python tkinter的GUI制作 词频统计
我的代码中我想让entry中输入的内容作为我检索词频的词语的内容,这应该如何操作?
还有想让count的结果作为messagebox中输出文本的内容,要怎么操作呢?
还有加入图片之后窗口的大小出现改变,这要怎么办呢?
下附件源代码,求大家指点!
import tkinter as tk # 在代码里面导入库,起一个别名,以后代码里面就用这个别名
import messagebox
import tkinter.messagebox
import matplotlib
import seaborn as sns
#matplotlib.use('agg') #用这个界面不出图片 主窗口正常
matplotlib.use('TKAgg') #用这个出图片但是窗口还是很小 不起作用
root = tk.Tk() # 这个库里面有Tk()这个方法,这个方法的作用就是创建一个窗口
root.title('文字提取与词频统计')
root.geometry('580x240')
#文字提示
label=tk.Label(text='请输入小说名称')
label.place(x=30,y=0)
#输入框1
entry1 = tk.Entry(root,width=50)
entry1.place(x=30,y=30)
#按钮1
def getTextInput(entry1):
result =entry1.get()
print(result)
button=tk.Button(root,text='保存文档',bg="light blue" )
button.place(x=450,y=25)
#文字提示
label1=tk.Label(text='请输入想要统计出现频率的字词')
label1.place(x=30,y=70)
#输入框2
entry2 = tk.Entry(root,width=50)
entry2.place(x=30,y=100)
#文字提示
label2 = tk.Label(root)
label2.place(x=180,y=140)
#以上是GUI引入库 下面库为源代码编程部分
import jieba #引入jieba库用于分词
import wordfreq #引入wordfreq库用于分词
import collections #词频统计库
import numpy as np #numpy数据处理库
import matplotlib.pyplot as plt #图像展示库
import requests
import bs4
import os
from bs4 import BeautifulSoup
from lxml import etree
url = 'https://hongloumeng.5000yan.com/'
re = requests.get(url)
re.encoding="utf-8"
selector=etree.HTML(re.text)
urs=selector.xpath("/html/body/div[2]/div[1]/main//@href")
Y=0
for i in urs:
urls1 = i
re1 = requests.get(urls1) # re1章节页面
re1.encoding = "utf-8"
selector1 = etree.HTML(re1.text)
内容 = selector1.xpath("/html/body/div[2]/div[1]/main/section/div[1]//text()")
neir = ""
for x in 内容:
neir = neir + str(x) + "\n"
with open("红楼梦.txt", "a", encoding = "utf-8") as f:
f.write(neir)
Y = Y + 1
print(f"第{Y}回下载完成")
#创建一个文件夹
import os
os.mkdir(r'D:\Python文档保存')
os.mkdir(r'D:\Python文档保存\文档保存.txt')
path="文档保存.txt"
f=open("红楼梦.txt","r",encoding="utf-8")#r表示文件只读
text=f.read()
f.close
plt.rcParams['font.sans-serif']='SimHei'
sWords=jieba.lcut(text)
wordlist=[]
#word1=entry1.get()
#word2=entry2.get()
words=['黛玉','宝玉']
for word in sWords:
if word in words:
wordlist.append(word)
word_counts=collections.Counter(wordlist)
plt.xlabel('高频词语',fontproperties="SimHei",fontsize=20)
plt.ylabel('出现频率/次',fontproperties="SimHei",fontsize=20)
scale_x=range(10)
x=[]
y=[]
word_counts_list=[(key, value) for key, value in word_counts.items()]
for i in range(len(word_counts)):
x.append(word_counts_list[i][0])
y.append(word_counts_list[i][1])
plt.title("红楼梦词频统计",color='red',fontsize=20)
plt.bar(x,y,width=0.5,color='c')
for i in range(2):
plt.annotate(y[i], xy=(i, y[i]), xytext=(i, y[i] + 1), color='red', ha='center', fontsize=15)
sns.despine()
plt.savefig('D:\Python文档保存\红楼梦.png')
#按钮2
result= 'collections.Counter(wordlist)'
def show_result(): # 显示输出结果在messagebox中
messagebox.showinfo("输出结果", result)
button1=tk.Button(root,text='开始统计',bg="light blue",command=show_result)
button1.place(x=450,y=95)
#按钮3
button2=tk.Button(root,text='词频统计图',bg="#7CFC00",command=plt.show)
button2.place(x=180,y=165)
root.mainloop()
- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/7717957
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:Python 弹出提示框练习:tkinter.messagebox使用方法
- 同时,你还可以查看手册:python-tkinter.messagebox --- Tkinter 消息提示 中的内容
- 除此之外, 这篇博客: Python记8(tkinter中的 6、Entry 单行文本框、messagebox 弹窗 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
- Entry的可选参数参考:https://blog.csdn.net/qq_41556318/article/details/85108328
- 接受一行字符串(多行字符请用Text控件)。如果用户输入的文字长度长于Entry控件的宽度时,文字会自动向后滚动。
- 可以使用tkinter定义的类型接受文本框内容:
tkinter.Variable派生了:
tkinter.BooleanVar
tkinter.IntVar
tkinter.DoubleVar
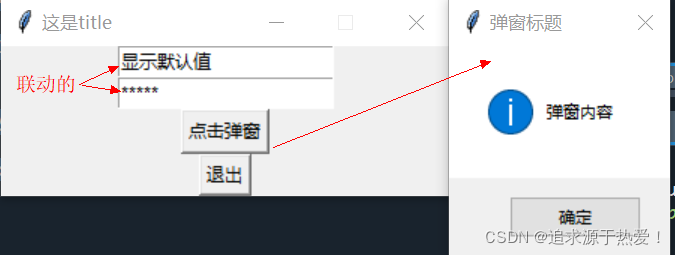
tkinter.StringVarfrom tkinter import * from tkinter import messagebox root = Tk() # 实例化tk类,需要配合后面root.mainloop()才能循环显示弹框 root.geometry('300x100+500+300') # 宽300,长100,边框距离屏幕最左端距离为500,与最上端距离为300(也可以用最右/下端用减号-) root.resizable(False, False) # 不准拉伸(宽,高) root.title('这是title') # 设置弹框名称 entryStr = StringVar() # 接收文本框字符,StringVar 继承 tkinter.Variable entryStr.set("显示默认值") entry = Entry(root, textvariable=entryStr) # 文本框中的内容和entryStr是联动的 entry.pack() Entry(root, textvariable=entryStr, show="*").pack() def tanchuang(): print(entry.get()) messagebox.showinfo("弹窗标题", "弹窗内容") button = Button(root, text="点击弹窗", command=tanchuang) button.pack() Button(root, text="退出", command=root.destroy).pack() root.mainloop() # 循环弹窗