NLP电影评论情感分析项目中将最佳模型的重要系数可视化这一步为啥报这样的错 网上也没搜到
NLP电影评论情感分析项目中将最佳模型的重要系数可视化
这一步为啥报这样的错 网上也没搜到

- 帮你找了个相似的问题, 你可以看下: https://ask.csdn.net/questions/7763874
- 这篇博客你也可以参考下:逐层贪婪预训练(解决梯度消失的第一个成功方案,但现在除了NLP领域外很少使用)
- 除此之外, 这篇博客: 针对无监督学习NLP任务,梳理非结构化文本背后的方法和经验中的 那么,词向量是如何训练的? 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
word2vec 词向量模型有两种训练模式 —Skip-gram (Continuous Skip-gram Model) 和 CBOW (Continuous Bag-of-Words Model),如下图所示。这两种模型的基本原则大致是相同的 —— 两者都是用于将文本进行向量表示的实现方法,而单词的信息就依赖于所处的上下文语义信息中。
例如,“Man” 和 “Woman” 可以在非常相似的上下文中使用,比如下面两句话间的对比,“Man can do something” 和 “Woman can do something”,除了主语不同,上下文的结构完全一致。在数百万计的句子和标记中,结合这些上下文信息,统计归纳出 “Man” 和 “Woman” 在用法上是相关的,而 “Man” 和 “he/him” 以及 “Woman” 和 “she/her” 也具有相关性。因此,在大型数据集上,基于这些词在不同的句子,不同的语境中使用而形成的关联,词向量开始变得更有意义。
其中,CBOW 模型是用上下文预测中心词,而 Skip-gram 模型则用于预测当前中心词的周围单词。例如,在句子 “climate change is affecting nature adversely.” 中,CBOW 模型将试图根据上下文来预测这个词的影响,也就是句子中围绕中心词的其他单词。下图给出了两种方法的演示。
