FDR矫正后的p值反而减小?
FDR矫正数据的问题
为什么我用mafdr矫正后的p值反而都比矫正前小呢?
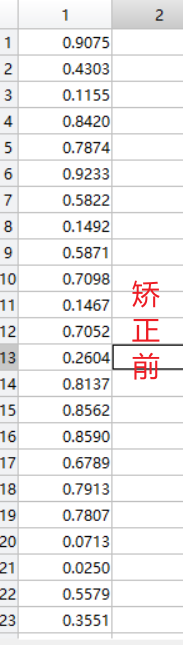
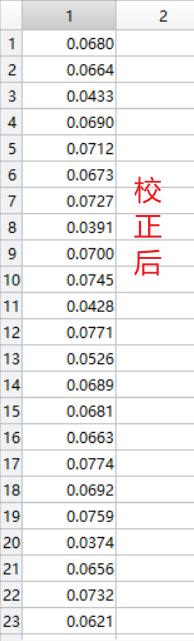
基于Monster 组和GPT的调写:
可能是由于以下原因:
- 原始的p值存在显著偏差:如果原始的p值受到了某些偏差的影响,如过度控制类型I误差的影响,那么进行FDR矫正后可能会减小这种偏差。
- 样本量较小:在样本量较小的情况下,FDR矫正可能会导致p值的降低。这是因为FDR矫正算法会考虑多个假设之间的相关性,从而降低了多重比较的误差。
- 无论是哪种情况,矫正后的p值都应该更可靠,因为它考虑了多重比较问题。可以检查一下FDR矫正的过程是否正确或尝试使用其他的多重比较矫正方法来验证结果。
FDR(矫正后的P值)问题
可以借鉴下
https://blog.csdn.net/weixin_40640700/article/details/104976715
该回答引用chatgpt:
在进行多重假设检验时,FDR(False Discovery Rate)矫正可以控制假阳性率,即控制错误拒绝原假设的概率。一般来说,经过FDR矫正后的p值应该比未矫正的p值更严格,更加保守。
如果您使用的是MATLAB的mafdr函数进行FDR矫正,那么它会返回调整后的p值以及对应的拒绝/接受假设的结果。如果您的研究假设是探索性的,那么经过FDR矫正后,可能会有更多的假设被拒绝。这可能导致您观察到的矫正后的p值比未矫正的p值更小。
另外,mafdr函数默认使用Benjamini-Hochberg方法进行FDR矫正。该方法会对所有的p值进行排序,然后根据调整后的α值确定最小的p值阈值,使得在这个阈值下,控制错误拒绝原假设的FDR不超过α。由于该方法的实现方式,可能会导致一些较小的p值被放大,而一些较大的p值被缩小。这也可能会导致您观察到的矫正后的p值比未矫正的p值更小。
总之,如果您对矫正后的p值比未矫正的p值更小感到困惑,可以考虑检查您的数据、假设以及FDR矫正的具体实现方式,以确定您的研究结果是否正确。
该回答通过自己思路及引用到GPTᴼᴾᴱᴺᴬᴵ搜索,得到内容具体如下:
在使用 FDR 矫正时,可能会出现矫正后的 p 值反而比矫正前小的情况。这通常是由于原始的 p 值不符合一些假设前提条件,例如独立性、同方差性等,导致矫正后的 p 值出现异常。
有几个可能的原因:
原始的 p 值不符合独立性假设:在统计分析中,每个 p 值都应该是独立的,但是在实际情况中,很多时候不同的 p 值之间可能存在相关性。如果原始的 p 值不符合独立性假设,那么 FDR 矫正就可能出现问题,导致矫正后的 p 值不准确。
原始的 p 值不符合同方差性假设:在统计分析中,假设不同的样本或者数据点具有相同的方差,如果原始的 p 值不符合同方差性假设,那么 FDR 矫正也可能出现问题。
FDR 矫正的假设不符合实际情况:FDR 矫正的前提是假设绝大多数的 null hypothesis 是正确的,但是在某些情况下,这个假设可能不成立。例如,在一些实验中,可能存在多个显著差异的指标,如果同时对这些指标进行 FDR 矫正,那么可能会把真实的显著差异掩盖掉。
如果出现这种情况,建议您重新检查数据的质量,确保满足 FDR 矫正的假设前提条件,并尝试使用其他的多重比较矫正方法进行分析。此外,您也可以尝试使用 permutation test 等方法来进行验证。
如果以上回答对您有所帮助,点击一下采纳该答案~谢谢
FDR矫正后的p值反而减小?FDR矫正数据的问题
为什么我用mafdr矫正后的p值反而都比矫正前小呢?
