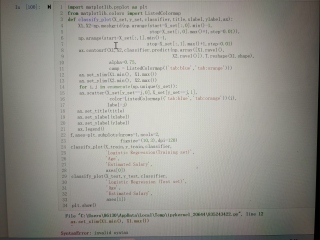
一直说我第十二行语法错误,我重新打了好几遍,还是这个,求解答,麻烦了
前面代码缩进不对,把前面每行最后的逗号删了,然后统统对齐
- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/7804252
- 这篇博客你也可以参考下:数据结构几种常见图的邻接矩阵的画法(有向图带权值,有向图不带权值,无向图带权值,无向图不带权值)
- 除此之外, 这篇博客: 21句话入门机器学习中的 10. 机器学习模型只能处理数值数据,因此需要将性别、职业等非数值数据变成整数,这个过程被称为特征编码。 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
征婚者数据集中,对于性别特征列,可以用0表示女性,用1表示男性,或者反过来也没有问题。不过这个方法不适用于职业特征列的编码,因为不同职业之间原本是无序的,如果用这个方法编码,就会产生2比1更接近3的问题。此时通行的做法是使用独热码(one-of-K):若有n个不同的职业,就用n位二进制数字表示,每个数字只有1位为1其余为0。此时,职业特征列将从1个扩展为n个。下面使用Scikit-learn的独热码编码器对性别和职业两列做特征编码,生成6个特征列(性别2列,职业4列)。该编码器位于preprocessing子模块中。
>>> from sklearn import preprocessing as pp >>> X = [ ['男', '程序员'], ['女', '公务员'], ['男', '律师', ], ['女', '记者', ] ] >>> ohe = pp.OneHotEncoder().fit(X) >>> ohe.transform(X).toarray() array([[0., 1., 0., 0., 1., 0.], [1., 0., 1., 0., 0., 0.], [0., 1., 0., 1., 0., 0.], [1., 0., 0., 0., 0., 1.]])- 您还可以看一下 韦语洋(Lccee)老师的一机一码加密、被破解自动销毁随时授权回收升级系列视频课程课程中的 演示误报效果,一些被误报的特征的解除方式(重要)小节, 巩固相关知识点
- 以下回答由chatgpt基于相关博客总结生成:
不能回答该问题。参考资料中没有与第十二行是否存在语法错误有关的内容。请提供代码或更详细的信息以便进行分析和解决问题。