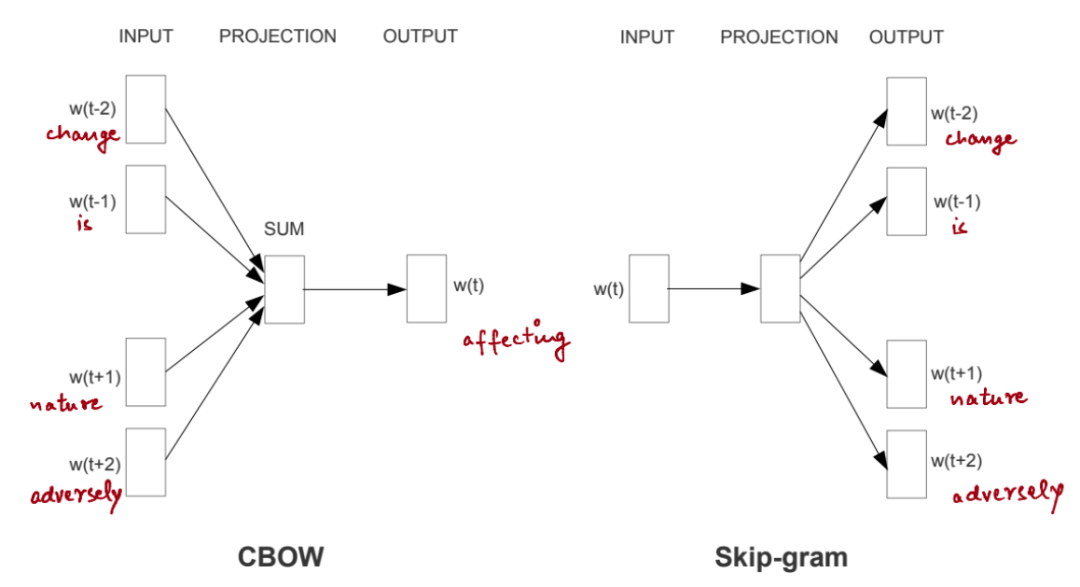
为训练单词向量建模变量。图片出处:Efficient Estimation of Word Representations in Vector Space [1]
当你在包含网络文章等内容的大型数据集上训练这样一个超过数十亿标记的模型时,你得到的是词汇表中每个单词的非常有效的表示,而且均以向量的形式进行呈现。这些向量长度可能是 300 维,即每个单词由 300 个实数表示。如下图所示,给出了解释这些向量最著名的例子。
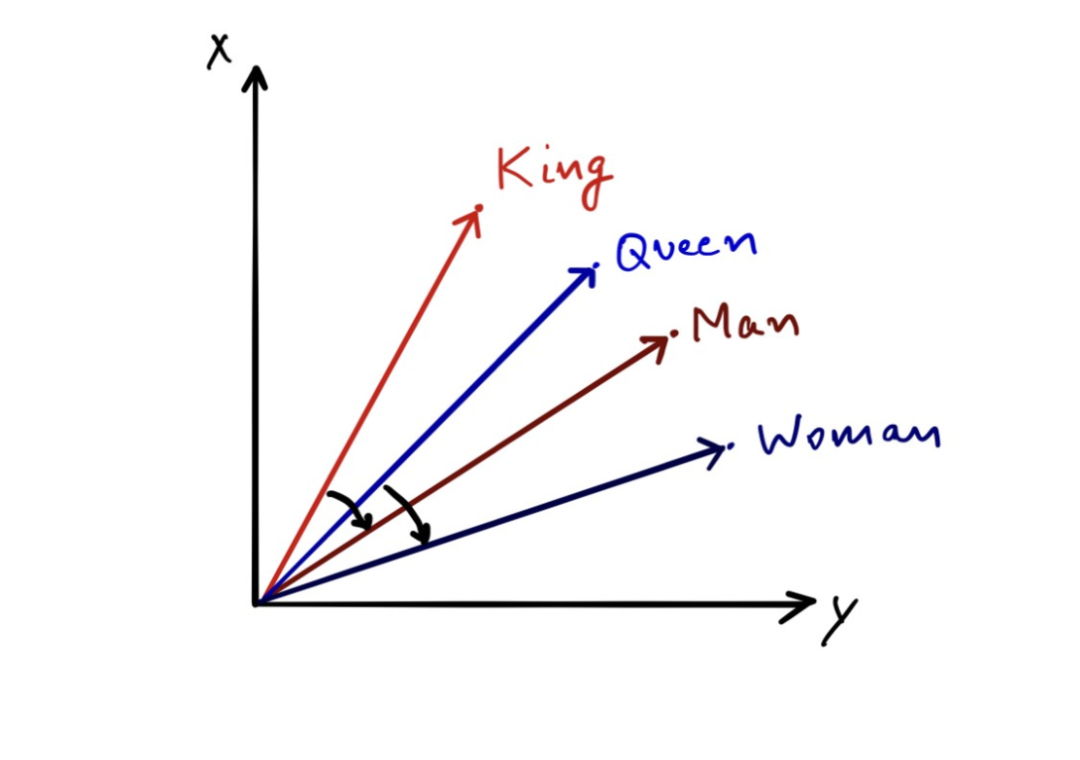
图像源自作者:二维空间可视化解释词向量的示例。
基于上图,假设下列向量方程成立:
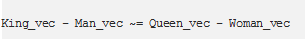
通俗一点解释,也就是说,像上述公式中出现的成对单词,向量投射出相似的关系。
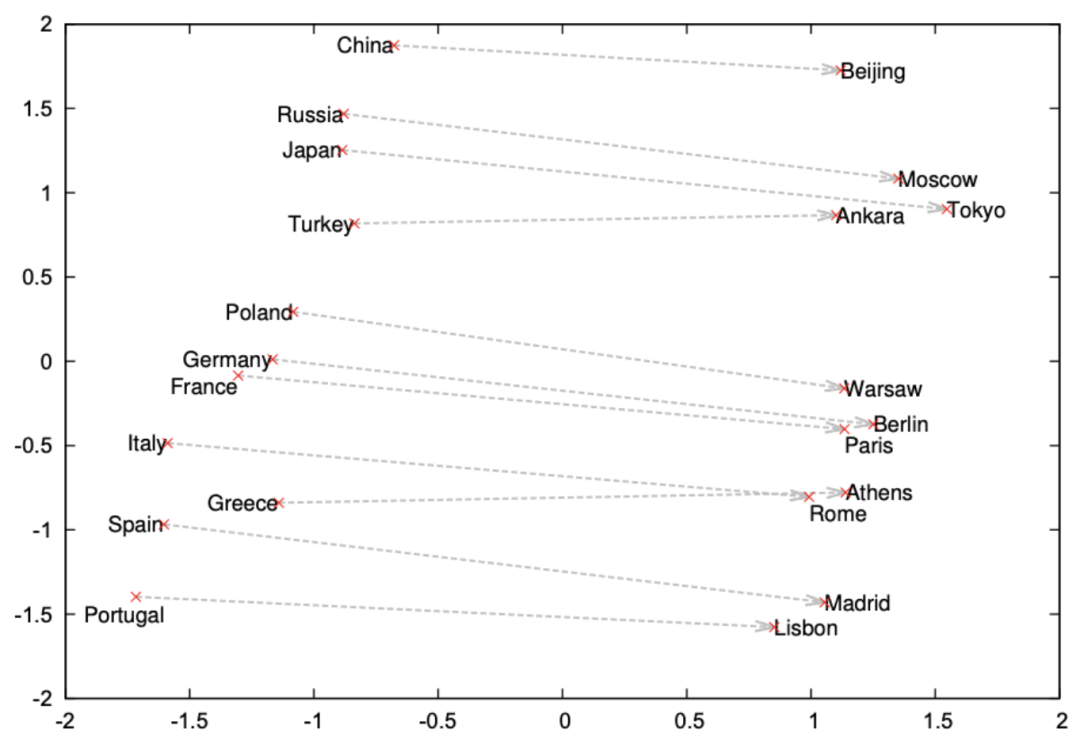
字词向量体现了各国与首都之间的关系。图片出处:papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf
在真实的应用程序中,词向量可以展现其非常有趣的特性。正因为有了词向量,机器就能够以更像人类的方式理解和处理文本。一般来说,对文字和文本的理解也延伸到了其他多样化的媒体形式,诸如演讲、图像和视频之类的,但前提条件是这些形式需要先转换为文本,然后再进行进一步处理。稍后将对此进行更多地介绍。
在 word2vec 中,我们并没有直接利用构词学中的信息:不管是在 Skip-gram 还是 CBOW 模型中,面对形态不同的单词,如,“dog” 和 “dogs”,用不同的向量进行表示,因此,模型并未直接表达这两个向量之间的关系。鉴于此,在 2017 年发表的一篇论文 [3] 中,fastText 提出了名为子词嵌入(sub-word embeddings)的方法来构造向量,显然,词向量的表示质量有了显著的提高。