mafdr是基于Benjamini-Hochberg过程的多重比较校正方法之一,用于控制假阳性率(False Discovery Rate,FDR)。mafdr对原始p值进行调整以控制FDR,并返回经过调整的修正p值。
通过FDR校正显著性水平会更加保守。如果您使用了mafdr来校正p值,可能会将一些原本不显著的结果标记为显著,但矫正后的p值并不是直接与未矫正的p值进行比较的,因此不能直接将两者进行比较。mafdr返回的是已经校正过的p值,需要根据校正后的p值确定显著性水平。
另外,在测试数据集上使用mafdr时,要特别注意你输入的p值是否足够稳健。当一些p值非常小并且噪声相对较低时,mafdr的效果可能会很好,但在其他情况下,mafdr对FDR的控制可能不太准确,这可能导致校正后的p值反而变小。所以在使用mafdr时要谨慎,同时建议结合其他方法进行验证。
以下答案由GPT-3.5大模型与博主波罗歌共同编写:
FDR (False Discovery Rate) 矫正是一种多重检验校正的方法,可以控制假阳性率。在使用FDR矫正时,矫正后的p值应该比矫正前的p值要大。如果使用MAFDR矫正后的p值反而比矫正前的p值小,可能是以下原因之一:
数据误导:在研究中,可能存在数据处理中的误差,例如样本处理不当,引入了组间差异,这可能导致矫正前的p值不准确。这种情况下,可能需要重新检查数据处理流程。
统计模型选择:不同的统计模型可能导致不同的矫正结果。因此,正确的模型选择对于得到准确的矫正结果是必要的。例如,如果您使用的是t检验,可能需要使用Benjamini-Hochberg过程对p值进行FDR矫正,而如果使用wilcox.test,则需要使用sapply(maFDR),而不是sapply(p.adjust)。
代码实现:在实现过程中,可能存在错误或者误差。例如,在使用p.adjust函数中,可能需要指定使用的矫正方法(method参数),而不是默认使用的BH方法。如果忽略了这个参数,矫正结果可能会出现错误。
下面是一个例子,说明如何使用MAFDR矫正:
# 创建随机数据
set.seed(123)
pvalues <- runif(n = 100, 0, 1)
# 用p.adjust实现FDR校正
fdr_p <- p.adjust(pvalues, method = "fdr")
# 用maFDR函数实现FDR校正
library(qvalue)
qobj <- qvalue(p = pvalues)
ma_fdr_p <- qobj$qvalues
# 对比矫正前和矫正后的p值
summary(pvalues) #矫正前p值区间
summary(fdr_p) #BH矫正后p值区间
summary(ma_fdr_p) #maFDR矫正后p值区间
# 检查矫正前和矫正后的p值之间的变化
plot(pvalues, fdr_p, pch = 20, xlab = 'P-values', ylab = 'Adjusted p-values', col = "red", main = 'BH') #校正前后比较
plot(pvalues, ma_fdr_p, pch = 20, xlab = 'P-values', ylab = 'Adjusted p-values', main = 'MAFDR') #maFDR
如果矫正后的p值反而比矫正前的p值小,建议检查数据处理过程、统计模型选择和代码实现。
如果我的回答解决了您的问题,请采纳!