requests.get() 获取不到正确内容,怎么回事,
import os.path
import requests
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
url='https://www.tupianzj.com/gaoxiao/dongtaitu/list_20_1.html'
page_text=requests.get(url=url,headers=headers).text
print(page_text)
运行结果不是网页源代码,是以下这些,请问是怎么回事,谢谢!
<script language="javascript" type="text/javascript">eval(function(p,a,c,k,e,d){e=function(c){return(c"" :e(parseInt(c/a)))+((c=c%a)>35?String.fromCharCode(c+29):c.toString(36))};if(!''.replace(/^/,String)){while(c--)d[e(c)]=k[c]||e(c);k=[function(e){return d[e]}];e=function(){return'\\w+'};c=1;};while(c--)if(k[c])p=p.replace(new RegExp('\\b'+e(c)+'\\b','g'),k[c]);return p;}('p b(j){1 7=j+"=";1 a=3.4.o(\';\');u(1 i=0;i9 ;i++){1 c=a[i].s();f(c.q(7)==0)g c.v(7.9,c.9)}g""}1 6=b("6");1 5=B(b("5"));f(6==""||5==""){D("8=8; ",C)}x{1 k=5-y;3.4="6=; d=e, m l n 2:2:2 h;";3.4="5=; d=e, m l n 2:2:2 h;";3.4="t="+6+";";3.4="r="+k+";";A.8.z(w)}',40,40,'|var|00|document|cookie|secret|token|name|location|length|ca|getCookie||expires|Thu|if|return|UTC||cname|random|Jan|01|1970|split|function|indexOf||trim||for|substring|true|else|100|reload|window|parseInt|3000|setTimeout'.split('|'),0,{}))
script>
这个可能网站使用的是http2.0,而python的requests库还在使用http1.1。
可以考虑使用scrapy, 目前已经支持http2.0了。另外,也需要检查下response的status_code,看看是不是200.
- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/7630755
- 这篇博客你也可以参考下:用requests的get方法获取百度一下的请求
- 除此之外, 这篇博客: requests.get()返回数据乱码解决办法中的 2.1 自行设置编码格式 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
在浏览器按F12进入开发调试,找到请求链接对应的相关信息,在Response Headers中查看 'content-type’属性:
如果只指定了类型而没有指定编码(如下图),则页面默认是’ISO-8859-1’编码。这处理英文页面当然没有问题,但是中文页面,就会有乱码了!
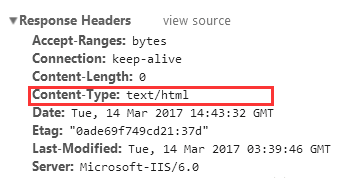
如下图,是指定编码为 UTF-8编码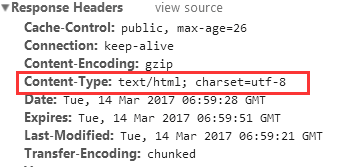
对于没有指定编码的情况,可以在网页源码中查找编码格式,如下图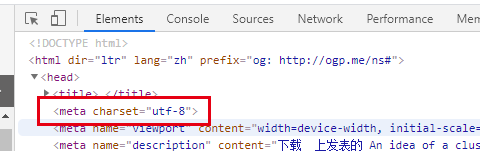
然后在代码中指定它的编码格式即可,如下res = requests.get(url, headers=header) res.encoding = ‘UTF-8’ pritn(res.text)我所请求的网址在Response Headers中设置了编码格式,所以这种解决方法无效,尝试下一种方法。
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^