在语料库中的很多单词,都存在较多公共的字符,即内部形态相似,比如,“book” 和 “books”,如果使用传统的 word2vec,两者间共性的信息会由于转换不同的 id 而丢失,因此,为了克服问题,选择使用字符级的 n-grams 表示一个单词。以 “where” 单词为例,将其分解为子单词或 n-grams 表示,试图将构词信息引入 word2vec 中的 CBOW 模型,此处,n 的取值为 3,则具体的表示形式为:

然后将这些子词向量组合以构建词向量。这种方式有助于更好地学习语言中单词之间的联系。可以想象为,我们用一种更细粒度的方式去探索更深层次的知识。这有助于学习现象,甚至从语言引理的角度上,从词汇内部出发。例如,“cat” 和 “cats” 之间的区别就像 “dog” 和 “dogs” 这样的词对一样。以此类推,“boy” 和 “boyfriend” 与 “girl” 和 “girlfriend” 也有相同的关系。这种方法还有助于为词库外(OOV, out of vocabulary)单词的创建提供更有意义的表示,这些单词是模型在训练集中还未曾见过的。
词向量可有效的用于快速计算,尤其是在计算资源有限的情况下。在各种语料库 (新闻、网络、社交媒体,如 Twitter 和 Reddit 等等) 中找到预训练的词向量很容易。你可能想在最接近应用程序数据集的数据集上训练的词向量。比如,在 twitter 数据集上训练的词向量会与在新闻类文章上训练的词向量有所不同。
词向量可以用来构造单词或句子的向量,以辅助其用于相似度计算或聚类任务。即使是为数据集绘制词云这样的简单任务,也称得上是分析数据集的强大方法。然而,词向量的真正魅力还是得通过语言建模进行诠释。

图片源自作者:这篇文章生成的词云
- 您还可以看一下 王雅宁老师的自然语言处理实战入门课程中的 如何使用NLP技术给孩子起一个中文名字?小节, 巩固相关知识点