决策树的模型的可视化
import pandas as pd
from sklearn.tree import DecisionTreeRegressor
from sklearn import preprocessing
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import GridSearchCV
# 读取含有热误差数据的CSV文件
train_file = open('data8.csv', encoding='utf-8')
train_df = pd.read_csv(train_file)
train_file = open('date18.csv', encoding='utf-8')
train_df = pd.read_csv(train_file)
# 读取测试集的含有热误差数据的CSV文件
test_file = open('data.csv', encoding='utf-8')
test_df = pd.read_csv(test_file)
# 对训练集进行数据预处理
X_train = train_df.iloc[:, :-1]
Y_train = train_df.iloc[:, -1]
X_train_scaled = preprocessing.scale(X_train)
# 对测试集进行数据预处理
X_test = test_df.iloc[:, :-1]
Y_test = test_df.iloc[:, -1]
X_test_scaled = preprocessing.scale(X_test, with_mean=X_train_scaled.mean(axis=0)[0], with_std=X_train_scaled.mean(axis=0)[0])
X = pd.concat([test_df.iloc[:, :-1], train_df.iloc[:, :-1]], axis=1)
Y = pd.concat([test_df.iloc[:, -1], train_df.iloc[:, -1]], axis=1)
X_test.columns = X_train.columns
# 创建决策树模型
dt = DecisionTreeRegressor()
# 定义网格搜索参数
param_grid = {
'max_depth': [1,2,3,4,5,6,7,8,9],
'min_samples_split': [2, 4, 6],
'min_samples_leaf': [1, 2, 3]
}
# 进行网格搜索优化
grid = GridSearchCV(dt, param_grid, cv=5, error_score='raise')
grid.fit(X, Y)
grid_search = GridSearchCV(DecisionTreeRegressor(), param_grid, cv=5)
grid_search.fit(X_train, Y_train)
best_model = grid_search.best_estimator_
# 输出最优参数和模型得分
print('Best Parameters:', grid.best_params_)
# 定义新的温度数据
# 输出预测结果
Y_pred = best_model.predict(X_test)
mse = mean_squared_error(Y_test, Y_pred)
print(f"MSE: {mse:.4f}")
print(Y_pred)
X_test = pd.concat([X_train, X_test], axis=0, ignore_index=True)
怎么把这个决策树的模型给他画出来
python中有个graphviz库可以实现可视化操作,如果本地没有,需要手动先安上
安好之后要先训练一下,根据你给出的代码可以按以下方式训练
# 训练决策树模型
best_dt = DecisionTreeRegressor(max_depth=grid.best_params_['max_depth'], min_samples_leaf=grid.best_params_['min_samples_leaf'], min_samples_split=grid.best_params_['min_samples_split'])
best_dt.fit(X_train, Y_train)
训练好之后,就可以进行可视化了,如下
from sklearn.tree import export_graphviz
import graphviz
dot_data = export_graphviz(best_dt, out_file=None,
feature_names=X_train.columns,
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph.render("decision_tree")
正常情况下你可以得到一个pdf文件,并在文件中得到可视化的决策树。
希望能帮到你,加油~~
print('Best parameters: ', grid_search.best_params_)
print('Best score: ', grid_search.best_score_)
print('Test set score: ', grid_search.score(X_test, Y_test))
- 帮你找了个相似的问题, 你可以看下: https://ask.csdn.net/questions/7673332
- 你也可以参考下这篇文章:转移性乳腺癌的基因组图谱突出了突变和特征频率的变化
- 除此之外, 这篇博客: 个人总结:从 线性回归 到 逻辑回归 为什么逻辑回归又叫对数几率回归?中的 二元逻辑回归的损失函数 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
线性回归的输出是线性的,所以可用误差平方和来定义损失函数。但是逻辑回归不是连续的,但是可以用最大似然估计法来推导出损失函数。
如果输出是0和1两类,假定输入样本x,用
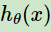 表示训练样本x条件下预测y = 1的概率,则
表示训练样本x条件下预测y = 1的概率,则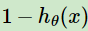 为相应样本预测y = 0的概率。
为相应样本预测y = 0的概率。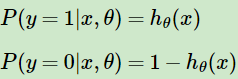
可以看出符合样本符合0-1分布(伯努力分布),将其合并则有概率分布表达式
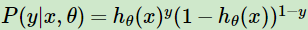 ,y为0时则是预测y = 0的概率,y为1时预测y = 1的概率。
,y为0时则是预测y = 0的概率,y为1时预测y = 1的概率。有了概率分布表达式,则可以通过极大似然估计来求解需要的模型系数了。
极大似然估计:最合理的参数估计量应该使得从模型中抽取该n组样本观测值的概率最大。打个比方:一个袋子中有20个球,只有黑白两色,有放回的抽取十次,取出8个黑球和2个白球,计算袋子里有白球黑球各几个。那么我会认为我所抽出的这个样本是被抽取的事件中概率最大的。设取黑球的概率为p, p(黑球=8) = p^8*(1-p)^2,让这个值最大。极大似然法就是基于这种思想。

于是,逻辑回归的似然函数的代数表达式就为极大似然估计,我们要让以下损失函数最大:
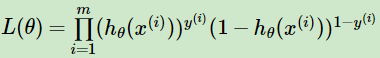 ,其中m为样本个数。
,其中m为样本个数。接着对似然函数对数化,得到对数似然损失函数表达式为:
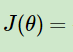
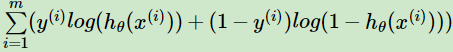
这其实正好也是二分类模型的交叉熵代价函数。
将sigmoid代入,最后得到的式子为:
,这其实就是Logistic Loss的其中一种写法,此时
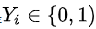 。
。当
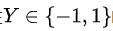 ,可以写成另外一种形式,
,可以写成另外一种形式,。可见当yi均为1时两个形式相等,而第一个形式当yi为0时,对应第二个形式yi为-1。
接下来,我们要找到使损失函数最大的参数θ。
通过取反,转换为找到损失函数最小时的参数θ,这个时候就可以用梯度下降法:
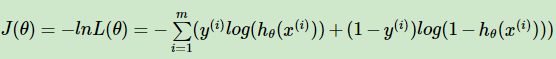
其矩阵形式为:
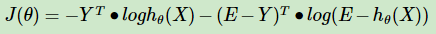
为什么用极大似然估计而不用最小二乘法?
实际上也可以使用最小二乘,但是最小二乘得到的权重效果比较差,因为使用最小二乘法,目标函数就是差值的平方和,是非凸的,不容易求解,容易陷入到局部最优解。
如果使用极大似然估计,目标函数就是对数似然函数,是关于(w, b)的高阶连续可导凸函数,可以方便通过一些凸优化算法求解,比如梯度下降、牛顿法等。
- 您还可以看一下 孙玖祥老师的图解数据结构与算法课程中的 循环队列的入队出队扩容操作小节, 巩固相关知识点