关于独立应用程序的问题如何解决
编写独立应用程序实现数据去重
对于两个输入文件A和B,编写Spark独立应用程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新文件R。
已经创建好A.txt和B.txt
下面是创建R.py的
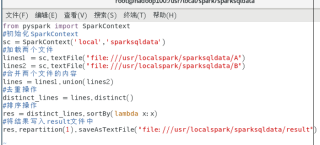
输入python3 R.py后
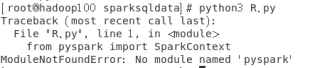
对于
```scala
from spark import SparkContex
```t出现ModuleNotFoundError: No module named 'pyspark'的问题
求解
由于pyspark不在python的环境变量下,将资源的目录配置到python的环境变量下即可。
例如:export PYTHONPATH=${SPARK_HOME}/python:${SPARK_HOME}/python/pyspark.zip:${SPARK_HOME}/python/lib/py4j-0.10.8.1-src.zip:$PYTHONPATH
- 以下回答来自chatgpt:
首先,我们可以使用Spark的
union函数将A.txt和B.txt合并成一个RDD,并使用distinct()函数对RDD中的元素进行去重,最终将去重后的结果保存到R.txt中。以下是代码示例:
from pyspark import SparkConf, SparkContext # 创建SparkConf对象 conf = SparkConf().setAppName("deduplicate").setMaster("local") # 创建SparkContext对象 sc = SparkContext(conf=conf) # 加载A.txt和B.txt rdd1 = sc.textFile("A.txt") rdd2 = sc.textFile("B.txt") # 合并rdd1和rdd2 rdd = rdd1.union(rdd2) # 对合并后的RDD进行去重 deduplicated_rdd = rdd.distinct() # 保存去重后的结果到R.txt中 deduplicated_rdd.saveAsTextFile("R.txt")其中,
textFile函数可以读取文本文件中的内容并返回一个RDD,union函数可以将两个RDD合并成一个,distinct函数可以对RDD中的元素进行去重,saveAsTextFile函数可以将结果保存到文本文件中。上述代码中,需要将A.txt和B.txt放在相应的路径下,例如将它们放在与该Python文件同一目录下,即可使用相对路径进行读取。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^