用PFLD进行人脸96点检测,现在检测出的结果数据如何进行保存(标签-深度学习|关键词-文本文件)
深度学习,用PFLD进行人脸96点检测,现在检测出的结果数据如何进行保存?将坐标数据保存到一个文本文件中?
import argparse
import numpy as np
import cv2
import torch
import torchvision
from models.pfld import PFLDInference, AuxiliaryNet
from mtcnn.detector import detect_faces
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def main(args):
checkpoint = torch.load(args.model_path, map_location=device)
pfld_backbone = PFLDInference().to(device)
pfld_backbone.load_state_dict(checkpoint['pfld_backbone'])
pfld_backbone.eval()
pfld_backbone = pfld_backbone.to(device)
transform = torchvision.transforms.Compose(
[torchvision.transforms.ToTensor()])
img = cv2.imread(r"C:\Users\lenovo\Desktop\xjpic.jpg")
height, width = img.shape[:2]
bounding_boxes, landmarks = detect_faces(img)
for box in bounding_boxes:
x1, y1, x2, y2 = (box[:4] + 0.5).astype(np.int32)
w = x2 - x1 + 1
h = y2 - y1 + 1
cx = x1 + w // 2
cy = y1 + h // 2
size = int(max([w, h]) * 1.1)
x1 = cx - size // 2
x2 = x1 + size
y1 = cy - size // 2
y2 = y1 + size
x1 = max(0, x1)
y1 = max(0, y1)
x2 = min(width, x2)
y2 = min(height, y2)
edx1 = max(0, -x1)
edy1 = max(0, -y1)
edx2 = max(0, x2 - width)
edy2 = max(0, y2 - height)
cropped = img[y1:y2, x1:x2]
if (edx1 > 0 or edy1 > 0 or edx2 > 0 or edy2 > 0):
cropped = cv2.copyMakeBorder(cropped, edy1, edy2, edx1, edx2,
cv2.BORDER_CONSTANT, 0)
input = cv2.resize(cropped, (112, 112))
input = transform(input).unsqueeze(0).to(device)
_, landmarks = pfld_backbone(input)
pre_landmark = landmarks[0]
pre_landmark = pre_landmark.cpu().detach().numpy().reshape(
-1, 2) * [size, size] - [edx1, edy1]
for (x, y) in pre_landmark.astype(np.int32):
cv2.circle(img, (x1 + x, y1 + y), 1, (0, 0, 255))
cv2.imshow('face_landmark_96', img)
if cv2.waitKey(10) == 27:
break
def parse_args():
parser = argparse.ArgumentParser(description='Testing')
parser.add_argument('--model_path',
default="./checkpoint/snapshot/checkpoint.pth.tar",
type=str)
args = parser.parse_args()
return args
if __name__ == "__main__":
args = parse_args()
main(args)
- 这篇博客: 人脸关键点检测之PFLD中的 4. 测试结果 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
检测精度对比如下面的表所示
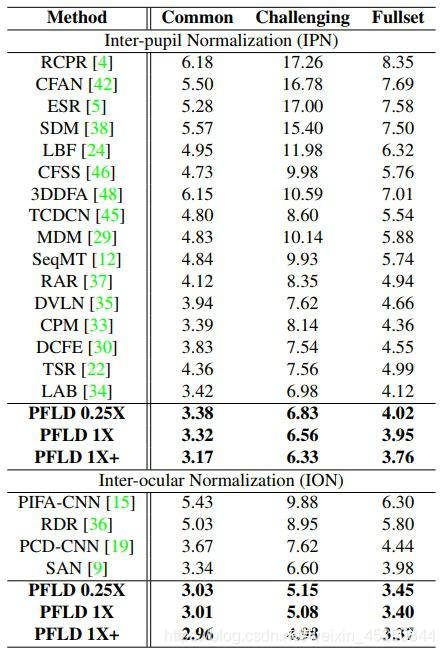
下面来看一下算法处理速度和模型大小,图中C代表i7-6700K CPU,G代表1080 Ti GPU,G*代表Titan X GPU,A代表移动平台Qualcomm ARM 845处理器。
其中PFLD 1X是标准网络,PFLD 0.25X是MobileNet blocks width 参数设为0.25的压缩网络,PFLD 1X+是在WFLW数据集上预训练的网络。下图是该算法在AFLW数据集上与其他算法的精度比较:
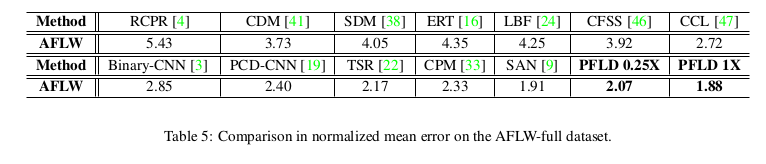
消融实验方面作者仅仅分析了损失函数带来的影响,结果如下表所示。
- 以下回答来自chatgpt:
针对该问题,可以使用Python编写代码将PFLD人脸96点检测的结果保存到文本文件中。具体步骤如下:
确定需要保存的数据格式:检测出来的结果包括人脸关键点的坐标,因此可以使用CSV数据格式保存,每行表示一个人脸的关键点坐标数据。
在PFLD人脸96点检测模型中添加保存数据的代码:在模型的代码中添加保存数据的部分代码,可以使用Python的CSV模块来实现数据保存。
运行模型并查看保存的数据文件:运行模型并检查保存的数据文件,确保数据保存成功。
具体实现代码如下:
import csv # PFLD人脸96点检测模型代码 def detect_landmarks(image_path): # 检测人脸关键点坐标 landmarks = [...] # 保存数据 with open('landmarks.csv', mode='w', newline='') as file: writer = csv.writer(file) for landmark in landmarks: writer.writerow(landmark)在上述代码中,使用了Python的CSV模块中的writer.writerrow()函数来写入每行数据,每行数据是一个包含多个人脸关键点坐标的列表。其中,newline=''参数是为了避免在Windows系统中出现多余的空行。
最后,检查保存的数据文件'landmarks.csv'是否包含了所需的数据格式。如有需要,还可以使用Excel等工具来查看和处理数据。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^