python编程求帮助修改~
r=input()
z=eval(input())
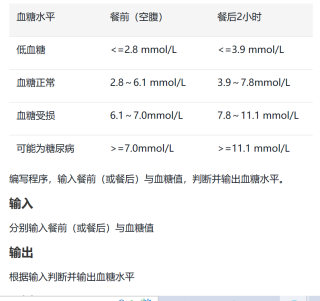
if r in ['餐前']:
if 'z'<=2.8:
print("低血糖")
if 2.8<'z'<6.1:
print("血糖正常")
if 6.1<'z'<7.0:
print("血糖受损")
if 'z'>=7.0:
print("可能为糖尿病")
if r in ['餐后']:
if 'z'<=3.9:
print('低血糖')
if 3.9<'z'<7.8:
print('血糖正常')
if 7.8<'z'<11.1:
print('血糖受损')
if 'z'>=11.1:
print('可能为糖尿病')
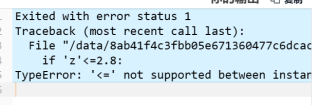
运行时平台报错,求帮助修改
把 'z' 两边的引号去掉
你是要判断的 z 这个变量,加上引号就变成 z 这个字符了
- 你可以参考下这个问题的回答, 看看是否对你有帮助, 链接: https://ask.csdn.net/questions/7512089
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:Python多线程和多进程运行程序,并获得函数返回值
- 同时,你还可以查看手册:python- 走向编程的第一步 中的内容
- 除此之外, 这篇博客: python某鱼主播粉丝的爬取中的 解析字体库,找到对应关系 部分也许能够解决你的问题, 你可以仔细阅读以下内容或跳转源博客中阅读:
把每次获取到的字体库链接直接通过requests下载下来,保存为woff格式。然后转成lxml格式。打开lxml,很清楚的能看见里面对应的关系。然后通过python解析lxml对数据进行解析,获取到对应的映射关系即可。
附上解析字体的代码:import requests from fontTools.ttLib import TTFont from xml.dom.minidom import parse headers = { 'user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36', } def get_number_dict(keyword): number_dict = { 'zero': 0, 'seven': 7, 'three': 3, 'four': 4, 'eight': 8, 'six': 6, 'five': 5, 'nine': 9, 'one': 1, 'two': 2, } dom = parse("lxml路径") # dom = parse("/Users/zhulang/Desktop/nanodata_crawling/apps/douyu/woff/%s.xml" % str(keyword)) data = dom.documentElement stus = data.getElementsByTagName('GlyphID') font_dict = {} corr_number = [] error_number = [] for stu in stus: corr_number.append(stu.getAttribute('id')) if stu.getAttribute('name') != '.notdef': error_number.append(number_dict[stu.getAttribute('name')]) else: pass corr_number = corr_number[:-1] for index in range(len(corr_number)): font_dict[error_number[index]] = corr_number[index] return font_dict def download_font(keyword): url = 'https://shark.douyucdn.cn/app/douyu/res/font/%s.woff' % str(keyword) res = requests.get(url, headers=headers) with open("woff字体路径", 'wb') as f: f.write(res.content) base_font = TTFont("woff字体路径" ) base_font.saveXML("lxml路径") number_dict = get_number_dict(keyword) return number_dict- 您还可以看一下 黄棒清老师的Python实战量化交易理财系统课程中的 基于策略,寻找最优周期对小节, 巩固相关知识点