TensorFlow1.14训练时出错
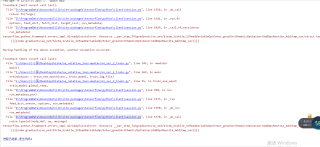
最近在学习深度学习方面的知识,在训练网络时出现了这个错误,搜不到解决方案,像这种错误怎么解决呀?
根据错误提示可以看出是在训练过程中出现了AlreadyExistsError错误,可能是由于在代码中重复定义了某些资源。建议检查一下代码中是否有重复定义某些变量或操作的情况。也可以尝试在训练之前,通过调用tf.reset_default_graph()清除默认计算图,然后重新构建计算图来解决该问题。此外,还可以尝试升级TensorFlow版本或者尝试在其他机器上运行该代码。
针对深度学习训练时出现的错误,一般可以从以下几个方面来排查和解决:
1.查看错误提示信息:根据错误提示信息,可以了解到错误所在的文件和行号,以及错误的类型和信息,通过这些信息可以确定问题的大致范围。
2.查看训练代码:对照错误提示信息和训练代码,检查可能存在问题的代码段,看看是否有错误或者不合适的地方。
3.检查输入数据:检查训练数据的格式、大小、维度等信息,是否与网络模型的输入要求一致,是否存在缺失值或异常值等问题。
4.调整网络参数:调整网络的学习率、批大小、迭代次数、网络结构等参数,看看是否可以减少错误的出现。
5.检查硬件环境:检查训练所使用的硬件环境,如GPU、内存、硬盘等是否存在问题,是否有足够的空间存储模型参数。
6.查看其他日志信息:深度学习训练过程中,通常会生成一些日志信息,包括训练损失、准确率等指标的变化情况,可以通过这些日志信息了解训练过程中的变化情况,有助于定位问题所在。
根据错误类型的不同,还可以进一步采取相应的解决方案,比如对于常见的梯度消失或梯度爆炸等问题,可以尝试使用梯度裁剪或者其他优化算法;对于模型过拟合或欠拟合等问题,可以考虑增加或减少模型参数,使用正则化技术等方式。
不知道你这个问题是否已经解决, 如果还没有解决的话:- 这有个类似的问题, 你可以参考下: https://ask.csdn.net/questions/7606226
- 我还给你找了一篇非常好的博客,你可以看看是否有帮助,链接:TensorFlow学习2:使用自己的数据批量训练网络
- 除此之外, 这篇博客: Tensorflow2.0学习笔记(一)北大曹健老师教学视频1-4讲中的 第一讲 常用函数的使用(包含了很多琐碎的函数,还有第二讲的部分) 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
这里把视频中的给的常用的函数都罗列出来了,我也刚学,以后就没事看这个复习熟悉吧
import tensorflow as tf import numpy as np from sklearn.datasets import load_iris ##################################################################### import osdd # 1.3张量生成 ''' Tensor:多维数组 阶:张量的维数 数字左边的[ 有几个就是几阶 0-D 0阶 标量 s=1 2 3 1-D 1阶 向量 v=[1,2,3] 2-D 2阶 矩阵 m = [[1,2,3],[4,5,6],[7,8,9]] 数据类型 tf.int 32,tf.float 32,tf.float 64 tf.bool tf.constan([True,False]) tf.string ''' a = tf.constant([1,5],dtype=tf.int64) # 张量内容,dtype=数据类型 # numpy的数据类型转换为Tensor数据类型 a = np.arange(0,5) b = tf.convert_to_tensor(a,dtype=tf.int64) #数据名,dtype= # 特殊创建方法 dim = 5 # dim为维度 c = tf.zeros(dim) # 创建全为0 d = tf.ones(dim) # 创建维度为dim的全为1的张量 e = tf.fill(dim,4) # 创建维度为dim的全为指定数目(这里为4)的张量 f = tf.random.normal(dim,mean=2,stddev=1) # 生成dim维,均值为2,标准差为1的整天分布随机数 g = tf.random.truncated_normal(dim,mean=2,stddev=1) # 生成截断式正态分布随机数,该函数保证生成数据在(±均值-2*标准差之外)就重新生成,保证生成值在均值附近 h = tf.random.uniform(dim,minval=0,maxval=1) # 生成均匀分布的随机数 ##################################################################### # 1.4常用函数 a = tf.constant([1.,2.,3.],dtype=tf.float64) print(a) a1 = tf.cast(a,tf.int32) # 强制tensor转换为该数据类型 print(a1) a2 = tf.reduce_max(a1) # 计算张量维度上元素的最大值 a3 = tf.reduce_min(a1) # 计算张量维度上元素的最小值 # 取平均值 # axis ,在二维张量或数组中,axis=0表示跨行,axis=1表示跨列 a4 = tf.reduce_mean(a1,axis=0) a5 = tf.reduce_mean(a1) a6 = tf.reduce_sum(a1,axis=0) a7 = tf.reduce_sum(a1) # 把内部初始化变量标记为可训练,被标记的变量会再反向传播中记录梯度信息,神经网络训练中, # 常用该函数标记待训练参数 w = tf.Variable(a1) ###################################################### #TensorFlow中的数学运算 ''' tf.add tf.subtract tf.multiply tf.divide 为对应元素的四则运算 tf.square tf.pow tf.sqrt 为平方 次方 开发操作 矩阵乘 tf.matmul 要保证俩个操作的维度相同 ''' a = tf.ones([1,3]) b = tf.fill([1,3],3.) print(a) print(b) print(tf.add(a,b)) print(tf.subtract(a,b)) print(tf.multiply(a,b)) print(tf.divide(b,a)) print(tf.fill([1,2],3.)) print(tf.pow(a,3)) print(tf.square(a)) print(tf.sqrt(a)) a = tf.ones([3,2]) b = tf.fill([2,3],3.) print(tf.matmul(a,b)) ######################################### # 吧标签和特征配对的函数 train_data = tf.constant([12,23,10,17]) train_label = tf.constant([0,1,1,0]) # 下面的函数就是把元组形式输入的特征,标签配对,对numpy或tensor格式都适用 data = tf.data.Dataset.from_tensor_slices((train_data,train_label)) ######################################################## # 1.5 常用函数 ''' 这个函数来记录计算过程 with tf.GradientTape() as tape: 若干个计算过程 grad = tape.gradient(函数,对谁求导) ''' with tf.GradientTape() as tape: w = tf.Variable(tf.constant(3.0)) loss = tf.pow(w,2) grad = tape.gradient(loss,w) print(grad) # python内建函数enumerate 可以遍历每个元素,组合为 索引 元素 seq = ['one','two','three'] for i,element in enumerate(seq): print(i,element) # 独热编码 常用这个做标签 1表是,0表非, classes = 3 # 结果为3类 labels = tf.constant([1,0,2]) # 输入的元素最小0,最大为2 output = tf.one_hot(labels,depth=classes) print(output) # tf.nn.softmax函数,如命,就是吧n分类的n个输出通过softmax符合概率分布 y = tf.constant([1.01,2.01,-0.66]) y_pro = tf.nn.softmax(y) print("After softmax,y_pro is ",y_pro) # assign_sub 赋值操作,更新参数的值并返回;更新前先定义变量为可训练 w = tf.Variable(4) w.assign_sub(1) # 相当于w = w-1 print(w) # tf.armax 返回张量沿指定维度最大值的索引 test = np.array([[1,2,3],[4,5,6],[7,8,9]]) print(test) # 分别返回每列、行最大值的索引 若不指定就返回全部的最大值的索引 print(tf.argmax(test,axis=0)) print(tf.argmax(test,axis=1)) ######################################################### # 2.1 预备知识 # tf.where(条件语句,真返回A,假返回B) a = tf.constant([1,2,3,1,1]) b = tf.constant([0,1,3,4,5]) c = tf.where(tf.greater(a,b),a,b) # 若a>b 返回a对应位置的元素,不然返回b对应位置 元素 print("c:",c) # np.random.RandomState.rand() 返回一个[0,1)之间的随机数 rdm = np.random.RandomState(seed=1) # seed=常数每次生成随机数相同 a = ram.rand() # 返回一个随机标量 b = rdm.rand(2,3) # 返回维度为2行3列随机数矩阵 print("a:",a) print("b:",b) # np.vstack() 将俩个数组按垂直方向叠加 a = np.array([1,2,3]) b = np.array([4,5,6]) c = np.vstack((a,b)) print("c:\n",c) ''' np.mgrid[] .ravel() .c_[] 总在一起使用,去生成网格 # np.mgrid[起始值:结束值:步长,起始值:结束值:步长,。。。] x.ravel() 吧x变为一维数组,把。前变量拉直 np.c_[]使返回的间隔数值点配对 np.c_[数组1,数组2....] ''' x,y = np.mgrid[1:3:1,2:4:0.5] grid = np.c_[x.ravel(),y.ravel()] print("x:",x) print("y:",y) print('grid:\n',grid) - 您还可以看一下 王而川老师的TensorFlow实战演练--泰坦尼克号视频教学课程中的 模型加载与训练小节, 巩固相关知识点
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^