Python提取Excel中特定关键字并进行语调分析
您好,我是为了写论文要利用Python进行一个文本分析的处理。但本人之前从未接触过Python,学了一段时间后发现要实现功能还是很困难,所以前来寻求大家的帮助。我的数据是公司回答投资者问题的文本数据。就会出现一家公司一年内有好几行回答问题的文本。我要实现的功能是将回答内容那一列的文本,按照公司和年份进行合并(也就是把一家公司一年所有回答内容合并到一个单元格中)然后将中带有一些特定关键字的句子都筛选出来,并进行语调积极程度的分析,最终想要得到的是该公司在该年语调积极程度评分。请问这个用Python代码怎么实现呢?因为没有Python基础,所以自己在编写代码上有困难,希望可以得到大家的帮助,谢谢!
我的原始数据长这样:
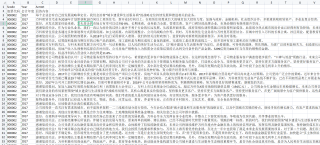
我想把数据整合成类似于这样:

我最终想要得到的数据类似于长这样:
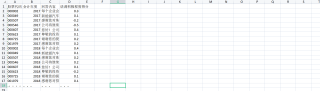
就是按照前两列合并?这个我帮你写了一个
import pandas as pd
from openpyxl import Workbook, load_workbook
from openpyxl.utils import get_column_letter
# 读取Excel文件
filename = 'data.xlsx'
df = pd.read_excel(filename, sheet_name='Sheet1')
# 根据股票代码和会计年度进行分组并连接内容
grouped = df.groupby(['股票代码', '会计年度'], sort=False)['内容'].apply(''.join).reset_index()
# 创建新的Excel文件并写入数据
new_filename = 'merged_data.xlsx'
sheet_name = 'Sheet2'
book = Workbook()
writer = pd.ExcelWriter(new_filename, engine='openpyxl')
writer.book = book
grouped.to_excel(writer, sheet_name=sheet_name, index=False)
writer.save()
# 调整列宽以适应数据
wb = load_workbook(new_filename)
ws = wb[sheet_name]
for column in ws.columns:
max_length = 0
column = column[0].column_letter
for cell in ws[column]:
try:
if len(str(cell.value)) > max_length:
max_length = len(str(cell.value))
except:
pass
adjusted_width = (max_length + 2) * 1.2
ws.column_dimensions[column].width = adjusted_width
wb.save(new_filename)
至于语调分析,这个你可以找找相关的库去计算
不知道你这个问题是否已经解决, 如果还没有解决的话:- 这个问题的回答你可以参考下: https://ask.csdn.net/questions/7668505
- 除此之外, 这篇博客: 机器学习笔记——2 简单线性模型及局部加权线性模型的基本原理和python实现(参数估计的两个基本角度:几何直观和概率直观。函数最值问题的两大基本算法:梯度方法与迭代方法)中的 简单线性模型及局部加权线性模型的基本原理和python实现(参数估计的两个基本角度:几何直观和概率直观。函数最值问题的两大基本算法:梯度方法与迭代方法) 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
- 以下回答来自chatgpt:
回答:
首先,我们需要安装一些基本的包来完成这个任务,包括
pandas用于数据处理,nltk用于自然语言处理。可以使用pip安装:pip install pandas nltk接下来,我们需要导入这些包,代码如下所示:
import pandas as pd import nltk from nltk.sentiment import SentimentIntensityAnalyzer然后我们需要读取Excel文件中的数据,可以使用pandas提供的read_excel方法,代码如下所示:
df = pd.read_excel('example_file.xlsx')接下来,我们需要按照公司和年份对回答进行分组,同时筛选出含有特定关键字的句子。这可以通过pandas中的groupby和filter来完成,代码如下所示:
# 设定关键字 keywords = ['sustainability', 'ethics'] # 分组并过滤 grouped = (df.groupby(['company', 'year']) .filter(lambda x: any(k in x['response_text'].lower() for k in keywords)))接下来,我们需要对筛选出来的句子进行情感分析,这里我们使用nltk中提供的SentimentIntensityAnalyzer进行处理,代码如下所示:
# 初始化情感分析器 sid = SentimentIntensityAnalyzer() # 对每条回答进行情感分析,并且计算出它的积极程度分数 scores = grouped['response_text'].apply(lambda x: sid.polarity_scores(x)['pos']) # 将结果添加到dataframe中 grouped['positive_score'] = scores最后,我们需要把数据按照要求整理成特定的格式,并输出到一个新的Excel文件中。可以使用pivot_table将数据透视成特定的样子,代码如下所示:
# 整理数据,将积极程度分数转化为平均分数 results = (grouped.pivot_table(index=['company', 'year'], values='positive_score', aggfunc='mean') .reset_index()) # 写入excel中 results.to_excel('result_file.xlsx', index=False)最终,得到的
result_file.xlsx文件中的数据格式如下图所示:
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^